Views : 11




3Dprinting (185) A.I. (935) animation (356) blender (224) colour (242) commercials (53) composition (154) cool (375) design (662) Featured (95) hardware (319) IOS (109) jokes (141) lighting (302) modeling (161) music (189) photogrammetry (199) photography (758) production (1312) python (108) quotes (501) reference (318) software (1386) trailers (311) ves (579) VR (221)
POPULAR SEARCHES unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
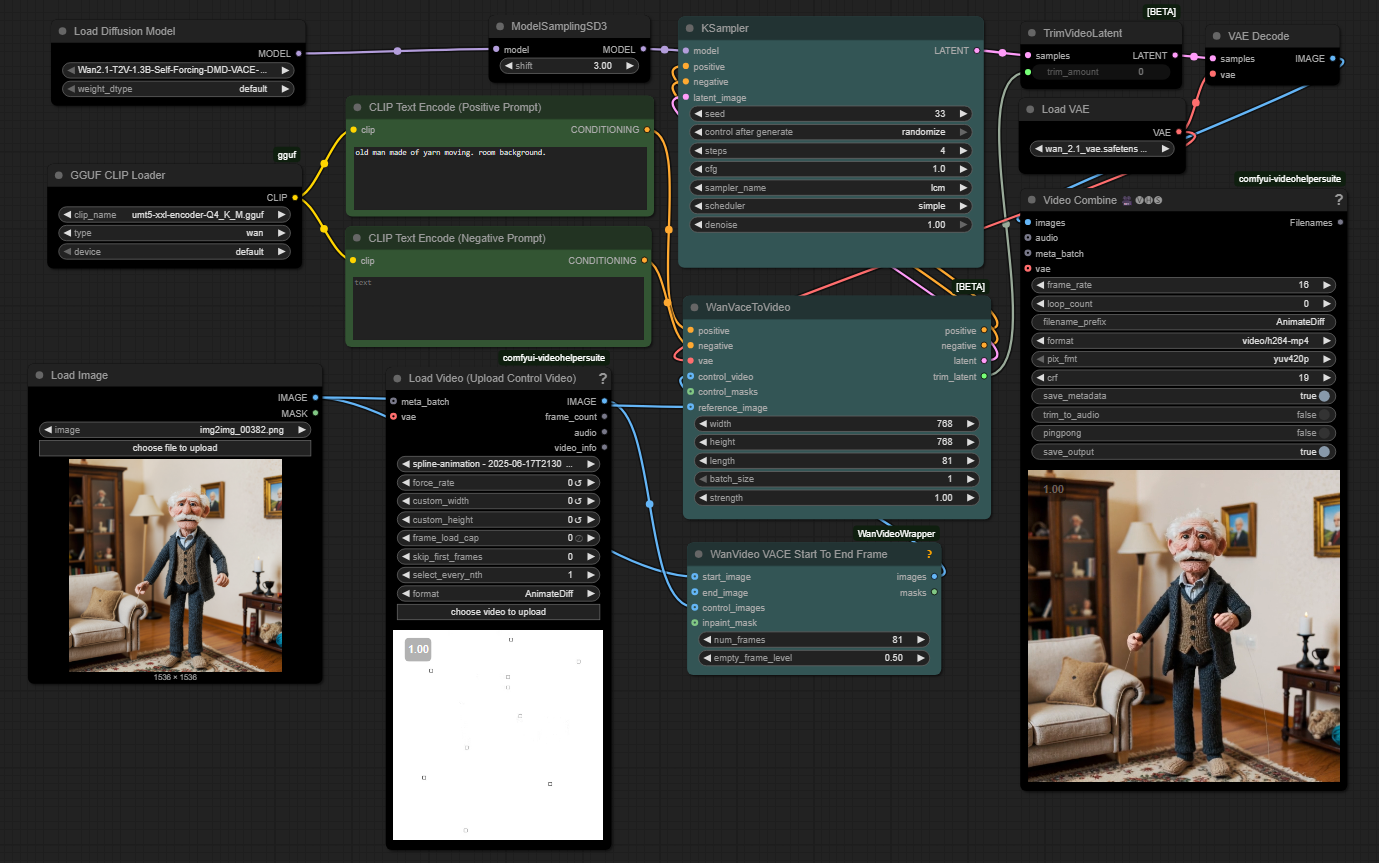
https://github.com/WhatDreamsCost/Spline-Path-Control
https://whatdreamscost.github.io/Spline-Path-Control/
https://github.com/WhatDreamsCost/Spline-Path-Control/tree/main/example_workflows
Spline Path Control is a simple tool designed to make it easy to create motion controls. It allows you to create and animate shapes that follow splines, and then export the result as a .webm video file.
