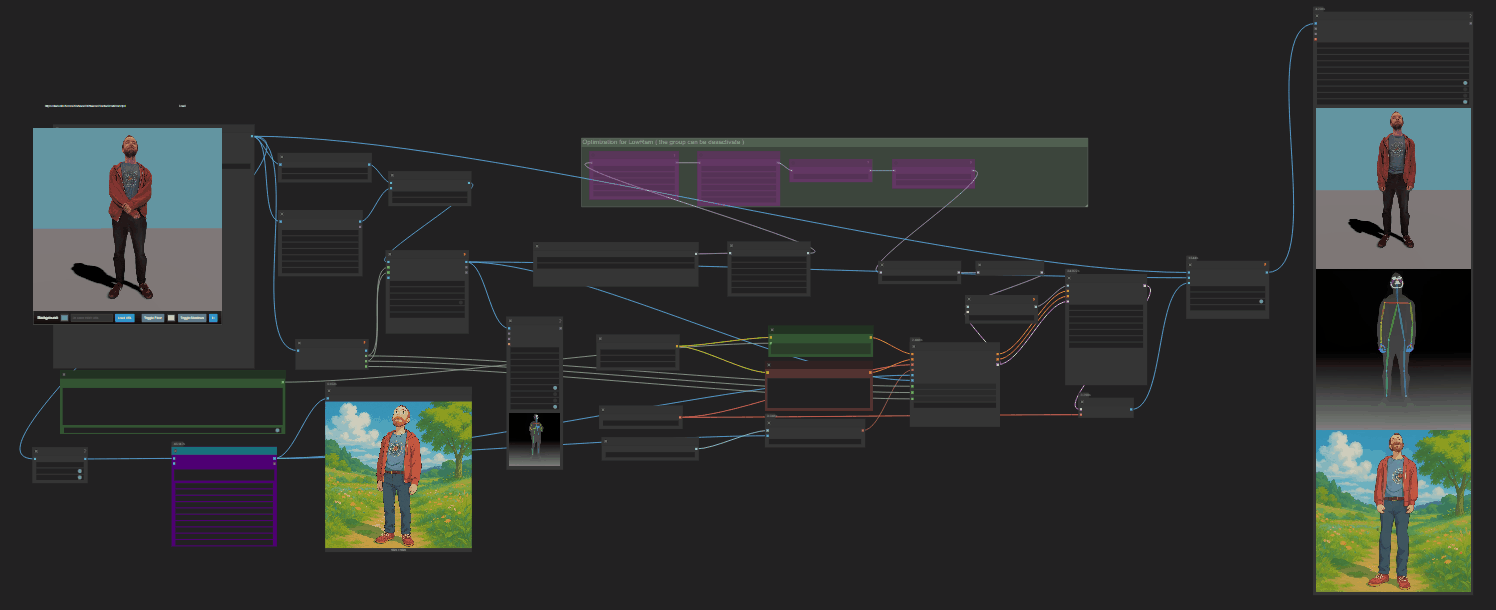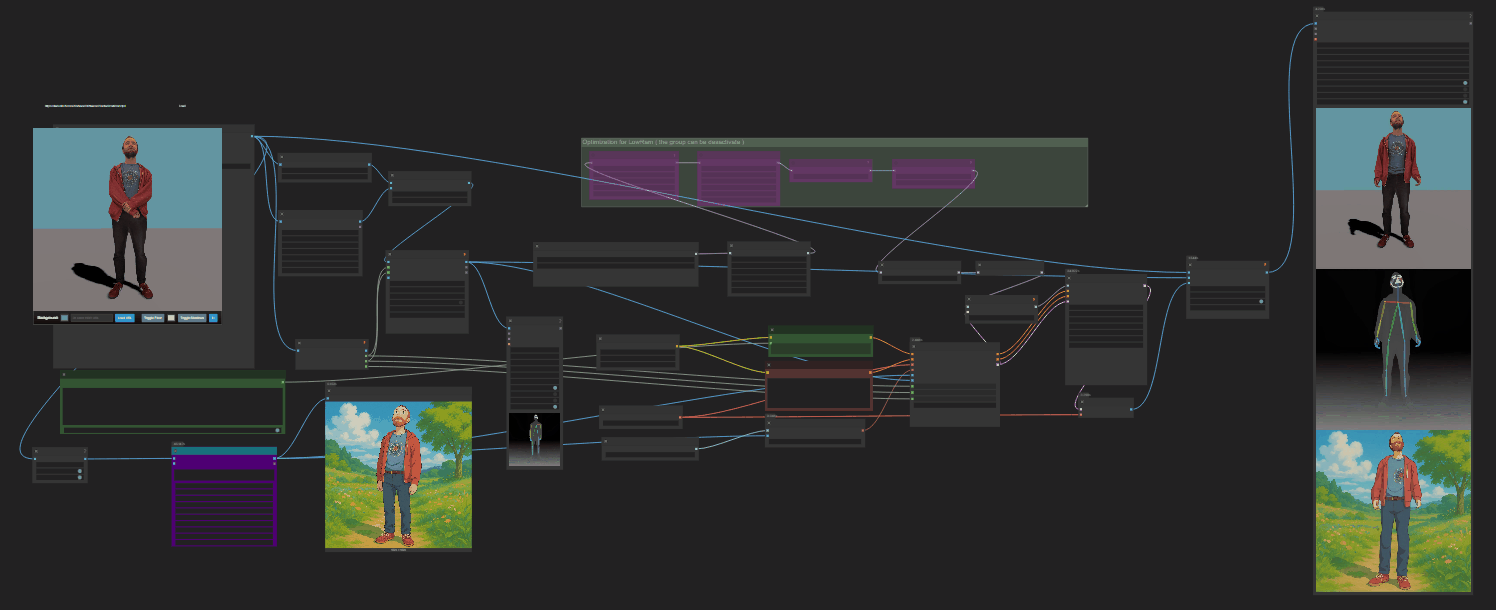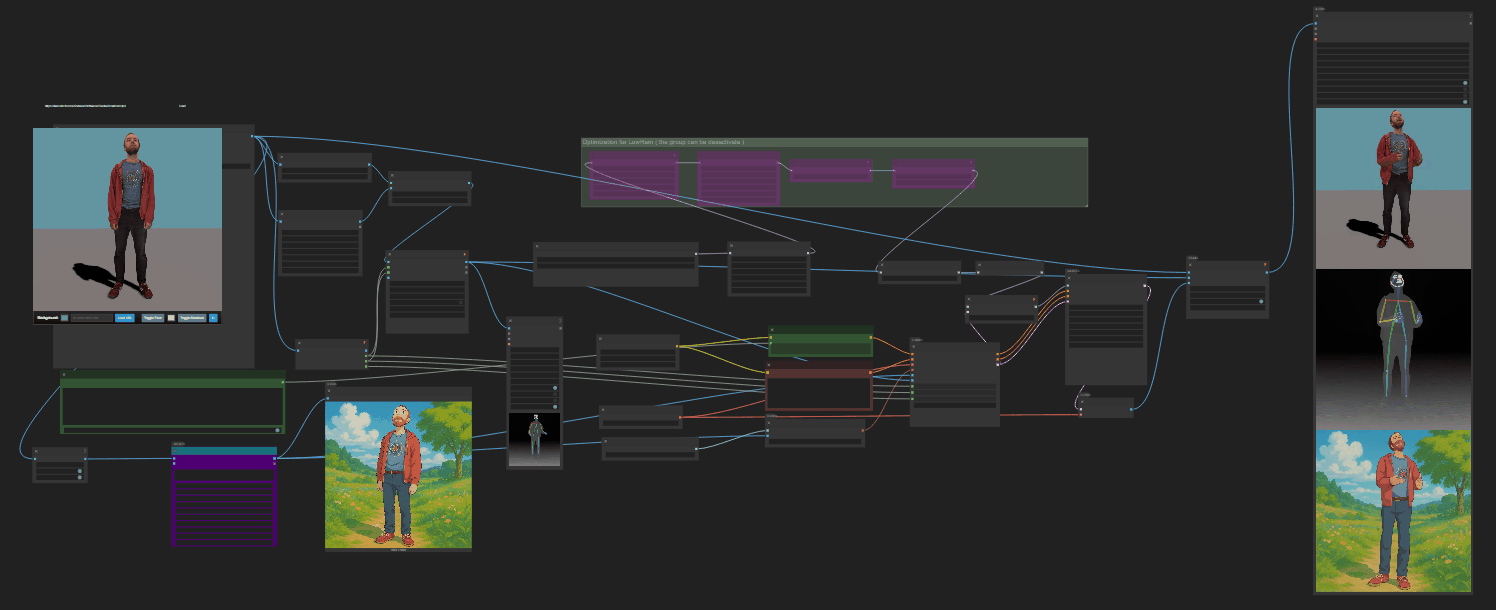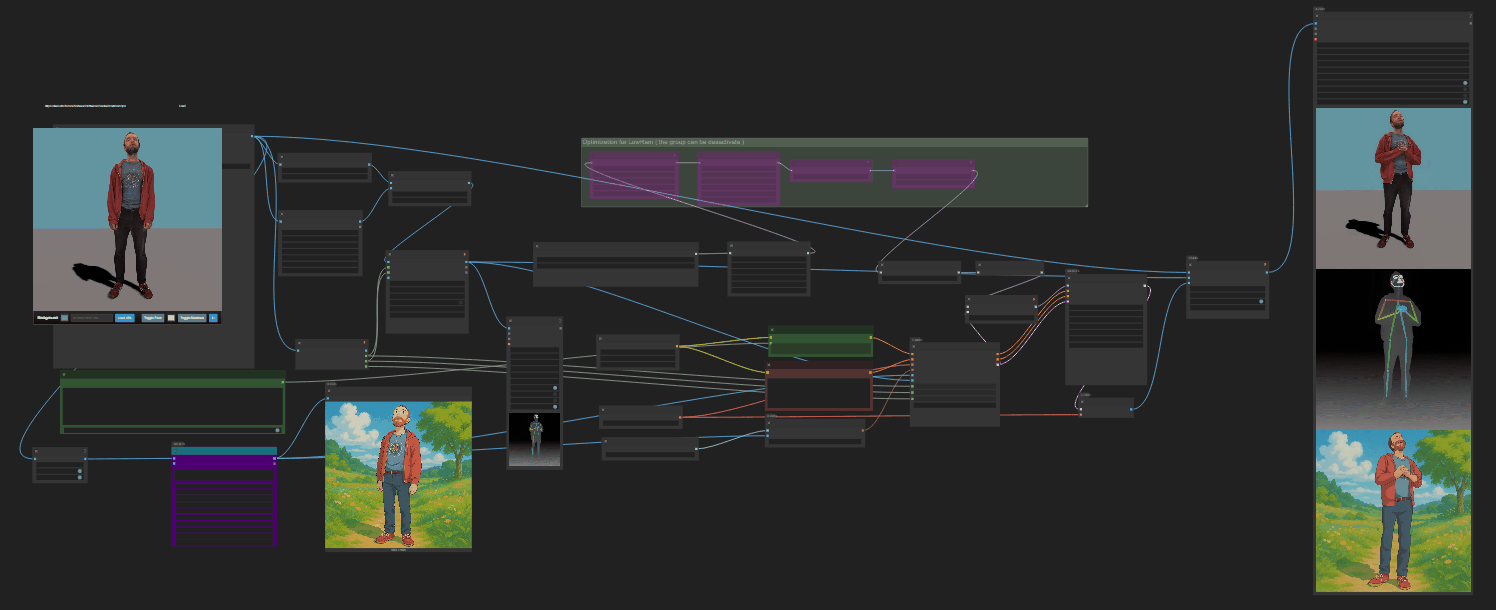
https://www.reddit.com/r/comfyui/comments/1c671l7/next_level_animatediff_outpainting_workflow/
https://drive.google.com/file/d/1wqI1rskIMtbyADZ7i586gx2iqaOYJF6_/view





3Dprinting (178) A.I. (810) animation (343) blender (205) colour (232) commercials (51) composition (152) cool (361) design (641) Featured (71) hardware (311) IOS (109) jokes (137) lighting (287) modeling (143) music (186) photogrammetry (189) photography (754) production (1281) python (90) quotes (495) reference (312) software (1345) trailers (299) ves (547) VR (221)
