INTRODUCTION………………………………………………………………………………………….. 3 Setting Up AI Development Environment with Python……………………………….… 7 Understanding Machine Learning — The Heart of AI…………………………………… 11 Supervised Learning Deep Dive — Regression and Classification Models………. 16 Unsupervised Learning Deep Dive — Discovering Hidden Patterns………………. 21 Neural Networks Fundamentals — Building Brains for AI ……………………………. 26 Project — Build a Neural Network to Classify Handwritten Digits ………………. 30 Deep Learning for Image Classification — CNNs Explained………………………… 33 Advanced Image Classification — Transfer Learning………………………………….. 37 Natural Language Processing (NLP) Basics with Python…………………………….. 41 Spam Detection Using Machine Learning …………………………………………………. 45 Deep Learning for Text Classification (with NLP) …………………………………….. 48 Computer Vision Basics and Image Classification ……………………………………. 51 AI for Automation: Files, Web, and Emails ………………………………………………. 56 AI Chatbots and Virtual Assistants …………………………………………………………… 61
→ Midjourney: for the stunning visuals and style. → Nano Banana: for camera angles and edits. → Seedance + Kling 2.5: for motion and animation. → Suno: for the music track in one go. → Elevenlabs: for sound effects.
I created a million-dollar Pixar-quality short in just 8 days using AI.
Recent video generation models can produce smooth and visually appealing clips, but they often struggle to synthesize complex dynamics with a coherent chain of consequences. Accurately modeling visual outcomes and state transitions over time remains a core challenge. In contrast, large language and multimodal models (e.g., GPT-4o) exhibit strong visual state reasoning and future prediction capabilities. To bridge these strengths, we introduce VChain, a novel inference-time chain-of-visual-thought framework that injects visual reasoning signals from multimodal models into video generation. Specifically, VChain contains a dedicated pipeline that leverages large multimodal models to generate a sparse set of critical keyframes as snapshots, which are then used to guide the sparse inference-time tuning of a pre-trained video generator only at these key moments. Our approach is tuning-efficient, introduces minimal overhead and avoids dense supervision. Extensive experiments on complex, multi-step scenarios show that VChain significantly enhances the quality of generated videos.
