


COMPOSITION
-
Composition – These are the basic lighting techniques you need to know for photography and film
Read more: Composition – These are the basic lighting techniques you need to know for photography and film
http://www.diyphotography.net/basic-lighting-techniques-need-know-photography-film/
Amongst the basic techniques, there’s…
1- Side lighting – Literally how it sounds, lighting a subject from the side when they’re faced toward you
2- Rembrandt lighting – Here the light is at around 45 degrees over from the front of the subject, raised and pointing down at 45 degrees
3- Back lighting – Again, how it sounds, lighting a subject from behind. This can help to add drama with silouettes
4- Rim lighting – This produces a light glowing outline around your subject
5- Key light – The main light source, and it’s not necessarily always the brightest light source
6- Fill light – This is used to fill in the shadows and provide detail that would otherwise be blackness
7- Cross lighting – Using two lights placed opposite from each other to light two subjects
-
Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental process
Read more: Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental processhttps://www.chrbutler.com/understanding-the-eye-mind-connection
The intricate relationship between the eyes and the brain, often termed the eye-mind connection, reveals that vision is predominantly a cognitive process. This understanding has profound implications for fields such as design, where capturing and maintaining attention is paramount. This essay delves into the nuances of visual perception, the brain’s role in interpreting visual data, and how this knowledge can be applied to effective design strategies.
This cognitive aspect of vision is evident in phenomena such as optical illusions, where the brain interprets visual information in a way that contradicts physical reality. These illusions underscore that what we “see” is not merely a direct recording of the external world but a constructed experience shaped by cognitive processes.
Understanding the cognitive nature of vision is crucial for effective design. Designers must consider how the brain processes visual information to create compelling and engaging visuals. This involves several key principles:
- Attention and Engagement
- Visual Hierarchy
- Cognitive Load Management
- Context and Meaning


















DESIGN

















COLOR
-
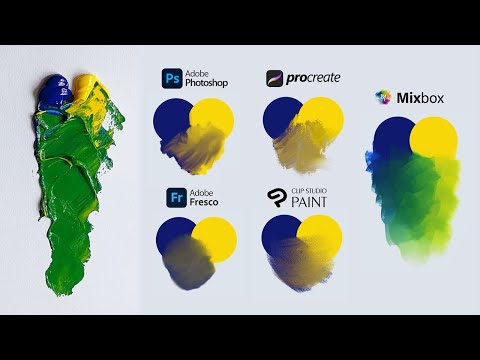
SecretWeapons MixBox – a practical library for paint-like digital color mixing
Read more: SecretWeapons MixBox – a practical library for paint-like digital color mixingInternally, Mixbox treats colors as real-life pigments using the Kubelka & Munk theory to predict realistic color behavior.
https://scrtwpns.com/mixbox/painter/
https://scrtwpns.com/mixbox.pdf
https://github.com/scrtwpns/mixbox
https://scrtwpns.com/mixbox/docs/
-
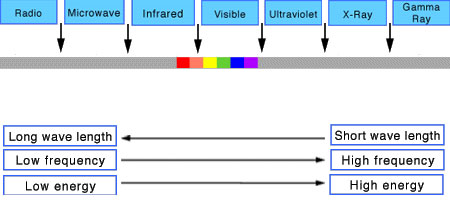
Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminance
Read more: Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminancehttps://www.translatorscafe.com/unit-converter/en-US/illumination/1-11/

The power output of a light source is measured using the unit of watts W. This is a direct measure to calculate how much power the light is going to drain from your socket and it is not relatable to the light brightness itself.
The amount of energy emitted from it per second. That energy comes out in a form of photons which we can crudely represent with rays of light coming out of the source. The higher the power the more rays emitted from the source in a unit of time.
Not all energy emitted is visible to the human eye, so we often rely on photometric measurements, which takes in account the sensitivity of human eye to different wavelenghts


Details in the post
(more…) -
Brett Jones / Phil Reyneri (Lightform) / Philipp7pc: The study of Projection Mapping through Projectors
Read more: Brett Jones / Phil Reyneri (Lightform) / Philipp7pc: The study of Projection Mapping through Projectors


Video Projection Tool Software
https://hcgilje.wordpress.com/vpt/
https://www.projectorpoint.co.uk/news/how-bright-should-my-projector-be/
http://www.adwindowscreens.com/the_calculator/
heavym
https://heavym.net/en/
MadMapper
https://madmapper.com/
-
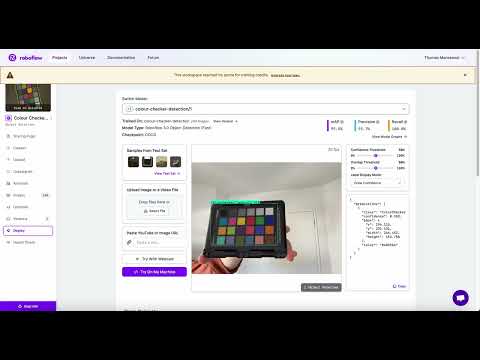
Is a MacBeth Colour Rendition Chart the Safest Way to Calibrate a Camera?
Read more: Is a MacBeth Colour Rendition Chart the Safest Way to Calibrate a Camera?www.colour-science.org/posts/the-colorchecker-considered-mostly-harmless/
“Unless you have all the relevant spectral measurements, a colour rendition chart should not be used to perform colour-correction of camera imagery but only for white balancing and relative exposure adjustments.”
“Using a colour rendition chart for colour-correction might dramatically increase error if the scene light source spectrum is different from the illuminant used to compute the colour rendition chart’s reference values.”
“other factors make using a colour rendition chart unsuitable for camera calibration:
– Uncontrolled geometry of the colour rendition chart with the incident illumination and the camera.
– Unknown sample reflectances and ageing as the colour of the samples vary with time.
– Low samples count.
– Camera noise and flare.
– Etc…“Those issues are well understood in the VFX industry, and when receiving plates, we almost exclusively use colour rendition charts to white balance and perform relative exposure adjustments, i.e. plate neutralisation.”
-
Thomas Mansencal – Colour Science for Python
Read more: Thomas Mansencal – Colour Science for Pythonhttps://thomasmansencal.substack.com/p/colour-science-for-python
https://www.colour-science.org/
Colour is an open-source Python package providing a comprehensive number of algorithms and datasets for colour science. It is freely available under the BSD-3-Clause terms.











LIGHTING
-
About green screens
Read more: About green screenshackaday.com/2015/02/07/how-green-screen-worked-before-computers/
www.newtek.com/blog/tips/best-green-screen-materials/
www.chromawall.com/blog//chroma-key-green

Chroma Key Green, the color of green screens is also known as Chroma Green and is valued at approximately 354C in the Pantone color matching system (PMS).
Chroma Green can be broken down in many different ways. Here is green screen green as other values useful for both physical and digital production:
Green Screen as RGB Color Value: 0, 177, 64
Green Screen as CMYK Color Value: 81, 0, 92, 0
Green Screen as Hex Color Value: #00b140
Green Screen as Websafe Color Value: #009933Chroma Key Green is reasonably close to an 18% gray reflectance.
Illuminate your green screen with an uniform source with less than 2/3 EV variation.
The level of brightness at any given f-stop should be equivalent to a 90% white card under the same lighting. -
Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminance
Read more: Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminancehttps://www.translatorscafe.com/unit-converter/en-US/illumination/1-11/
The power output of a light source is measured using the unit of watts W. This is a direct measure to calculate how much power the light is going to drain from your socket and it is not relatable to the light brightness itself.
The amount of energy emitted from it per second. That energy comes out in a form of photons which we can crudely represent with rays of light coming out of the source. The higher the power the more rays emitted from the source in a unit of time.
Not all energy emitted is visible to the human eye, so we often rely on photometric measurements, which takes in account the sensitivity of human eye to different wavelenghts
Details in the post
(more…) -
Aputure AL-F7 – dimmable Led Video Light, CRI95+, 3200-9500K
Read more: Aputure AL-F7 – dimmable Led Video Light, CRI95+, 3200-9500KHigh CRI of ≥95
256 LEDs with 45° beam angle
3200 to 9500K variable color temperature
1 to 100% Stepless Dimming, 1500 Lux Brightness at 3.3′
LCD Info Screen. Powered by an L-series battery, D-Tap, or USB-C
Because the light has a variable color range of 3200 to 9500K, when the light is set to 5500K (daylight balanced) both sets of LEDs are on at full, providing the maximum brightness from this fixture when compared to using the light at 3200 or 9500K.
The LCD screen provides information on the fixture’s output as well as the charge state of the battery. The screen also indicates whether the adjustment knob is controlling brightness or color temperature. To switch from brightness to CCT or CCT to brightness, just apply a short press to the adjustment knob.
The included cold shoe ball joint adapter enables mounting the light to your camera’s accessory shoe via the 1/4″-20 threaded hole on the fixture. In addition, the bottom of the cold shoe foot features a 3/8″-16 threaded hole, and includes a 3/8″-16 to 1/4″-20 reducing bushing.


-
Neural Microfacet Fields for Inverse Rendering
Read more: Neural Microfacet Fields for Inverse Renderinghttps://half-potato.gitlab.io/posts/nmf/

-
Outpost VFX lighting tips
Read more: Outpost VFX lighting tipswww.outpost-vfx.com/en/news/18-pro-tips-and-tricks-for-lighting
Get as much information regarding your plate lighting as possible
- Always use a reference
- Replicate what is happening in real life
- Invest into a solid HDRI
- Start Simple
- Observe real world lighting, photography and cinematography
- Don’t neglect the theory
- Learn the difference between realism and photo-realism.
- Keep your scenes organised














COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
ComfyDock – The Easiest (Free) Way to Safely Run ComfyUI Sessions in a Boxed Container
-
VFX pipeline – Render Wall Farm management topics
-
Daniele Tosti Interview for the magazine InCG, Taiwan, Issue 28, 201609
-
copypastecharacter.com – alphabets, special characters, alt codes and symbols library
-
AI and the Law – studiobinder.com – What is Fair Use: Definition, Policies, Examples and More
-
MiniTunes V1 – Free MP3 library app
-
QR code logos
-
Black Forest Labs released FLUX.1 Kontext
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