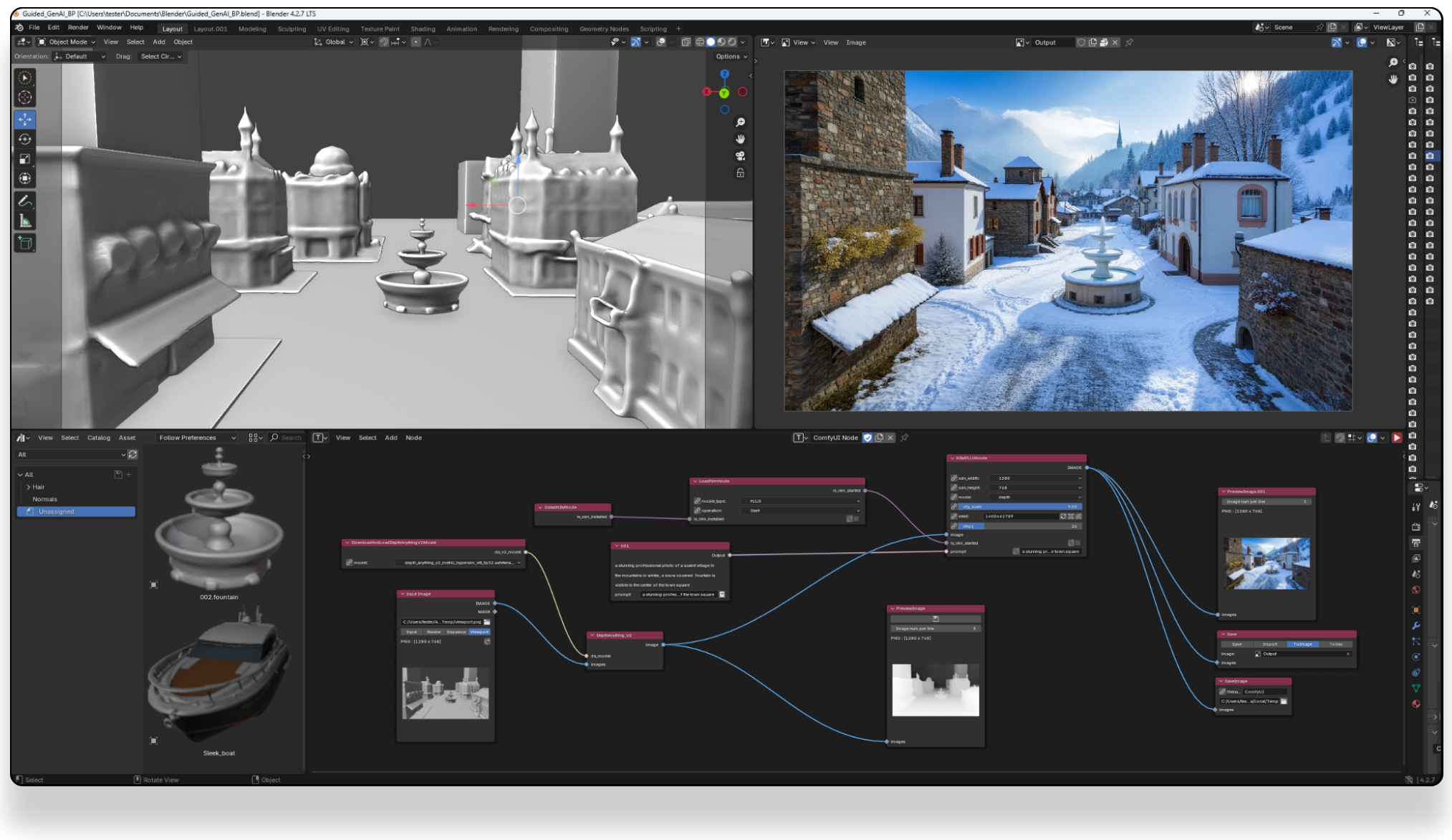
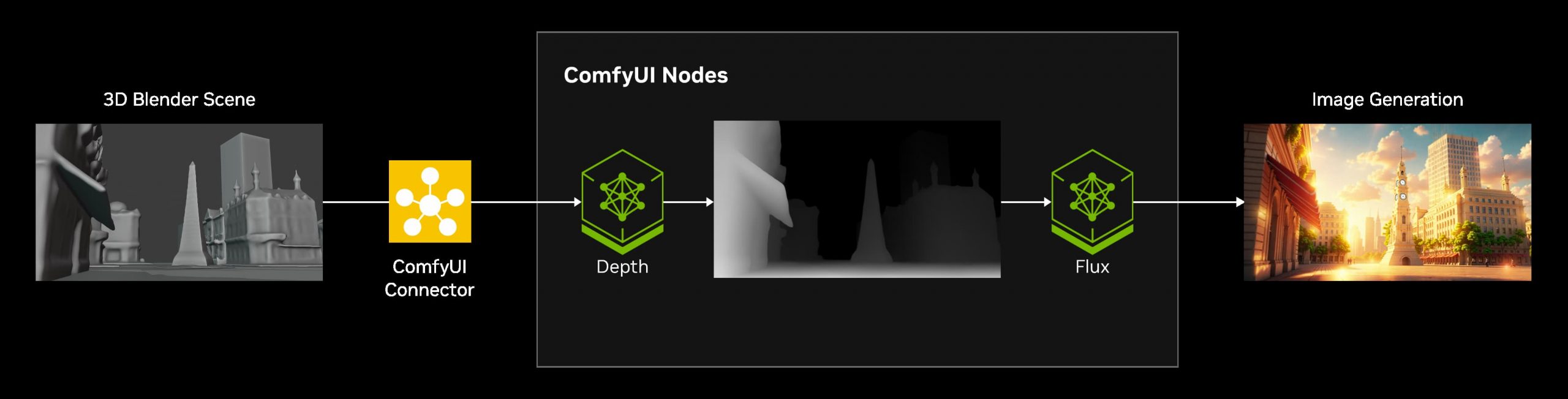
Load holograms, animate cameras, capture frames, and feed them to your favorite AI models. Developed by Lovis Odin for Kartel.ai
You can obtain the MPD URL directly from the official 8i Web Player.
https://github.com/Kartel-ai/ComfyUI-8iPlayer/
https://github.com/nv-tlabs/GEN3C
Load a picture, define a camera path in 3D, and then render a photoreal video.

https://www.axios.com/2025/06/11/disney-nbcu-midjourney-copyright
Why it matters: It’s the first legal action that major Hollywood studios have taken against a generative AI company.
The complaint, filed in a U.S. District Court in central California, accuses Midjourney of both direct and secondary copyright infringement by using the studios’ intellectual property to train their large language model and by displaying AI-generated images of their copyrighted characters.

https://github.com/punitda/ComfyRun
Best suited for individuals who want to
https://stitch.withgoogle.com/
Stitch is available for free of charge with certain usage limits. Each user receives a monthly allowance of 350 generations using Flash mode and 50 generations using Experimental mode. Please note that these limits are subject to change.

https://runwayml.com/news/runway-amc-partnership
Runway and AMC Networks, the international entertainment company known for popular and award-winning titles including MAD MEN, BREAKING BAD, BETTER CALL SAUL, THE WALKING DEAD and ANNE RICE’S INTERVIEW WITH THE VAMPIRE, are partnering to incorporate Runway’s AI models and tools in AMC Networks’ marketing and TV development processes.

https://lumalabs.ai/blog/news/introducing-modify-video
Reimagine any video. Shoot it in post with director-grade control over style, character, and setting. Restyle expressive actions and performances, swap entire worlds, or redesign the frame to your vision.
Shoot once. Shape infinitely.

