


COMPOSITION
DESIGN





























COLOR
-
Scene Referred vs Display Referred color workflows
Read more: Scene Referred vs Display Referred color workflowsDisplay Referred it is tied to the target hardware, as such it bakes color requirements into every type of media output request.
Scene Referred uses a common unified wide gamut and targeting audience through CDL and DI libraries instead.
So that color information stays untouched and only “transformed” as/when needed.



Sources:
– Victor Perez – Color Management Fundamentals & ACES Workflows in Nuke
– https://z-fx.nl/ColorspACES.pdf
– Wicus
-
Tim Kang – calibrated white light values in sRGB color space
Read more: Tim Kang – calibrated white light values in sRGB color space8bit sRGB encoded
2000K 255 139 22
2700K 255 172 89
3000K 255 184 109
3200K 255 190 122
4000K 255 211 165
4300K 255 219 178
D50 255 235 205
D55 255 243 224
D5600 255 244 227
D6000 255 249 240
D65 255 255 255
D10000 202 221 255
D20000 166 196 2558bit Rec709 Gamma 2.4
2000K 255 145 34
2700K 255 177 97
3000K 255 187 117
3200K 255 193 129
4000K 255 214 170
4300K 255 221 182
D50 255 236 208
D55 255 243 226
D5600 255 245 229
D6000 255 250 241
D65 255 255 255
D10000 204 222 255
D20000 170 199 2558bit Display P3 encoded
2000K 255 154 63
2700K 255 185 109
3000K 255 195 127
3200K 255 201 138
4000K 255 219 176
4300K 255 225 187
D50 255 239 212
D55 255 245 228
D5600 255 246 231
D6000 255 251 242
D65 255 255 255
D10000 208 223 255
D20000 175 199 25510bit Rec2020 PQ (100 nits)
2000K 520 435 273
2700K 520 466 358
3000K 520 475 384
3200K 520 480 399
4000K 520 495 446
4300K 520 500 458
D50 520 510 482
D55 520 514 497
D5600 520 514 500
D6000 520 517 509
D65 520 520 520
D10000 479 489 520
D20000 448 464 520
-
Mysterious animation wins best illusion of 2011 – Motion silencing illusion
Read more: Mysterious animation wins best illusion of 2011 – Motion silencing illusionThe 2011 Best Illusion of the Year uses motion to render color changes invisible, and so reveals a quirk in our visual systems that is new to scientists.
https://en.wikipedia.org/wiki/Motion_silencing_illusion
“It is a really beautiful effect, revealing something about how our visual system works that we didn’t know before,” said Daniel Simons, a professor at the University of Illinois, Champaign-Urbana. Simons studies visual cognition, and did not work on this illusion. Before its creation, scientists didn’t know that motion had this effect on perception, Simons said.
A viewer stares at a speck at the center of a ring of colored dots, which continuously change color. When the ring begins to rotate around the speck, the color changes appear to stop. But this is an illusion. For some reason, the motion causes our visual system to ignore the color changes. (You can, however, see the color changes if you follow the rotating circles with your eyes.)















LIGHTING
-
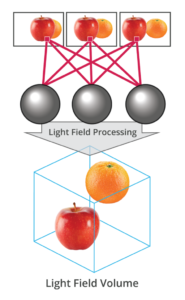
What is the Light Field?
Read more: What is the Light Field?http://lightfield-forum.com/what-is-the-lightfield/
The light field consists of the total of all light rays in 3D space, flowing through every point and in every direction.
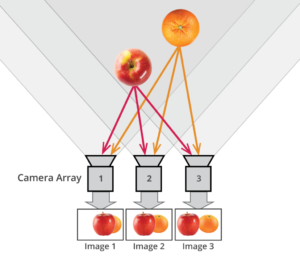
How to Record a Light Field
- a single, robotically controlled camera
- a rotating arc of cameras
- an array of cameras or camera modules
- a single camera or camera lens fitted with a microlens array
-
studiobinder.com – What is Tenebrism and Hard Lighting — The Art of Light and Shadow and chiaroscuro Explained
Read more: studiobinder.com – What is Tenebrism and Hard Lighting — The Art of Light and Shadow and chiaroscuro Explainedhttps://www.studiobinder.com/blog/what-is-tenebrism-art-definition/
https://www.studiobinder.com/blog/what-is-hard-light-photography/


