This demo is created for coders who are familiar with this awesome creative coding platform. You may quickly modify the code to work for video or to stipple your own Procssing drawings by turning them into PImage and run the simulation. This demo code also serves as a reference implementation of my article Blue noise sampling using an N-body simulation-based method. If you are interested in 2.5D, you may mod the code to achieve what I discussed in this artist friendly article.
🔹 Code Readability & Simplicity – Use meaningful names, write short functions, follow SRP, flatten logic, and remove dead code. → Clarity is a feature.
🔹 Function & Class Design – Limit parameters, favor pure functions, small classes, and composition over inheritance. → Structure drives scalability.
🔹 Testing & Maintainability – Write readable unit tests, avoid over-mocking, test edge cases, and refactor with confidence. → Test what matters.
🔹 Code Structure & Architecture – Organize by features, minimize global state, avoid god objects, and abstract smartly. → Architecture isn’t just backend.
🔹 Refactoring & Iteration – Apply the Boy Scout Rule, DRY, KISS, and YAGNI principles regularly. → Refactor like it’s part of development.
I ran Steamboat Willie (now public domain) through Flux Kontext to reimagine it as a 3D-style animated piece. Instead of going the polished route with something like W.A.N. 2.1 for full image-to-video generation, I leaned into the raw, handmade vibe that comes from converting each frame individually. It gave it a kind of stop-motion texture, imperfect, a bit wobbly, but full of character.
Our human-centric dense prediction model delivers high-quality, detailed (depth) results while achieving remarkable efficiency, running orders of magnitude faster than competing methods, with inference speeds as low as 21 milliseconds per frame (the large multi-task model on an NVIDIA A100). It reliably captures a wide range of human characteristics under diverse lighting conditions, preserving fine-grained details such as hair strands and subtle facial features. This demonstrates the model’s robustness and accuracy in complex, real-world scenarios.
The state of the art in human-centric computer vision achieves high accuracy and robustness across a diverse range of tasks. The most effective models in this domain have billions of parameters, thus requiring extremely large datasets, expensive training regimes, and compute-intensive inference. In this paper, we demonstrate that it is possible to train models on much smaller but high-fidelity synthetic datasets, with no loss in accuracy and higher efficiency. Using synthetic training data provides us with excellent levels of detail and perfect labels, while providing strong guarantees for data provenance, usage rights, and user consent. Procedural data synthesis also provides us with explicit control on data diversity, that we can use to address unfairness in the models we train. Extensive quantitative assessment on real input images demonstrates accuracy of our models on three dense prediction tasks: depth estimation, surface normal estimation, and soft foreground segmentation. Our models require only a fraction of the cost of training and inference when compared with foundational models of similar accuracy.
QuickTime (.mov) files are fundamentally time-based, not frame-based, and so don’t have a built-in, uniform “first frame/last frame” field you can set as numeric frame IDs. Instead, tools like Shotgun Create rely on the timecode track and the movie’s duration to infer frame numbers. If you want Shotgun to pick up a non-default frame range (e.g. start at 1001, end at 1064), you must bake in an SMPTE timecode that corresponds to your desired start frame, and ensure the movie’s duration matches your clip length.
How Shotgun Reads Frame Ranges
Default start frame is 1. If no timecode metadata is present, Shotgun assumes the movie begins at frame 1.
Timecode ⇒ frame number. Shotgun Create “honors the timecodes of media sources,” mapping the embedded TC to frame IDs. For example, a 24 fps QuickTime tagged with a start timecode of 00:00:41:17 will be interpreted as beginning on frame 1001 (1001 ÷ 24 fps ≈ 41.71 s).
Embedding a Start Timecode
QuickTime uses a tmcd (timecode) track. You can bake in an SMPTE track via FFmpeg’s -timecode flag or via Compressor/encoder settings:
Compute your start TC.
Desired start frame = 1001
Frame 1001 at 24 fps ⇒ 1001 ÷ 24 ≈ 41.708 s ⇒ TC 00:00:41:17
Aider enables developers to interactively generate, modify, and test code by leveraging both cloud-hosted and local LLMs directly from the terminal or within an IDE. Key capabilities include comprehensive codebase mapping, support for over 100 programming languages, automated git commit messages, voice-to-code interactions, and built-in linting and testing workflows. Installation is straightforward via pip or uv, and while the tool itself has no licensing cost, actual usage costs stem from the underlying LLM APIs, which are billed separately by providers like OpenAI or Anthropic.
Key Features
Cloud & Local LLM Support Connect to most major LLM providers out of the box, or run models locally for privacy and cost control aider.chat.
Codebase Mapping Automatically indexes all project files so that even large repositories can be edited contextually aider.chat.
100+ Language Support Works with Python, JavaScript, Rust, Ruby, Go, C++, PHP, HTML, CSS, and dozens more aider.chat.
Git Integration Generates sensible commit messages and automates diffs/undo operations through familiar git tooling aider.chat.
Voice-to-Code Speak commands to Aider to request features, tests, or fixes without typing aider.chat.
Images & Web Pages Attach screenshots, diagrams, or documentation URLs to provide visual context for edits aider.chat.