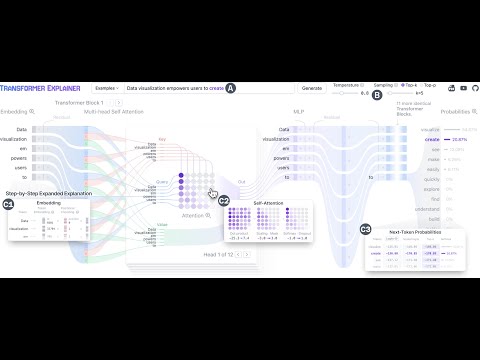
https://github.com/poloclub/transformer-explainer
Transformer Explainer is an interactive visualization tool designed to help anyone learn how Transformer-based models like GPT work. It runs a live GPT-2 model right in your browser, allowing you to experiment with your own text and observe in real time how internal components and operations of the Transformer work together to predict the next tokens. Try Transformer Explainer at http://poloclub.github.io/transformer-explainer
https://www.linkedin.com/posts/upskydown_vr-googleveo-veo3-activity-7334269406396461059-d8Da
If you prompt for a 360° video in VEO (like literally write “360°” ) it can generate a Monoscopic 360 video, then the next step is to inject the right metadata in your file so you can play it as an actual 360 video.
Once it’s saved with the right Metadata, it will be recognized as an actual 360/VR video, meaning you can just play it in VLC and drag your mouse to look around.
https://replicate.com/blog/flux-kontext
https://replicate.com/black-forest-labs/flux-kontext-pro