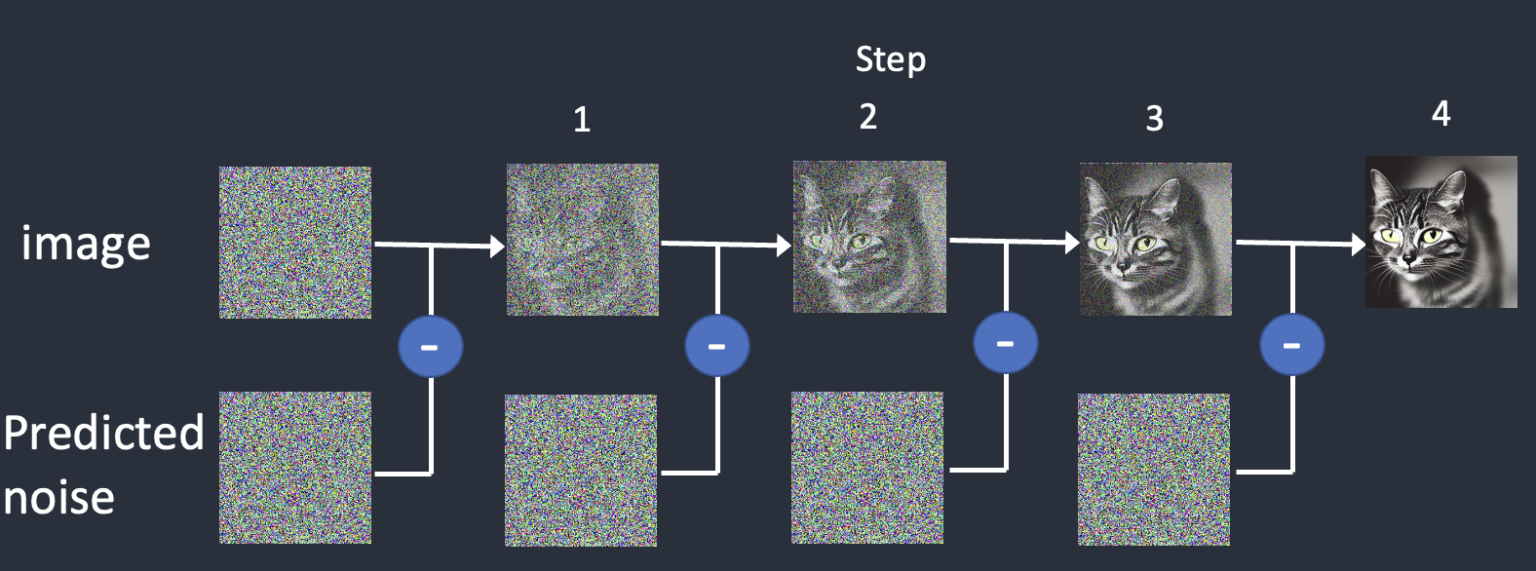
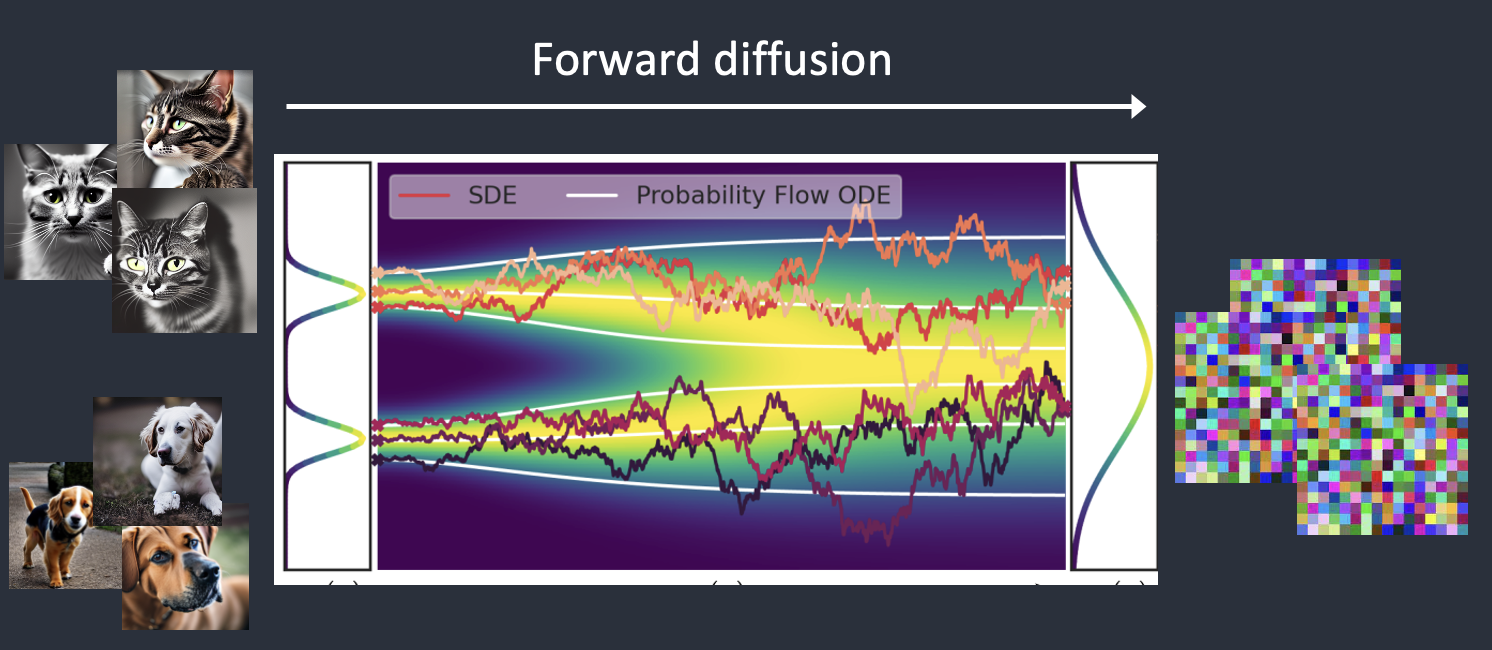
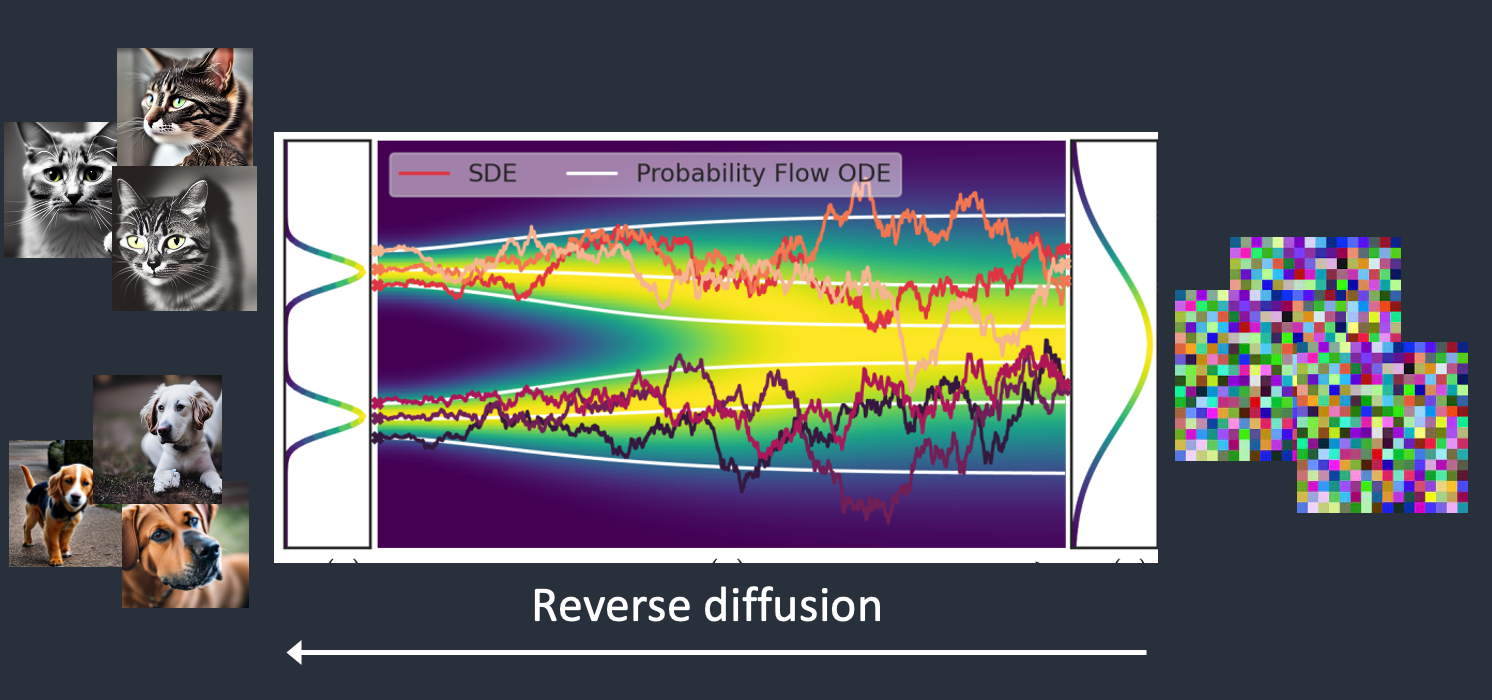
Stable Diffusion is a latent diffusion model that generates AI images from text. Instead of operating in the high-dimensional image space, it first compresses the image into the latent space.
Stable Diffusion belongs to a class of deep learning models called diffusion models. They are generative models, meaning they are designed to generate new data similar to what they have seen in training. In the case of Stable Diffusion, the data are images.
Why is it called the diffusion model? Because its math looks very much like diffusion in physics. Let’s go through the idea.
“If you produce YouTube content or do any work with intellectual property or copyrighted material, then a thorough understanding of fair use copyright law may be absolutely vital.”
“Fair Use is a branch of copyright law relating to the reuse and reproduction of copyrighted material.”