This project was created to simplify the process of generating control videos for tools like VACE. Use it to control the motion of anything (camera movement, objects, humans etc) all without extra prompting.
Linear, Ease-in, Ease-out, and Ease-in-out functions for smooth acceleration and deceleration.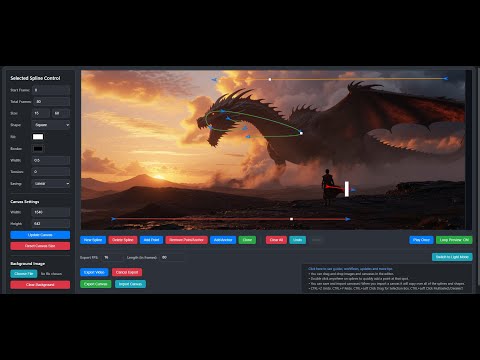
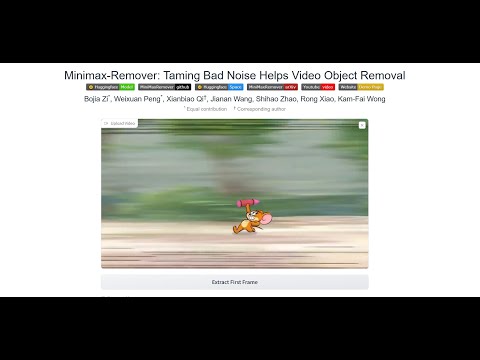
https://github.com/zibojia/MiniMax-Remover
MiniMax-Remover is a fast and effective video object remover based on minimax optimization. It operates in two stages: the first stage trains a remover using a simplified DiT architecture, while the second stage distills a robust remover with CFG removal and fewer inference steps.

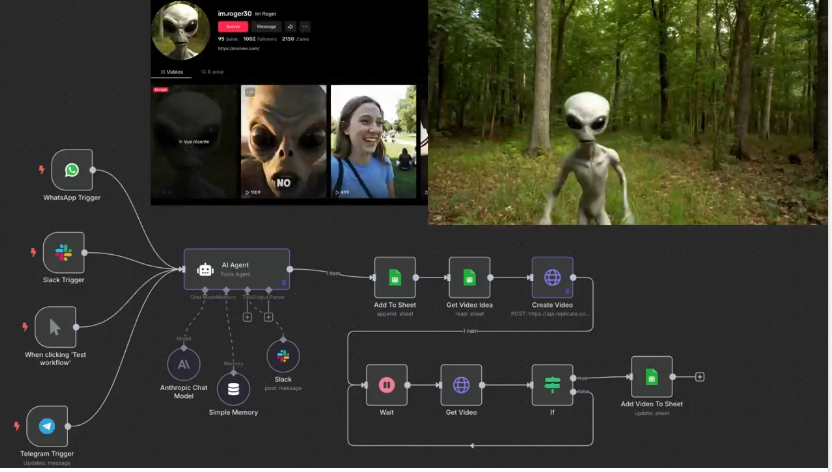
▶︎ You send your idea (from WhatsApp, Telegram, or Slack or manual click)
▶︎ The AI agent (powered by Gemini or any LLM) turns it into a structured video prompt
▶︎ It calls Replicate or Fal.ai to generate the video
▶︎ The final video is saved to your Google Sheet

RAG (retrieval augmented generation)
https://www.reddit.com/r/midjourney/comments/1lbblfq/ghibli_style_game_guide_included/
Made everything on Edits App
Image Generation on Midjourney
Video Generation on Kling 2.1
I used Joystick png to add buttons,then some asmr video sounds to make it look more lively,I used text as Buttons,
Prompts:
All Prompts are in order just like in video
First-person POV video game screenshot, playing as a young anime protagonist in a slightly oversized white t-shirt and knee-length blue shorts. Visible hands pushing open a sun-faded wooden door, forearms resting on the frame. In a dusty hallway mirror reflection: character’s