There are three models, two are available now, and a third open-weight version is coming soon:
We’re so excited with what Kontext can do, we’ve created a collection of models on Replicate to give you ideas:

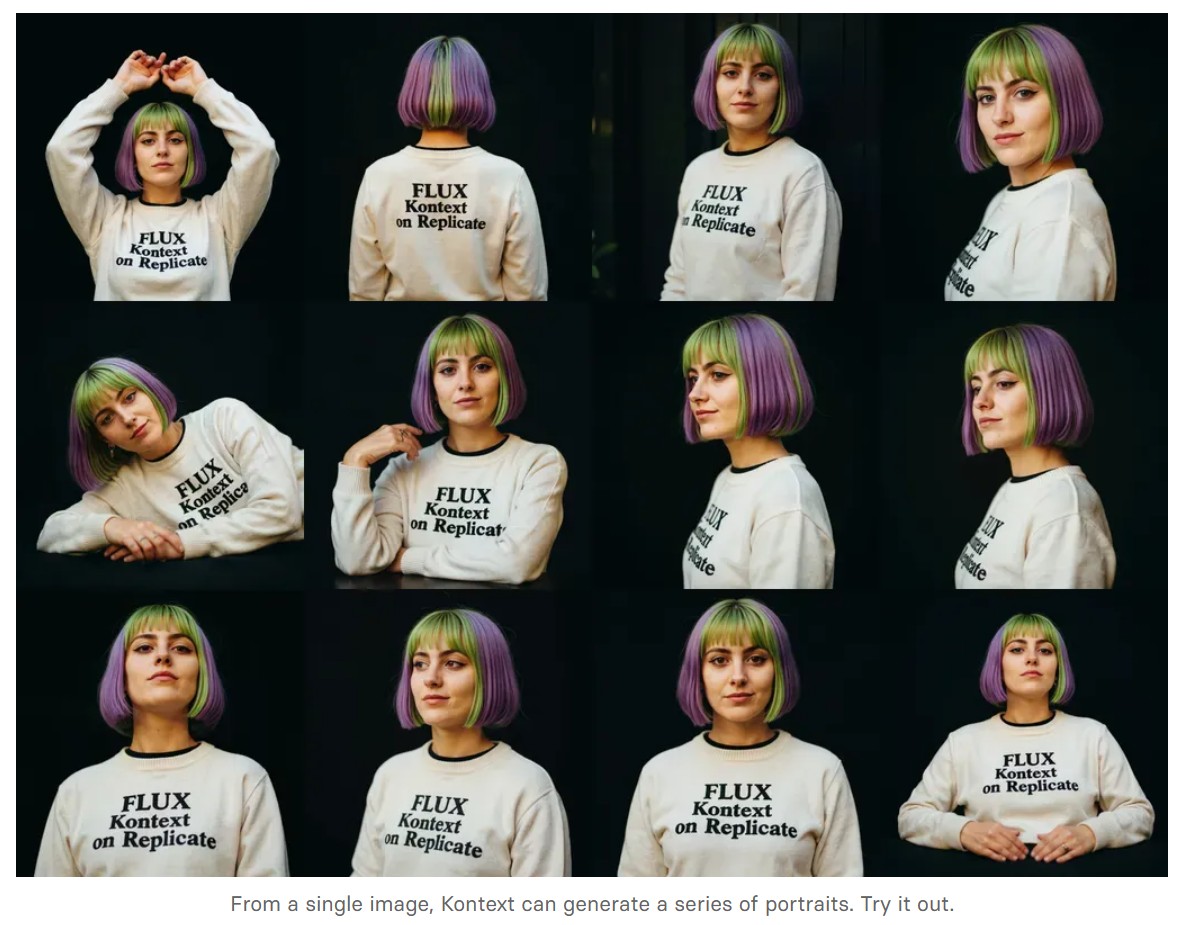
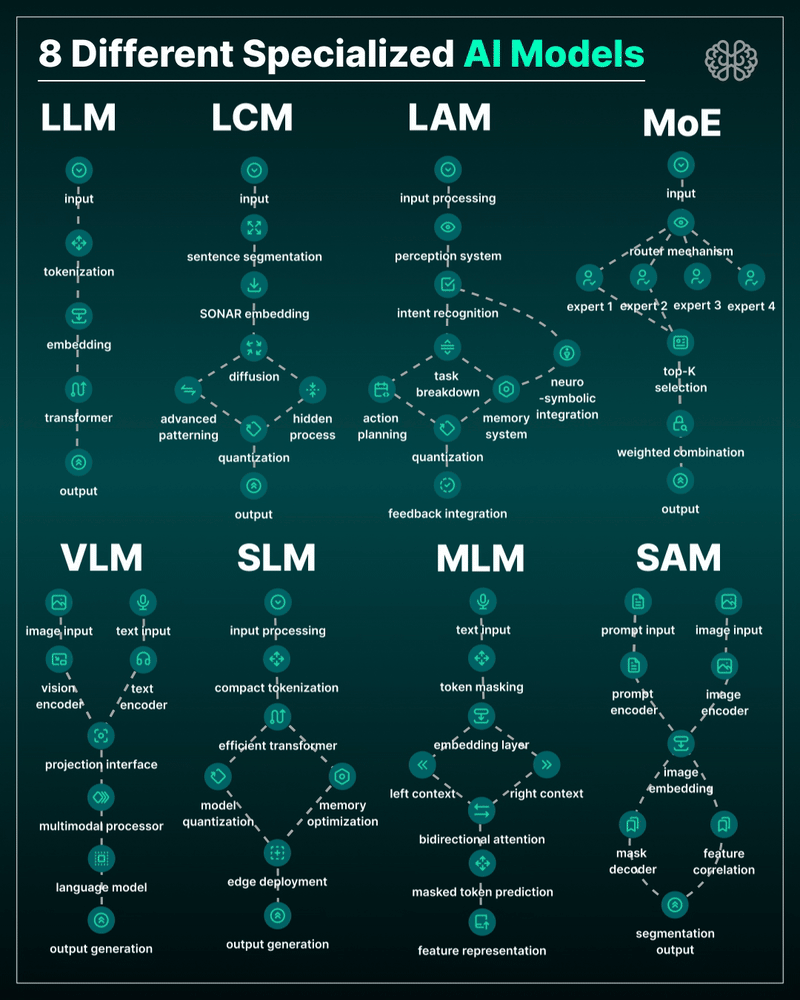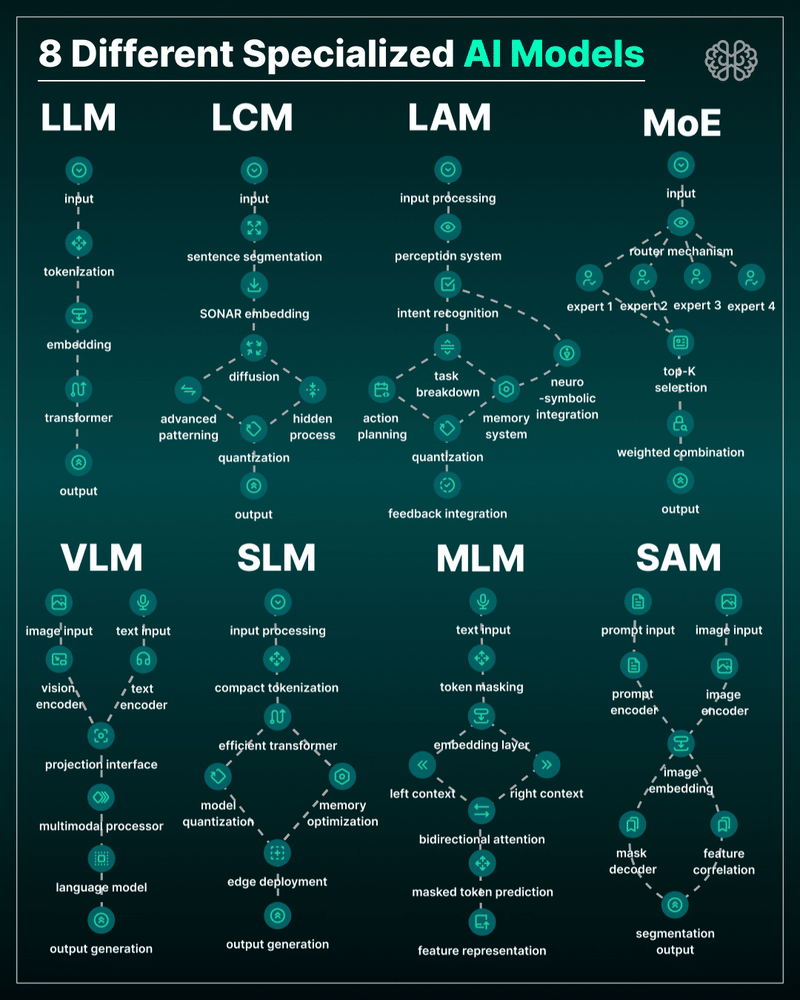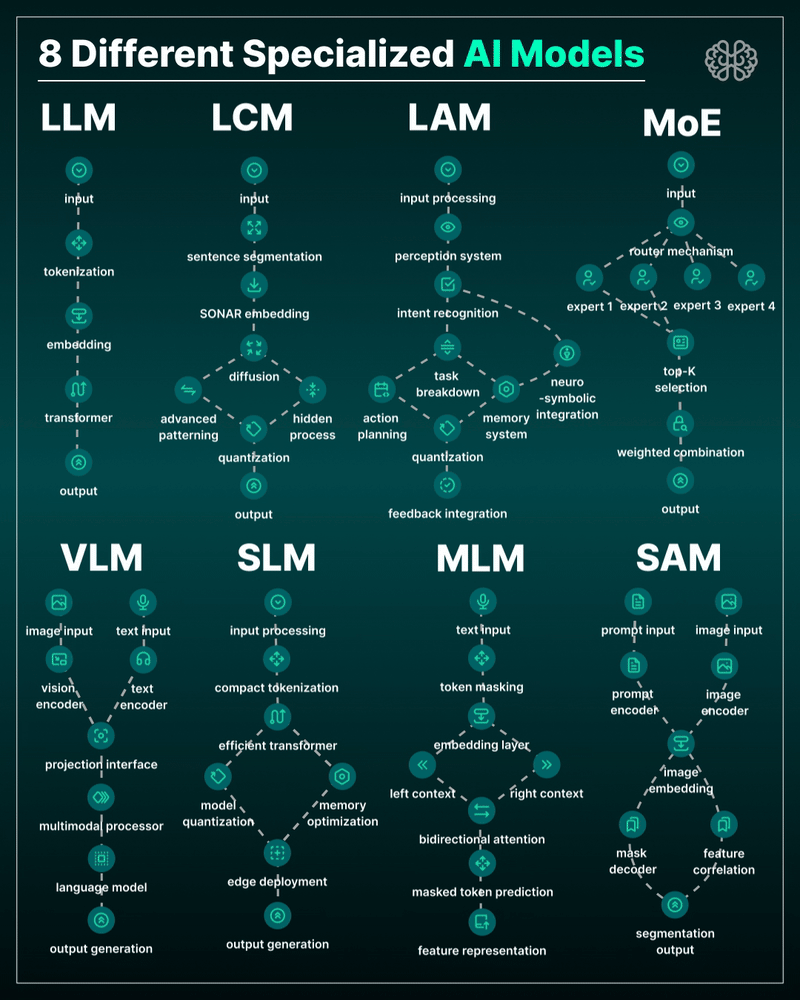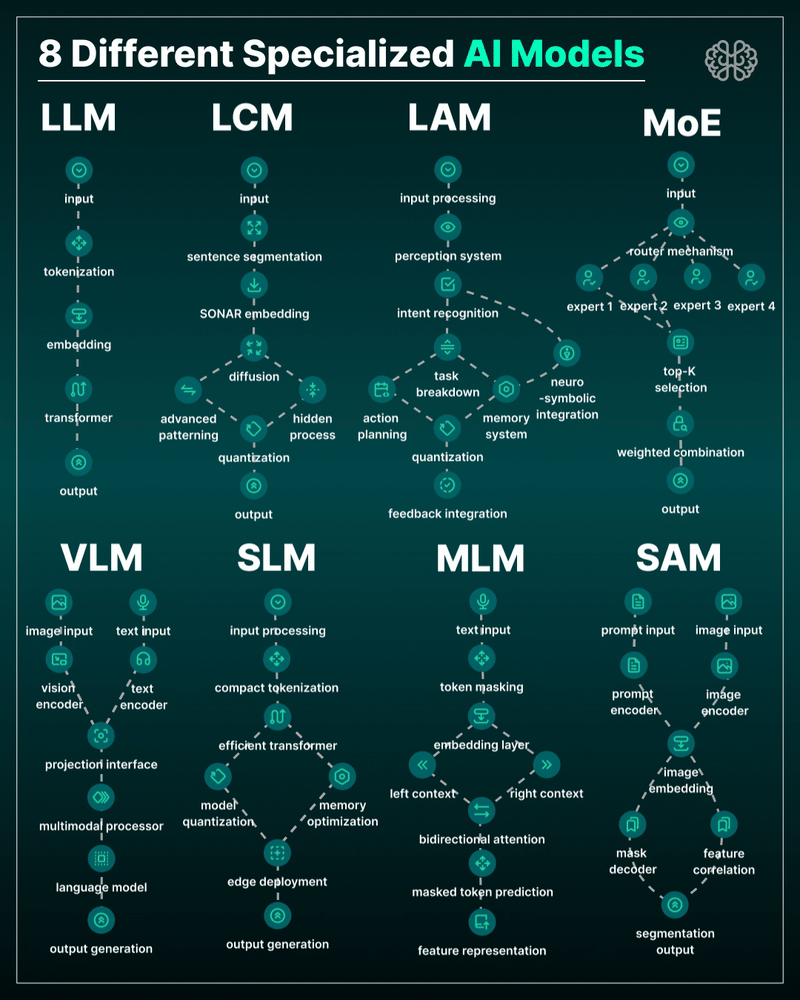
the 8 most important model types and what they’re actually built to do: ⬇️
1. 𝗟𝗟𝗠 – 𝗟𝗮𝗿𝗴𝗲 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹
→ Your ChatGPT-style model.