Linting & Testing Runs lint and test suites automatically after each change, and can fix issues it detects
Sourcetree and GitHub Desktop are both free, GUI-based Git clients aimed at simplifying version control for developers. While they share the same core purpose—making Git more accessible—they differ in features, UI design, integration options, and target audiences.
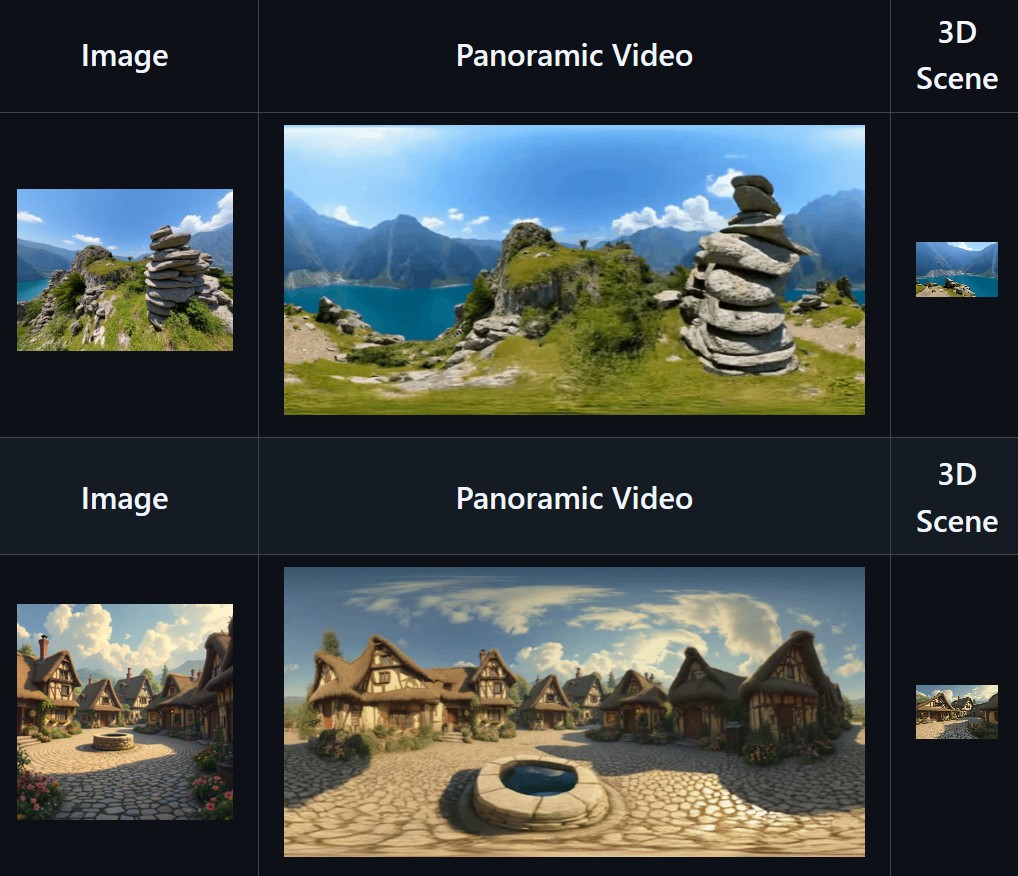
Matrix-3D utilizes panoramic representation for wide-coverage omnidirectional explorable 3D world generation that combines conditional video generation and panoramic 3D reconstruction.
Large-Scale Scene Generation : Compared to existing scene generation approaches, Matrix-3D supports the generation of broader, more expansive scenes that allow for complete 360-degree free exploration.
High Controllability : Matrix-3D supports both text and image inputs, with customizable trajectories and infinite extensibility.
Strong Generalization Capability : Built upon self-developed 3D data and video model priors, Matrix-3D enables the generation of diverse and high-quality 3D scenes.
Speed-Quality Balance: Two types of panoramic 3D reconstruction methods are proposed to achieve rapid and detailed 3D reconstruction respectively.
About 576 megapixels for the entire field of view.
Consider a view in front of you that is 90 degrees by 90 degrees, like looking through an open window at a scene. The number of pixels would be:
90 degrees * 60 arc-minutes/degree * 1/0.3 * 90 * 60 * 1/0.3 = 324,000,000 pixels (324 megapixels).
At any one moment, you actually do not perceive that many pixels, but your eye moves around the scene to see all the detail you want. But the human eye really sees a larger field of view, close to 180 degrees. Let’s be conservative and use 120 degrees for the field of view. Then we would see:
An exposure stop is a unit measurement of Exposure as such it provides a universal linear scale to measure the increase and decrease in light, exposed to the image sensor, due to changes in shutter speed, iso and f-stop.
+-1 stop is a doubling or halving of the amount of light let in when taking a photo
1 EV (exposure value) is just another way to say one stop of exposure change.
Same applies to shutter speed, iso and aperture.
Doubling or halving your shutter speed produces an increase or decrease of 1 stop of exposure.
Doubling or halving your iso speed produces an increase or decrease of 1 stop of exposure.