


COMPOSITION
-
Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental process
Read more: Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental processhttps://www.chrbutler.com/understanding-the-eye-mind-connection
The intricate relationship between the eyes and the brain, often termed the eye-mind connection, reveals that vision is predominantly a cognitive process. This understanding has profound implications for fields such as design, where capturing and maintaining attention is paramount. This essay delves into the nuances of visual perception, the brain’s role in interpreting visual data, and how this knowledge can be applied to effective design strategies.
This cognitive aspect of vision is evident in phenomena such as optical illusions, where the brain interprets visual information in a way that contradicts physical reality. These illusions underscore that what we “see” is not merely a direct recording of the external world but a constructed experience shaped by cognitive processes.
Understanding the cognitive nature of vision is crucial for effective design. Designers must consider how the brain processes visual information to create compelling and engaging visuals. This involves several key principles:
- Attention and Engagement
- Visual Hierarchy
- Cognitive Load Management
- Context and Meaning

-
7 Commandments of Film Editing and composition
Read more: 7 Commandments of Film Editing and composition
1. Watch every frame of raw footage twice. On the second time, take notes. If you don’t do this and try to start developing a scene premature, then it’s a big disservice to yourself and to the director, actors and production crew.
2. Nurture the relationships with the director. You are the secondary person in the relationship. Be calm and continually offer solutions. Get the main intention of the film as soon as possible from the director.
3. Organize your media so that you can find any shot instantly.
4. Factor in extra time for renders, exports, errors and crashes.
5. Attempt edits and ideas that shouldn’t work. It just might work. Until you do it and watch it, you won’t know. Don’t rule out ideas just because they don’t make sense in your mind.
6. Spend more time on your audio. It’s the glue of your edit. AUDIO SAVES EVERYTHING. Create fluid and seamless audio under your video.
7. Make cuts for the scene, but always in context for the whole film. Have a macro and a micro view at all times.
-
Composition – cinematography Cheat Sheet
Read more: Composition – cinematography Cheat Sheet
Where is our eye attracted first? Why?
Size. Focus. Lighting. Color.
Size. Mr. White (Harvey Keitel) on the right.
Focus. He’s one of the two objects in focus.
Lighting. Mr. White is large and in focus and Mr. Pink (Steve Buscemi) is highlighted by
a shaft of light.
Color. Both are black and white but the read on Mr. White’s shirt now really stands out.
(more…)
What type of lighting? -
Photography basics: Camera Aspect Ratio, Sensor Size and Depth of Field – resolutions
Read more: Photography basics: Camera Aspect Ratio, Sensor Size and Depth of Field – resolutionshttp://www.shutterangle.com/2012/cinematic-look-aspect-ratio-sensor-size-depth-of-field/
http://www.shutterangle.com/2012/film-video-aspect-ratio-artistic-choice/


















DESIGN
-
Mike Mitchell x Marvel x Mondo – Iconic portraits of Marvel’s huge stable of heroes and villains
Read more: Mike Mitchell x Marvel x Mondo – Iconic portraits of Marvel’s huge stable of heroes and villainshttps://mondoshop.com/blogs/gallery/16910155-mike-mitchell-x-marvel-x-mondo
https://time.com/69659/marvel-comics-mike-mitchell-artist-portraits/




















COLOR
-
Black Body color aka the Planckian Locus curve for white point eye perception
Read more: Black Body color aka the Planckian Locus curve for white point eye perceptionhttp://en.wikipedia.org/wiki/Black-body_radiation

Black-body radiation is the type of electromagnetic radiation within or surrounding a body in thermodynamic equilibrium with its environment, or emitted by a black body (an opaque and non-reflective body) held at constant, uniform temperature. The radiation has a specific spectrum and intensity that depends only on the temperature of the body.
A black-body at room temperature appears black, as most of the energy it radiates is infra-red and cannot be perceived by the human eye. At higher temperatures, black bodies glow with increasing intensity and colors that range from dull red to blindingly brilliant blue-white as the temperature increases.
(more…) -
No one could see the colour blue until modern times
Read more: No one could see the colour blue until modern timeshttps://www.businessinsider.com/what-is-blue-and-how-do-we-see-color-2015-2

The way humans see the world… until we have a way to describe something, even something so fundamental as a colour, we may not even notice that something it’s there.
Ancient languages didn’t have a word for blue — not Greek, not Chinese, not Japanese, not Hebrew, not Icelandic cultures. And without a word for the colour, there’s evidence that they may not have seen it at all.
https://www.wnycstudios.org/story/211119-colorsEvery language first had a word for black and for white, or dark and light. The next word for a colour to come into existence — in every language studied around the world — was red, the colour of blood and wine.
After red, historically, yellow appears, and later, green (though in a couple of languages, yellow and green switch places). The last of these colours to appear in every language is blue.The only ancient culture to develop a word for blue was the Egyptians — and as it happens, they were also the only culture that had a way to produce a blue dye.
https://mymodernmet.com/shades-of-blue-color-history/True blue hues are rare in the natural world because synthesizing pigments that absorb longer-wavelength light (reds and yellows) while reflecting shorter-wavelength blue light requires exceptionally elaborate molecular structures—biochemical feats that most plants and animals simply don’t undertake.
When you gaze at a blueberry’s deep blue surface, you’re actually seeing structural coloration rather than a true blue pigment. A fine, waxy bloom on the berry’s skin contains nanostructures that preferentially scatter blue and violet light, giving the fruit its signature blue sheen even though its inherent pigment is reddish.
Similarly, many of nature’s most striking blues—like those of blue jays and morpho butterflies—arise not from blue pigments but from microscopic architectures in feathers or wing scales. These tiny ridges and air pockets manipulate incoming light so that blue wavelengths emerge most prominently, creating vivid, angle-dependent colors through scattering rather than pigment alone.
(more…) -
Stefan Ringelschwandtner – LUT Inspector tool
Read more: Stefan Ringelschwandtner – LUT Inspector toolIt lets you load any .cube LUT right in your browser, see the RGB curves, and use a split view on the Granger Test Image to compare the original vs. LUT-applied version in real time — perfect for spotting hue shifts, saturation changes, and contrast tweaks.
https://mononodes.com/lut-inspector/


