https://github.com/9nate-drake/Comfyui-SecNodes
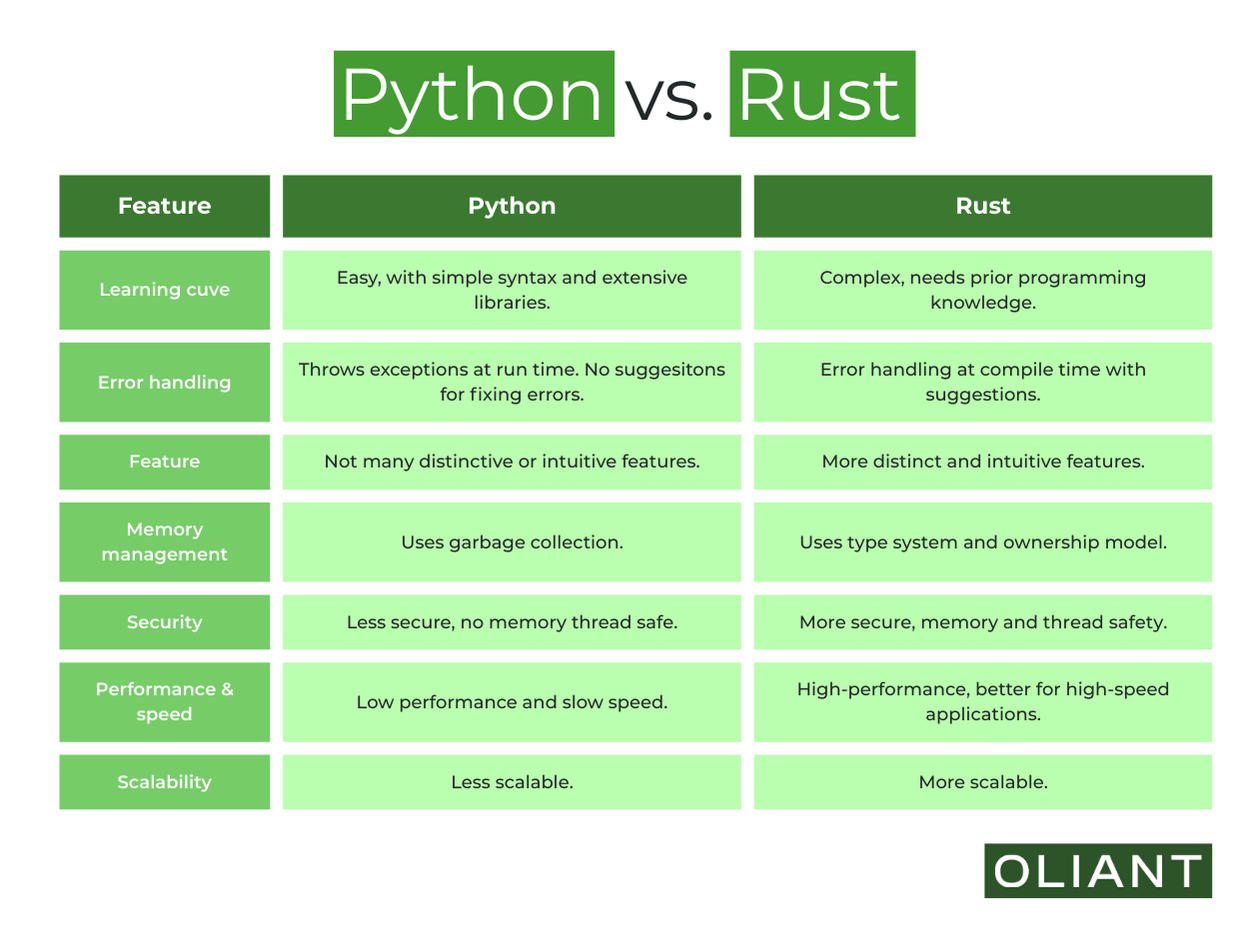
What is SeC?
SeC (Segment Concept) is a breakthrough in video object segmentation that shifts from simple feature matching to high-level conceptual understanding. Unlike SAM 2.1 which relies primarily on visual similarity, SeC uses a Large Vision-Language Model (LVLM) to understand what an object is conceptually, enabling robust tracking through:
- Semantic Understanding: Recognizes objects by concept, not just appearance
- Scene Complexity Adaptation: Automatically balances semantic reasoning vs feature matching
- Superior Robustness: Handles occlusions, appearance changes, and complex scenes better than SAM 2.1
- SOTA Performance: +11.8 points over SAM 2.1 on SeCVOS benchmark
How SeC Works
- Visual Grounding: You provide initial prompts (points/bbox/mask) on one frame
- Concept Extraction: SeC’s LVLM analyzes the object to build a semantic understanding
- Smart Tracking: Dynamically uses both semantic reasoning and visual features
- Keyframe Bank: Maintains diverse views of the object for robust concept understanding
The result? SeC tracks objects more reliably through challenging scenarios like rapid appearance changes, occlusions, and complex multi-object scenes.