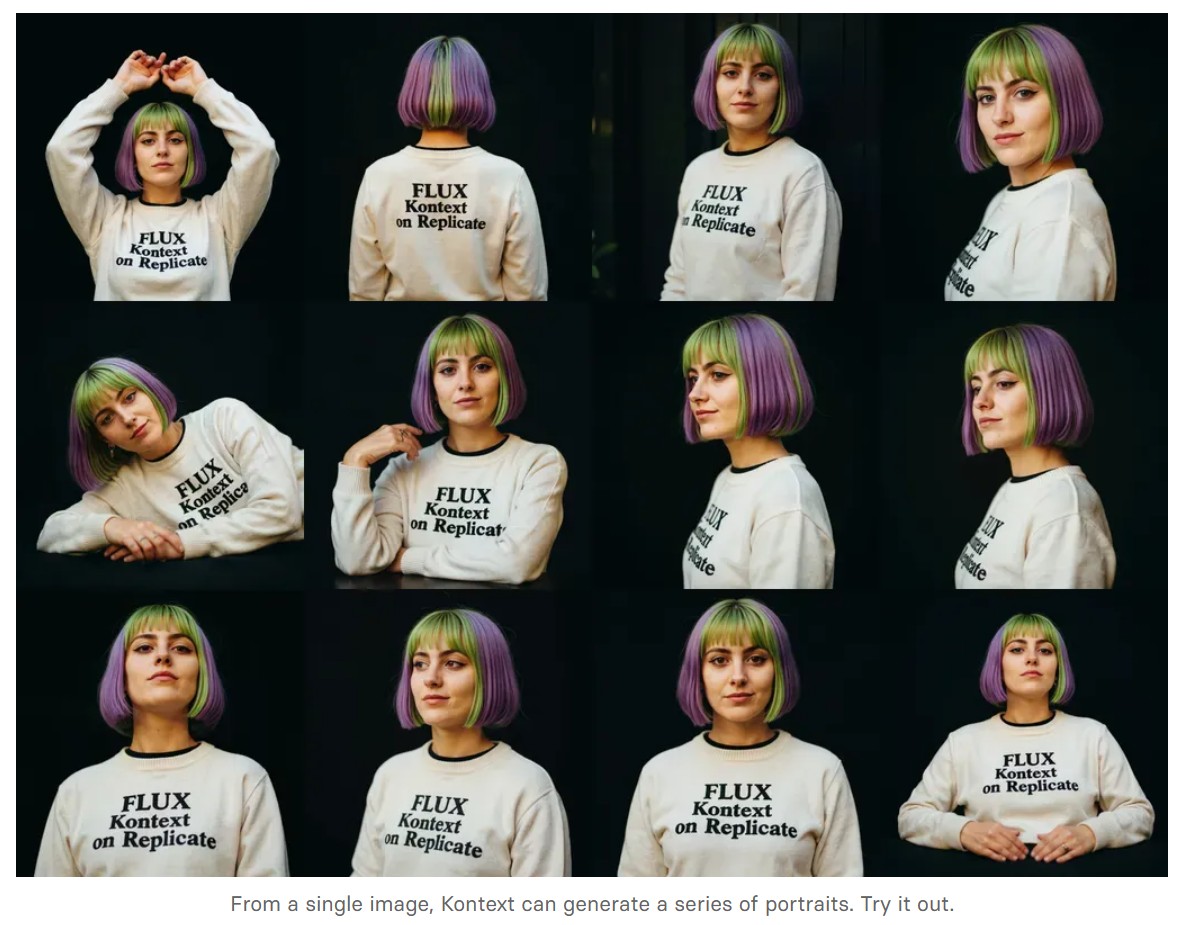BREAKING NEWS
LATEST POSTS
-
Skill Foundry – ARTIFICIAL INTELLIGENCE WITH PYTHON
INTRODUCTION 3
Setting Up AI Development Environment with Python 7
Understanding Machine Learning — The Heart of AI 11
Supervised Learning Deep Dive — Regression and Classification Models 16
Unsupervised Learning Deep Dive — Discovering Hidden Patterns 21
Neural Networks Fundamentals — Building Brains for AI 26
Project — Build a Neural Network to Classify Handwritten Digits 30
Deep Learning for Image Classification — CNNs Explained 33
Advanced Image Classification — Transfer Learning 37
Natural Language Processing (NLP) Basics with Python 41
Spam Detection Using Machine Learning 45
Deep Learning for Text Classification (with NLP) 48
Computer Vision Basics and Image Classification 51
AI for Automation: Files, Web, and Emails 56
AI Chatbots and Virtual Assistants 61 -
Eyeline Labs VChain – Chain-of-Visual-Thought for Reasoning in Video Generation for better AI physics
https://eyeline-labs.github.io/VChain/
https://github.com/Eyeline-Labs/VChain

Recent video generation models can produce smooth and visually appealing clips, but they often struggle to synthesize complex dynamics with a coherent chain of consequences. Accurately modeling visual outcomes and state transitions over time remains a core challenge. In contrast, large language and multimodal models (e.g., GPT-4o) exhibit strong visual state reasoning and future prediction capabilities. To bridge these strengths, we introduce VChain, a novel inference-time chain-of-visual-thought framework that injects visual reasoning signals from multimodal models into video generation. Specifically, VChain contains a dedicated pipeline that leverages large multimodal models to generate a sparse set of critical keyframes as snapshots, which are then used to guide the sparse inference-time tuning of a pre-trained video generator only at these key moments. Our approach is tuning-efficient, introduces minimal overhead and avoids dense supervision. Extensive experiments on complex, multi-step scenarios show that VChain significantly enhances the quality of generated videos.














FEATURED POSTS


-
AI and the Law – studiobinder.com – What is Fair Use: Definition, Policies, Examples and More
https://www.studiobinder.com/blog/what-is-fair-use-definition
“If you produce YouTube content or do any work with intellectual property or copyrighted material, then a thorough understanding of fair use copyright law may be absolutely vital.”
“Fair Use is a branch of copyright law relating to the reuse and reproduction of copyrighted material.”

Fair Use Policy (Determining Factors):
- Purpose and character of use
- Nature of the copyrighted work
- Amount and substantiality of the portion reused
- Effect of the use upon the potential market
-
Black Forest Labs released FLUX.1 Kontext
https://replicate.com/blog/flux-kontext
https://replicate.com/black-forest-labs/flux-kontext-pro
There are three models, two are available now, and a third open-weight version is coming soon:
- FLUX.1 Kontext [pro]: State-of-the-art performance for image editing. High-quality outputs, great prompt following, and consistent results.
- FLUX.1 Kontext [max]: A premium model that brings maximum performance, improved prompt adherence, and high-quality typography generation without compromise on speed.
- Coming soon: FLUX.1 Kontext [dev]: An open-weight, guidance-distilled version of Kontext.
We’re so excited with what Kontext can do, we’ve created a collection of models on Replicate to give you ideas:
- Multi-image kontext: Combine two images into one.
- Portrait series: Generate a series of portraits from a single image
- Change haircut: Change a person’s hair style and color
- Iconic locations: Put yourself in front of famous landmarks
- Professional headshot: Generate a professional headshot from any image