-
About green screens
Read more: About green screenshackaday.com/2015/02/07/how-green-screen-worked-before-computers/
www.newtek.com/blog/tips/best-green-screen-materials/
www.chromawall.com/blog//chroma-key-green

Chroma Key Green, the color of green screens is also known as Chroma Green and is valued at approximately 354C in the Pantone color matching system (PMS).
Chroma Green can be broken down in many different ways. Here is green screen green as other values useful for both physical and digital production:
Green Screen as RGB Color Value: 0, 177, 64
Green Screen as CMYK Color Value: 81, 0, 92, 0
Green Screen as Hex Color Value: #00b140
Green Screen as Websafe Color Value: #009933Chroma Key Green is reasonably close to an 18% gray reflectance.
Illuminate your green screen with an uniform source with less than 2/3 EV variation.
The level of brightness at any given f-stop should be equivalent to a 90% white card under the same lighting. -
Björn Ottosson – How software gets color wrong
Read more: Björn Ottosson – How software gets color wronghttps://bottosson.github.io/posts/colorwrong/
Most software around us today are decent at accurately displaying colors. Processing of colors is another story unfortunately, and is often done badly.
To understand what the problem is, let’s start with an example of three ways of blending green and magenta:
- Perceptual blend – A smooth transition using a model designed to mimic human perception of color. The blending is done so that the perceived brightness and color varies smoothly and evenly.
- Linear blend – A model for blending color based on how light behaves physically. This type of blending can occur in many ways naturally, for example when colors are blended together by focus blur in a camera or when viewing a pattern of two colors at a distance.
- sRGB blend – This is how colors would normally be blended in computer software, using sRGB to represent the colors.

Let’s look at some more examples of blending of colors, to see how these problems surface more practically. The examples use strong colors since then the differences are more pronounced. This is using the same three ways of blending colors as the first example.

Instead of making it as easy as possible to work with color, most software make it unnecessarily hard, by doing image processing with representations not designed for it. Approximating the physical behavior of light with linear RGB models is one easy thing to do, but more work is needed to create image representations tailored for image processing and human perception.
Also see:













LIGHTING
-
Custom bokeh in a raytraced DOF render
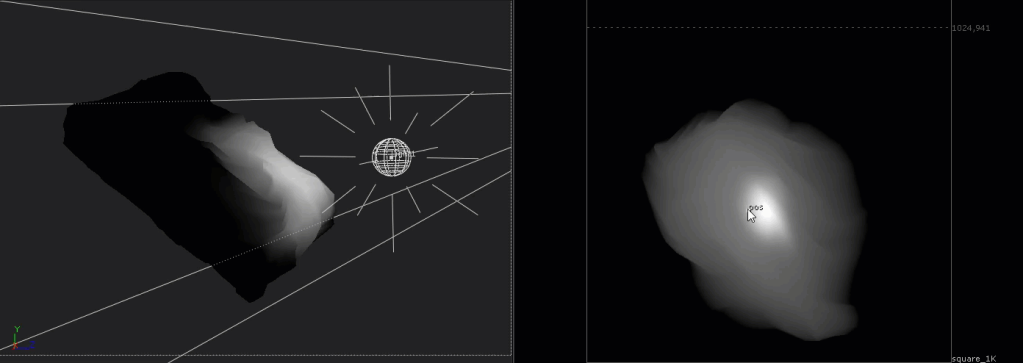
Read more: Custom bokeh in a raytraced DOF render

To achieve a custom pinhole camera effect with a custom bokeh in Arnold Raytracer, you can follow these steps:
- Set the render camera with a focal length around 50 (or as needed)
- Set the F-Stop to a high value (e.g., 22).
- Set the focus distance as you require
- Turn on DOF
- Place a plane a few cm in front of the camera.
- Texture the plane with a transparent shape at the center of it. (Transmission with no specular roughness)
-
Black Body color aka the Planckian Locus curve for white point eye perception
Read more: Black Body color aka the Planckian Locus curve for white point eye perceptionhttp://en.wikipedia.org/wiki/Black-body_radiation
Black-body radiation is the type of electromagnetic radiation within or surrounding a body in thermodynamic equilibrium with its environment, or emitted by a black body (an opaque and non-reflective body) held at constant, uniform temperature. The radiation has a specific spectrum and intensity that depends only on the temperature of the body.
A black-body at room temperature appears black, as most of the energy it radiates is infra-red and cannot be perceived by the human eye. At higher temperatures, black bodies glow with increasing intensity and colors that range from dull red to blindingly brilliant blue-white as the temperature increases.
(more…)














COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Image rendering bit depth
-
Photography basics: Color Temperature and White Balance
-
Glossary of Lighting Terms – cheat sheet
-
Principles of Animation with Alan Becker, Dermot OConnor and Shaun Keenan
-
Emmanuel Tsekleves – Writing Research Papers
-
Rec-2020 – TVs new color gamut standard used by Dolby Vision?
-
Canva bought Affinity – Now Affinity Photo and Affinity Designer are… GONE?!
-
59 AI Filmmaking Tools For Your Workflow
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