soft Ghibli-style face with windblown hair. Inside a cozy coastal cottage: slanted sunlight through lace curtains, pastel walls with watercolor seascapes, overstuffed bookshelf spilling seashells. Foreground: ‘E: Rest’ prompt over a quilted sofa. Background: steaming teacup on a driftwood table, open window revealing distant lighthouse and Miyazaki fluffy clouds. Soft painterly textures, slight fisheye lens, identical HUD (minimap corner, health bar)
First-person POV video game screenshot, playing as a young anime protagonist in a slightly oversized white t-shirt and knee-length blue shorts. View includes visible hands gripping a steering wheel, sunlit arms resting on car door, and rearview mirror showing character’s soft Ghibli-style face with windblown hair. Driving through a vibrant coastal town: cobblestone streets, pastel houses with flower boxes, distant lighthouse. Soft painterly textures, Miyazaki skies with fluffy clouds, slight fisheye lens effect, HUD elements (minimap corner, health bar).
First-person POV video game screenshot, playing as a young protagonist in a loose white t-shirt and faded denim shorts. Visible arms holding a woven basket, sneakers stepping on rain-damp cobblestones. Walking through a chaotic Ghibli street market: cramped stalls selling glowing mushrooms, floating lanterns, and spiral-cut fruits. Fishmonger shouts while soot sprites dart between crates. Foreground: vendor handing you a peach (interactive ‘E’ prompt). Background: yakuza thugs lurking near a steaming noodle cart. Soft painterly lighting, depth of field, subtle HUD (minimap corner, health bar). Studio Ghibli meets Grand Theft Auto
First-person POV video game screenshot, playing as a young anime protagonist in a slightly oversized white t-shirt (salt-stained sleeves) and knee-length blue shorts, visible hands gripping a bamboo fishing rod. Kneeling on a mossy dock pier at sunset, arms resting on knees. Foreground: ‘E: Reel In’ prompt as line pulls taut. Background: pastel fishing boats, distant lighthouse under Miyazaki’s fluffy clouds. Glowing koi fish breaching turquoise water, soot sprites stealing bait from a tin. Identical soft painterly textures, fisheye lens effect, HUD (minimap corner, health bar).
Video Prompts :
All Prompts are in order just like in video
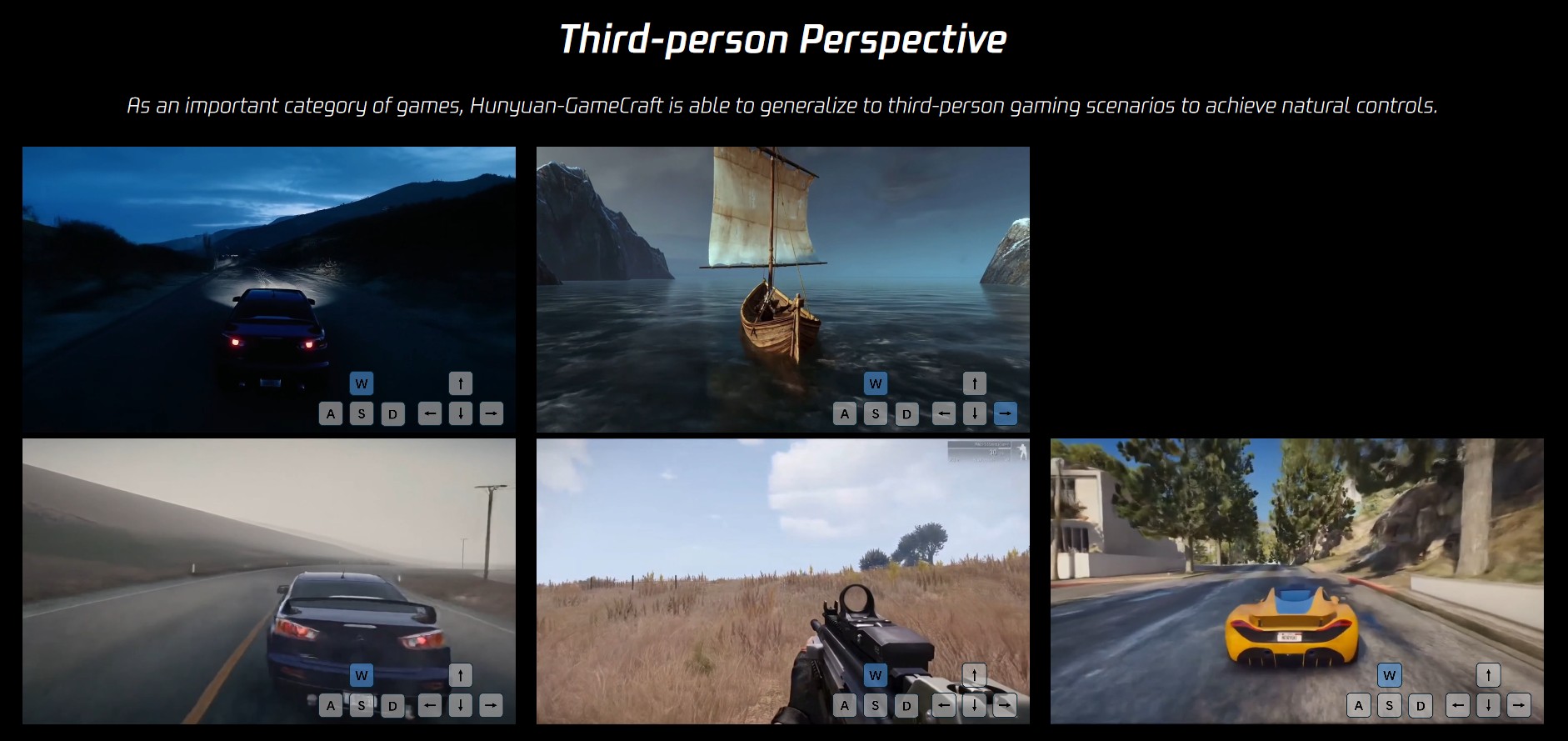
The black-haired boy strides from the rustic house toward the ocean, the camera tracking his movement in a GTA-style third-person perspective as coastal winds flutter white curtains and sunlight glimmers on distant sailboats, blending warm interior details with expanding seaside horizons under a tranquil sky.
The brown-haired boy drives a vintage blue convertible along the coastal cobblestone street, colorful flower-adorned buildings passing by as the camera follows the car’s journey toward the sunlit ocean horizon, sea breeze gently tousling his hair under a serene sky.
The young boy navigates the bustling cobblestone market, basket of oranges in arm, as vibrant stalls and fluttering awnings frame his journey, the camera tracking his focused stride through chattering crowds under swaying traditional lanterns.
A school of fish swims gracefully through crystal-clear water, sunlight filtering through the surface, coral reefs swaying gently, creating a serene underwater scene with the camera stationary.
https://huggingface.co/tencent/Hunyuan3D-2mv
https://huggingface.co/tencent/Hunyuan3D-2mini
https://github.com/Tencent/Hunyuan3D-2
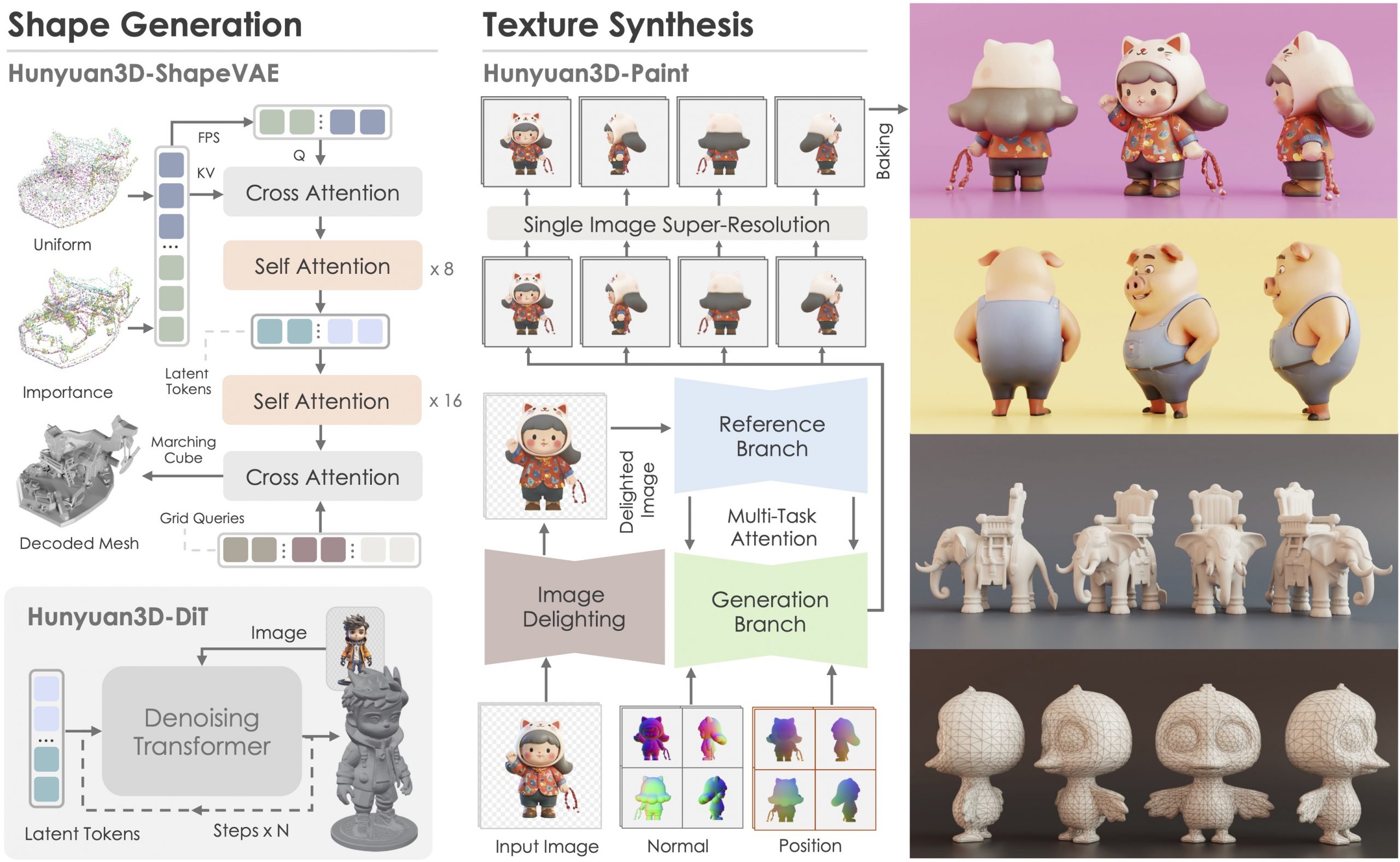
Tencent just made Hunyuan3D 2.1 open-source.
This is the first fully open-source, production-ready PBR 3D generative model with cinema-grade quality.
https://github.com/Tencent-Hunyuan/Hunyuan3D-2.1
What makes it special?
• Advanced PBR material synthesis brings realistic materials like leather, bronze, and more to life with stunning light interactions.
• Complete access to model weights, training/inference code, data pipelines.
• Optimized to run on accessible hardware.
• Built for real-world applications with professional-grade output quality.
They’re making it accessible to everyone:
• Complete open-source ecosystem with full documentation.
• Ready-to-use model weights and training infrastructure.
• Live demo available for instant testing.
• Comprehensive GitHub repository with implementation details.

Load holograms, animate cameras, capture frames, and feed them to your favorite AI models. Developed by Lovis Odin for Kartel.ai
You can obtain the MPD URL directly from the official 8i Web Player.
https://github.com/Kartel-ai/ComfyUI-8iPlayer/
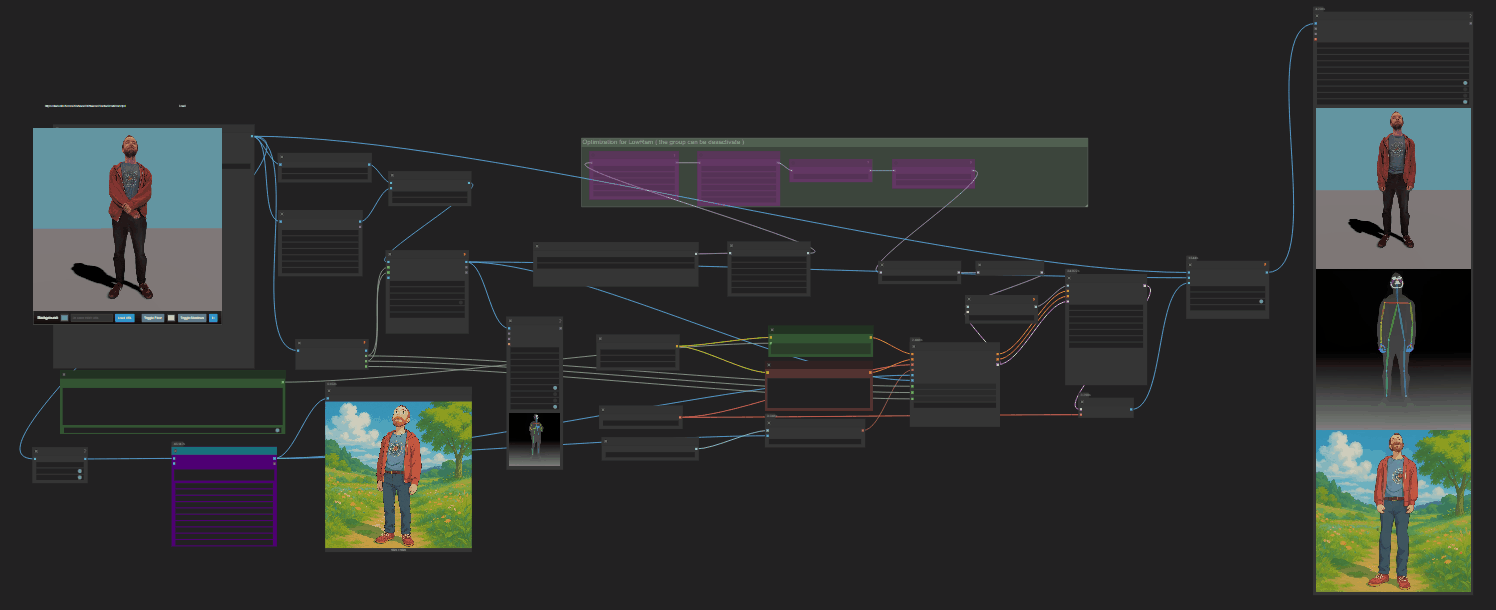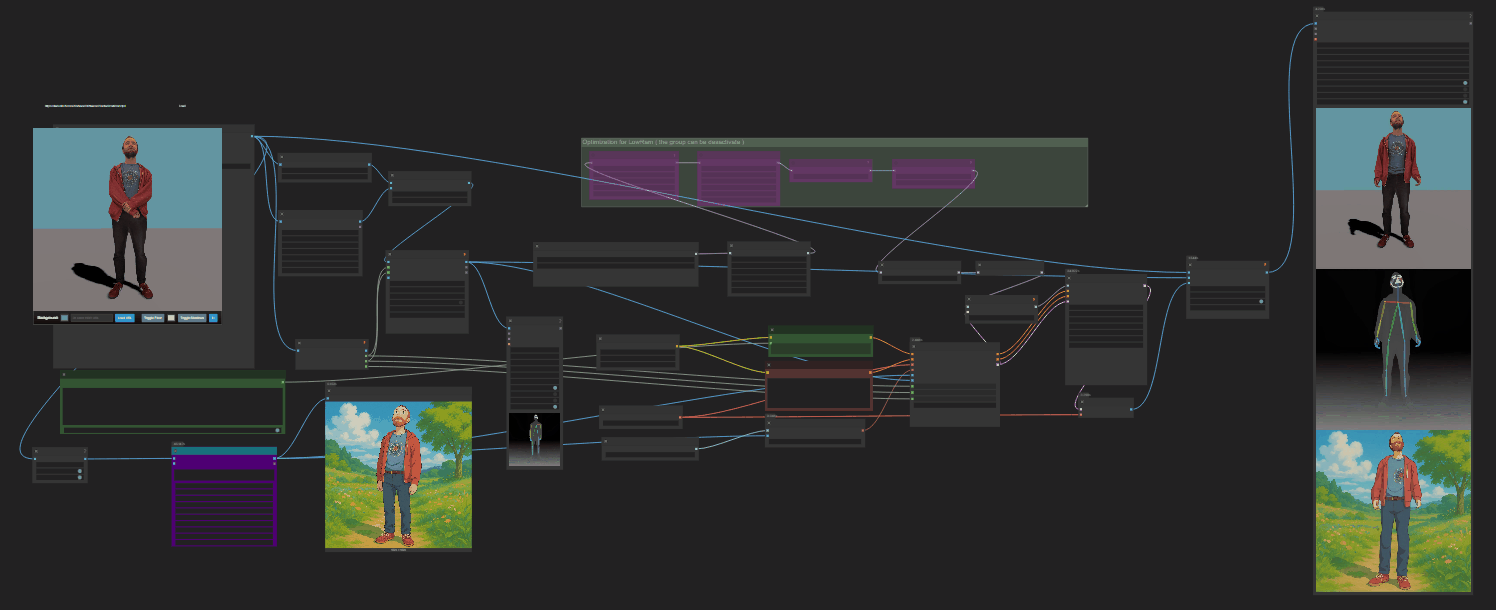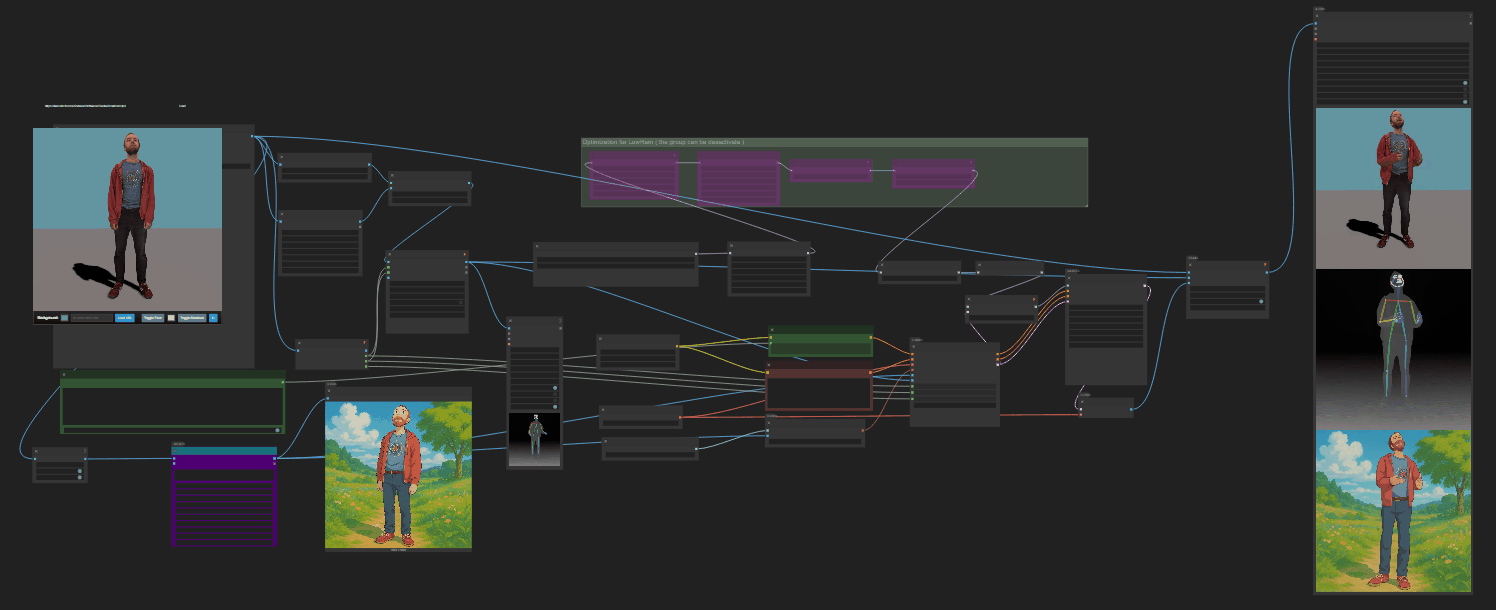