Handles text, predicts the next token, and powers 90% of GenAI hype.
🛠 Use case: content, code, convos.
2. 𝗟𝗖𝗠 – 𝗟𝗮𝘁𝗲𝗻𝘁 𝗖𝗼𝗻𝘀𝗶𝘀𝘁𝗲𝗻𝗰𝘆 𝗠𝗼𝗱𝗲𝗹
→ Lightweight, diffusion-style models.
Fast, quantized, and efficient — perfect for real-time or edge deployment.
🛠 Use case: image generation, optimized inference.
3. 𝗟𝗔𝗠 – 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗔𝗰𝘁𝗶𝗼𝗻 𝗠𝗼𝗱𝗲𝗹
→ Where LLM meets planning.
Adds memory, task breakdown, and intent recognition.
🛠 Use case: AI agents, tool use, step-by-step execution.
4. 𝗠𝗼𝗘 – 𝗠𝗶𝘅𝘁𝘂𝗿𝗲 𝗼𝗳 𝗘𝘅𝗽𝗲𝗿𝘁𝘀
→ One model, many minds.
Routes input to the right “expert” model slice — dynamic, scalable, efficient.
🛠 Use case: high-performance model serving at low compute cost.
5. 𝗩𝗟𝗠 – 𝗩𝗶𝘀𝗶𝗼𝗻 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹
→ Multimodal beast.
Combines image + text understanding via shared embeddings.
🛠 Use case: Gemini, GPT-4o, search, robotics, assistive tech.
6. 𝗦𝗟𝗠 – 𝗦𝗺𝗮𝗹𝗹 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹
→ Tiny but mighty.
Designed for edge use, fast inference, low latency, efficient memory.
🛠 Use case: on-device AI, chatbots, privacy-first GenAI.
7. 𝗠𝗟𝗠 – 𝗠𝗮𝘀𝗸𝗲𝗱 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹
→ The OG foundation model.
Predicts masked tokens using bidirectional context.
🛠 Use case: search, classification, embeddings, pretraining.
8. 𝗦𝗔𝗠 – 𝗦𝗲𝗴𝗺𝗲𝗻𝘁 𝗔𝗻𝘆𝘁𝗵𝗶𝗻𝗴 𝗠𝗼𝗱𝗲𝗹
→ Vision model for pixel-level understanding.
Highlights, segments, and understands *everything* in an image.
🛠 Use case: medical imaging, AR, robotics, visual agents.
https://blog.comfy.org/p/comfyui-native-api-nodes
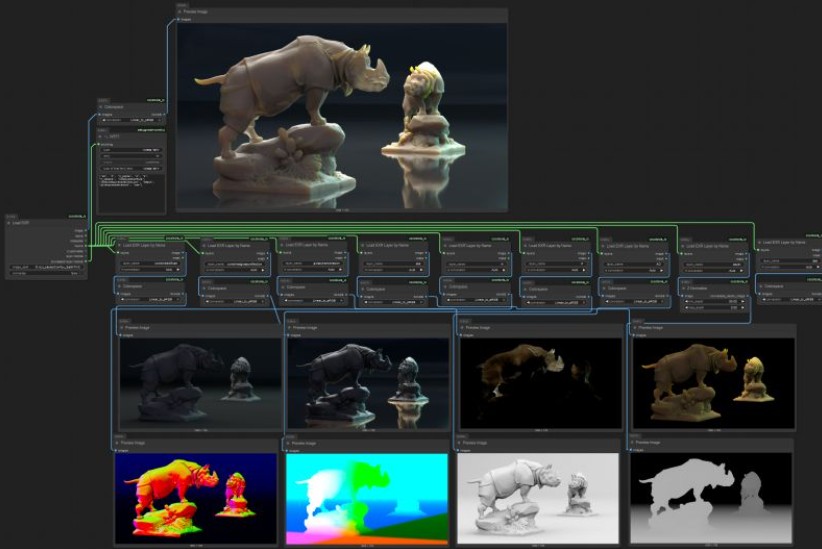
https://github.com/Conor-Collins/ComfyUI-CoCoTools_IO
https://vivariumnovum.it/saggistica/varia/la-vita-pittoresca-dellabate-uggeri
Book author: Claudio Tosti
Title: La vita pittoresca dell’abate Uggeri – Vol. I – La Giornata Tuscolana
Video made with Pixverse.ai and DaVinci Resolve
https://github.com/RupertAvery/DiffusionToolkit
It aims to help you organize, search and sort your ever-growing collection.
https://github.com/RupertAvery/DiffusionToolkit/blob/master/Diffusion.Toolkit/Tips.md
COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.