1. Watch every frame of raw footage twice. On the second time, take notes. If you don’t do this and try to start developing a scene premature, then it’s a big disservice to yourself and to the director, actors and production crew.
2. Nurture the relationships with the director. You are the secondary person in the relationship. Be calm and continually offer solutions. Get the main intention of the film as soon as possible from the director.
3. Organize your media so that you can find any shot instantly.
4. Factor in extra time for renders, exports, errors and crashes.
5. Attempt edits and ideas that shouldn’t work. It just might work. Until you do it and watch it, you won’t know. Don’t rule out ideas just because they don’t make sense in your mind.
6. Spend more time on your audio. It’s the glue of your edit. AUDIO SAVES EVERYTHING. Create fluid and seamless audio under your video.
7. Make cuts for the scene, but always in context for the whole film. Have a macro and a micro view at all times.
The intricate relationship between the eyes and the brain, often termed the eye-mind connection, reveals that vision is predominantly a cognitive process. This understanding has profound implications for fields such as design, where capturing and maintaining attention is paramount. This essay delves into the nuances of visual perception, the brain’s role in interpreting visual data, and how this knowledge can be applied to effective design strategies.
This cognitive aspect of vision is evident in phenomena such as optical illusions, where the brain interprets visual information in a way that contradicts physical reality. These illusions underscore that what we “see” is not merely a direct recording of the external world but a constructed experience shaped by cognitive processes.
Understanding the cognitive nature of vision is crucial for effective design. Designers must consider how the brain processes visual information to create compelling and engaging visuals. This involves several key principles:
It lets you load any .cube LUT right in your browser, see the RGB curves, and use a split view on the Granger Test Image to compare the original vs. LUT-applied version in real time — perfect for spotting hue shifts, saturation changes, and contrast tweaks.
“Memory colors are colors that are universally associated with specific objects, elements or scenes in our environment. They are the colors that we expect to see in specific situations: these colors are based on our expectation of how certain objects should look based on our past experiences and memories.
For instance, we associate specific hues, saturation and brightness values with human skintones and a slight variation can significantly affect the way we perceive a scene.
Similarly, we expect blue skies to have a particular hue, green trees to be a specific shade and so on.
Memory colors live inside of our brains and we often impose them onto what we see. By considering them during the grading process, the resulting image will be more visually appealing and won’t distract the viewer from the intended message of the story. Even a slight deviation from memory colors in a movie can create a sense of discordance, ultimately detracting from the viewer’s experience.”
This paper presents an introduction to the color pipelines behind modern feature-film visual-effects and animation.
Authored by Jeremy Selan, and reviewed by the members of the VES Technology Committee including Rob Bredow, Dan Candela, Nick Cannon, Paul Debevec, Ray Feeney, Andy Hendrickson, Gautham Krishnamurti, Sam Richards, Jordan Soles, and Sebastian Sylwan.
Supported by LG, Philips, Panasonic and Sony sell the OLED system TVs. OLED stands for “organic light emitting diode.” It is a fundamentally different technology from LCD, the major type of TV today. OLED is “emissive,” meaning the pixels emit their own light.
Samsung is branding its best TVs with a new acronym: “QLED” QLED (according to Samsung) stands for “quantum dot LED TV.” It is a variation of the common LED LCD, adding a quantum dot film to the LCD “sandwich.” QLED, like LCD, is, in its current form, “transmissive” and relies on an LED backlight.
OLED is the only technology capable of absolute blacks and extremely bright whites on a per-pixel basis. LCD definitely can’t do that, and even the vaunted, beloved, dearly departed plasma couldn’t do absolute blacks.
QLED, as an improvement over OLED, significantly improves the picture quality. QLED can produce an even wider range of colors than OLED, which says something about this new tech. QLED is also known to produce up to 40% higher luminance efficiency than OLED technology. Further, many tests conclude that QLED is far more efficient in terms of power consumption than its predecessor, OLED.
An exposure stop is a unit measurement of Exposure as such it provides a universal linear scale to measure the increase and decrease in light, exposed to the image sensor, due to changes in shutter speed, iso and f-stop.