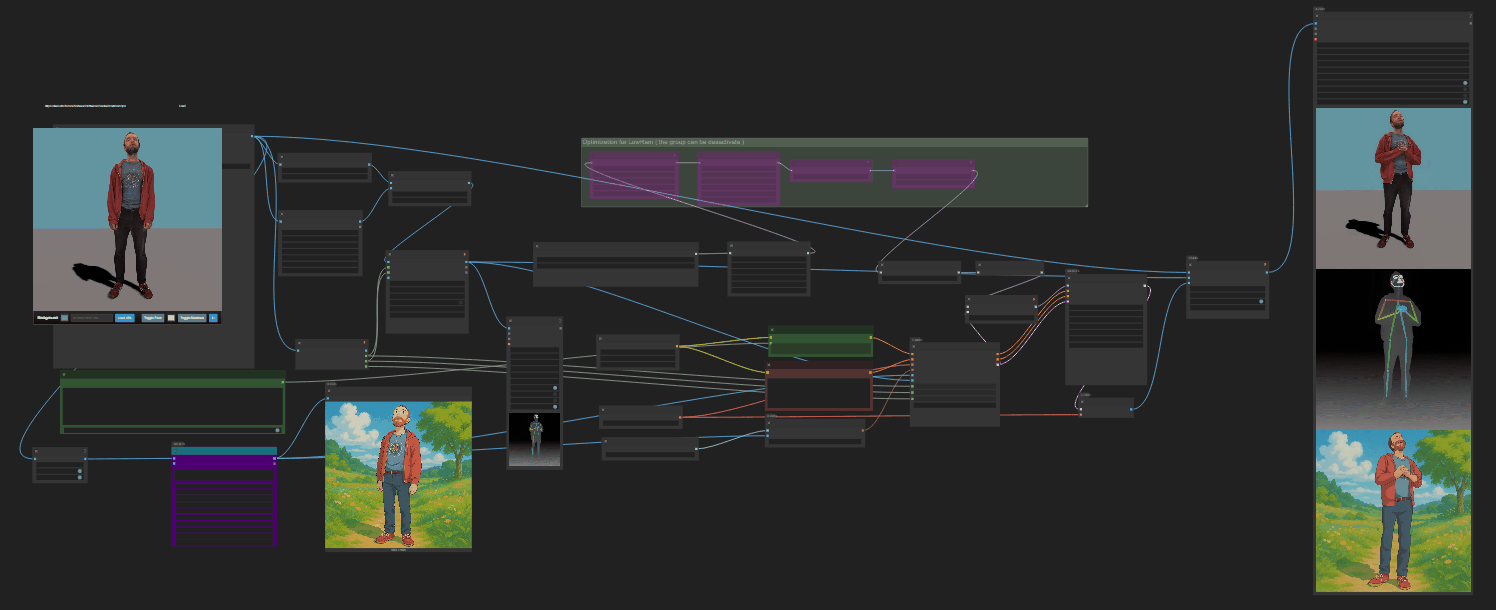
https://github.com/nv-tlabs/GEN3C
Load a picture, define a camera path in 3D, and then render a photoreal video.

https://www.axios.com/2025/06/11/disney-nbcu-midjourney-copyright
Why it matters: It’s the first legal action that major Hollywood studios have taken against a generative AI company.
The complaint, filed in a U.S. District Court in central California, accuses Midjourney of both direct and secondary copyright infringement by using the studios’ intellectual property to train their large language model and by displaying AI-generated images of their copyrighted characters.


COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.