-
IES Light Profiles and editing software
Read more: IES Light Profiles and editing softwarehttp://www.derekjenson.com/3d-blog/ies-light-profiles
https://ieslibrary.com/en/browse#ies
https://leomoon.com/store/shaders/ies-lights-pack
https://docs.arnoldrenderer.com/display/a5afmug/ai+photometric+light
IES profiles are useful for creating life-like lighting, as they can represent the physical distribution of light from any light source.
The IES format was created by the Illumination Engineering Society, and most lighting manufacturers provide IES profile for the lights they manufacture.


-
Convert between light exposure and intensity
Read more: Convert between light exposure and intensityimport math,sys def Exposure2Intensity(exposure): exp = float(exposure) result = math.pow(2,exp) print(result) Exposure2Intensity(0) def Intensity2Exposure(intensity): inarg = float(intensity) if inarg == 0: print("Exposure of zero intensity is undefined.") return if inarg < 1e-323: inarg = max(inarg, 1e-323) print("Exposure of negative intensities is undefined. Clamping to a very small value instead (1e-323)") result = math.log(inarg, 2) print(result) Intensity2Exposure(0.1)Why Exposure?
Exposure is a stop value that multiplies the intensity by 2 to the power of the stop. Increasing exposure by 1 results in double the amount of light.
Artists think in “stops.” Doubling or halving brightness is easy math and common in grading and look-dev.
Exposure counts doublings in whole stops:- +1 stop = ×2 brightness
- −1 stop = ×0.5 brightness
This gives perceptually even controls across both bright and dark values.
Why Intensity?
Intensity is linear.
It’s what render engines and compositors expect when:- Summing values
- Averaging pixels
- Multiplying or filtering pixel data
Use intensity when you need the actual math on pixel/light data.
Formulas (from your Python)
- Intensity from exposure: intensity = 2**exposure
- Exposure from intensity: exposure = log₂(intensity)
Guardrails:
- Intensity must be > 0 to compute exposure.
- If intensity = 0 → exposure is undefined.
- Clamp tiny values (e.g.
1e−323) before using log₂.
Use Exposure (stops) when…
- You want artist-friendly sliders (−5…+5 stops)
- Adjusting look-dev or grading in even stops
- Matching plates with quick ±1 stop tweaks
- Tweening brightness changes smoothly across ranges
Use Intensity (linear) when…
- Storing raw pixel/light values
- Multiplying textures or lights by a gain
- Performing sums, averages, and filters
- Feeding values to render engines expecting linear data
Examples
- +2 stops → 2**2 = 4.0 (×4)
- +1 stop → 2**1 = 2.0 (×2)
- 0 stop → 2**0 = 1.0 (×1)
- −1 stop → 2**(−1) = 0.5 (×0.5)
- −2 stops → 2**(−2) = 0.25 (×0.25)
- Intensity 0.1 → exposure = log₂(0.1) ≈ −3.32
Rule of thumb
Think in stops (exposure) for controls and matching.
Compute in linear (intensity) for rendering and math.













COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Godot Cheat Sheets
-
Blender VideoDepthAI – Turn any video into 3D Animated Scenes
-
Photography basics: Solid Angle measures
-
AI Search – Find The Best AI Tools & Apps
-
Zibra.AI – Real-Time Volumetric Effects in Virtual Production. Now free for Indies!
-
MiniMax-Remover – Taming Bad Noise Helps Video Object Removal Rotoscoping
-
Embedding frame ranges into Quicktime movies with FFmpeg
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