+-1 stop is a doubling or halving of the amount of light let in when taking a photo
1 EV (exposure value) is just another way to say one stop of exposure change.
Same applies to shutter speed, iso and aperture.
Doubling or halving your shutter speed produces an increase or decrease of 1 stop of exposure.
Doubling or halving your iso speed produces an increase or decrease of 1 stop of exposure.
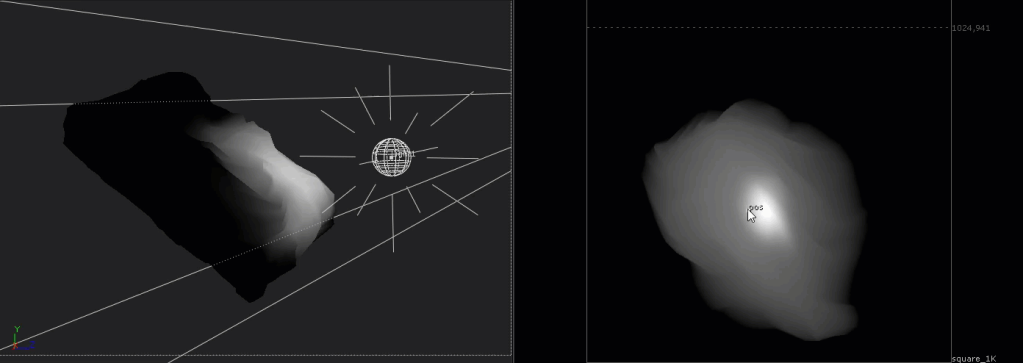
When collecting hdri make sure the data supports basic metadata, such as:
Iso
Aperture
Exposure time or shutter time
Color temperature
Color space Exposure value (what the sensor receives of the sun intensity in lux)
7+ brackets (with 5 or 6 being the perceived balanced exposure)
In image processing, computer graphics, and photography, high dynamic range imaging (HDRI or just HDR) is a set of techniques that allow a greater dynamic range of luminances (a Photometry measure of the luminous intensity per unit area of light travelling in a given direction. It describes the amount of light that passes through or is emitted from a particular area, and falls within a given solid angle) between the lightest and darkest areas of an image than standard digital imaging techniques or photographic methods. This wider dynamic range allows HDR images to represent more accurately the wide range of intensity levels found in real scenes ranging from direct sunlight to faint starlight and to the deepest shadows.
The two main sources of HDR imagery are computer renderings and merging of multiple photographs, which in turn are known as low dynamic range (LDR) or standard dynamic range (SDR) images. Tone Mapping (Look-up) techniques, which reduce overall contrast to facilitate display of HDR images on devices with lower dynamic range, can be applied to produce images with preserved or exaggerated local contrast for artistic effect. Photography
In photography, dynamic range is measured in Exposure Values (in photography, exposure value denotes all combinations of camera shutter speed and relative aperture that give the same exposure. The concept was developed in Germany in the 1950s) differences or stops, between the brightest and darkest parts of the image that show detail. An increase of one EV or one stop is a doubling of the amount of light.
The human response to brightness is well approximated by a Steven’s power law, which over a reasonable range is close to logarithmic, as described by the Weber�Fechner law, which is one reason that logarithmic measures of light intensity are often used as well.
HDR is short for High Dynamic Range. It’s a term used to describe an image which contains a greater exposure range than the “black” to “white” that 8 or 16-bit integer formats (JPEG, TIFF, PNG) can describe. Whereas these Low Dynamic Range images (LDR) can hold perhaps 8 to 10 f-stops of image information, HDR images can describe beyond 30 stops and stored in 32 bit images.
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.





















































![[gamma correction test]](http://www.madore.org/~david/misc/color/gammatest.png "sRGB gamma correction test")










 Local copy:
Local copy: