


COMPOSITION
-
Composition – 5 tips for creating perfect cinematic lighting and making your work look stunning
Read more: Composition – 5 tips for creating perfect cinematic lighting and making your work look stunning
http://www.diyphotography.net/5-tips-creating-perfect-cinematic-lighting-making-work-look-stunning/
1. Learn the rules of lighting
2. Learn when to break the rules
3. Make your key light larger
4. Reverse keying
5. Always be backlighting
-
7 Commandments of Film Editing and composition
Read more: 7 Commandments of Film Editing and composition
1. Watch every frame of raw footage twice. On the second time, take notes. If you don’t do this and try to start developing a scene premature, then it’s a big disservice to yourself and to the director, actors and production crew.
2. Nurture the relationships with the director. You are the secondary person in the relationship. Be calm and continually offer solutions. Get the main intention of the film as soon as possible from the director.
3. Organize your media so that you can find any shot instantly.
4. Factor in extra time for renders, exports, errors and crashes.
5. Attempt edits and ideas that shouldn’t work. It just might work. Until you do it and watch it, you won’t know. Don’t rule out ideas just because they don’t make sense in your mind.
6. Spend more time on your audio. It’s the glue of your edit. AUDIO SAVES EVERYTHING. Create fluid and seamless audio under your video.
7. Make cuts for the scene, but always in context for the whole film. Have a macro and a micro view at all times.
-
Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental process
Read more: Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental processhttps://www.chrbutler.com/understanding-the-eye-mind-connection
The intricate relationship between the eyes and the brain, often termed the eye-mind connection, reveals that vision is predominantly a cognitive process. This understanding has profound implications for fields such as design, where capturing and maintaining attention is paramount. This essay delves into the nuances of visual perception, the brain’s role in interpreting visual data, and how this knowledge can be applied to effective design strategies.
This cognitive aspect of vision is evident in phenomena such as optical illusions, where the brain interprets visual information in a way that contradicts physical reality. These illusions underscore that what we “see” is not merely a direct recording of the external world but a constructed experience shaped by cognitive processes.
Understanding the cognitive nature of vision is crucial for effective design. Designers must consider how the brain processes visual information to create compelling and engaging visuals. This involves several key principles:
- Attention and Engagement
- Visual Hierarchy
- Cognitive Load Management
- Context and Meaning














DESIGN
COLOR
-
3D Lighting Tutorial by Amaan Kram
Read more: 3D Lighting Tutorial by Amaan Kramhttp://www.amaanakram.com/lightingT/part1.htm
The goals of lighting in 3D computer graphics are more or less the same as those of real world lighting.
Lighting serves a basic function of bringing out, or pushing back the shapes of objects visible from the camera’s view.
It gives a two-dimensional image on the monitor an illusion of the third dimension-depth.But it does not just stop there. It gives an image its personality, its character. A scene lit in different ways can give a feeling of happiness, of sorrow, of fear etc., and it can do so in dramatic or subtle ways. Along with personality and character, lighting fills a scene with emotion that is directly transmitted to the viewer.
Trying to simulate a real environment in an artificial one can be a daunting task. But even if you make your 3D rendering look absolutely photo-realistic, it doesn’t guarantee that the image carries enough emotion to elicit a “wow” from the people viewing it.
Making 3D renderings photo-realistic can be hard. Putting deep emotions in them can be even harder. However, if you plan out your lighting strategy for the mood and emotion that you want your rendering to express, you make the process easier for yourself.
Each light source can be broken down in to 4 distinct components and analyzed accordingly.
· Intensity
· Direction
· Color
· SizeThe overall thrust of this writing is to produce photo-realistic images by applying good lighting techniques.

-
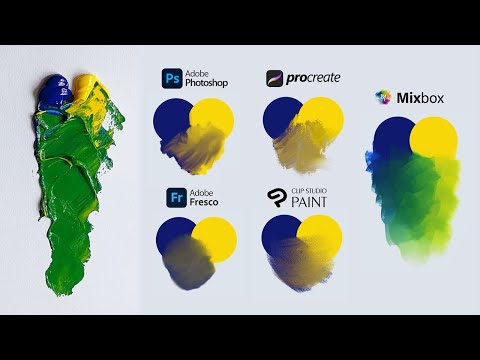
SecretWeapons MixBox – a practical library for paint-like digital color mixing
Read more: SecretWeapons MixBox – a practical library for paint-like digital color mixingInternally, Mixbox treats colors as real-life pigments using the Kubelka & Munk theory to predict realistic color behavior.
https://scrtwpns.com/mixbox/painter/
https://scrtwpns.com/mixbox.pdf
https://github.com/scrtwpns/mixbox
https://scrtwpns.com/mixbox/docs/
-
The Forbidden colors – Red-Green & Blue-Yellow: The Stunning Colors You Can’t See
Read more: The Forbidden colors – Red-Green & Blue-Yellow: The Stunning Colors You Can’t Seewww.livescience.com/17948-red-green-blue-yellow-stunning-colors.html

While the human eye has red, green, and blue-sensing cones, those cones are cross-wired in the retina to produce a luminance channel plus a red-green and a blue-yellow channel, and it’s data in that color space (known technically as “LAB”) that goes to the brain. That’s why we can’t perceive a reddish-green or a yellowish-blue, whereas such colors can be represented in the RGB color space used by digital cameras.
https://en.rockcontent.com/blog/the-use-of-yellow-in-data-design
The back of the retina is covered in light-sensitive neurons known as cone cells and rod cells. There are three types of cone cells, each sensitive to different ranges of light. These ranges overlap, but for convenience the cones are referred to as blue (short-wavelength), green (medium-wavelength), and red (long-wavelength). The rod cells are primarily used in low-light situations, so we’ll ignore those for now.
When light enters the eye and hits the cone cells, the cones get excited and send signals to the brain through the visual cortex. Different wavelengths of light excite different combinations of cones to varying levels, which generates our perception of color. You can see that the red cones are most sensitive to light, and the blue cones are least sensitive. The sensitivity of green and red cones overlaps for most of the visible spectrum.

Here’s how your brain takes the signals of light intensity from the cones and turns it into color information. To see red or green, your brain finds the difference between the levels of excitement in your red and green cones. This is the red-green channel.
To get “brightness,” your brain combines the excitement of your red and green cones. This creates the luminance, or black-white, channel. To see yellow or blue, your brain then finds the difference between this luminance signal and the excitement of your blue cones. This is the yellow-blue channel.
From the calculations made in the brain along those three channels, we get four basic colors: blue, green, yellow, and red. Seeing blue is what you experience when low-wavelength light excites the blue cones more than the green and red.
Seeing green happens when light excites the green cones more than the red cones. Seeing red happens when only the red cones are excited by high-wavelength light.
Here’s where it gets interesting. Seeing yellow is what happens when BOTH the green AND red cones are highly excited near their peak sensitivity. This is the biggest collective excitement that your cones ever have, aside from seeing pure white.
Notice that yellow occurs at peak intensity in the graph to the right. Further, the lens and cornea of the eye happen to block shorter wavelengths, reducing sensitivity to blue and violet light.
-
HDR and Color
Read more: HDR and Colorhttps://www.soundandvision.com/content/nits-and-bits-hdr-and-color
In HD we often refer to the range of available colors as a color gamut. Such a color gamut is typically plotted on a two-dimensional diagram, called a CIE chart, as shown in at the top of this blog. Each color is characterized by its x/y coordinates.

Good enough for government work, perhaps. But for HDR, with its higher luminance levels and wider color, the gamut becomes three-dimensional.

For HDR the color gamut therefore becomes a characteristic we now call the color volume. It isn’t easy to show color volume on a two-dimensional medium like the printed page or a computer screen, but one method is shown below. As the luminance becomes higher, the picture eventually turns to white. As it becomes darker, it fades to black. The traditional color gamut shown on the CIE chart is simply a slice through this color volume at a selected luminance level, such as 50%.
Three different color volumes—we still refer to them as color gamuts though their third dimension is important—are currently the most significant. The first is BT.709 (sometimes referred to as Rec.709), the color gamut used for pre-UHD/HDR formats, including standard HD.
The largest is known as BT.2020; it encompasses (roughly) the range of colors visible to the human eye (though ET might find it insufficient!).
Between these two is the color gamut used in digital cinema, known as DCI-P3.

sRGB

D65













LIGHTING
-
StudioBinder.com – CRI color rendering index
Read more: StudioBinder.com – CRI color rendering indexwww.studiobinder.com/blog/what-is-color-rendering-index
“The Color Rendering Index is a measurement of how faithfully a light source reveals the colors of whatever it illuminates, it describes the ability of a light source to reveal the color of an object, as compared to the color a natural light source would provide. The highest possible CRI is 100. A CRI of 100 generally refers to a perfect black body, like a tungsten light source or the sun. ”


www.pixelsham.com/2021/04/28/types-of-film-lights-and-their-efficiency
-
Capturing the world in HDR for real time projects – Call of Duty: Advanced Warfare
Read more: Capturing the world in HDR for real time projects – Call of Duty: Advanced WarfareReal-World Measurements for Call of Duty: Advanced Warfare
www.activision.com/cdn/research/Real_World_Measurements_for_Call_of_Duty_Advanced_Warfare.pdf
Local version
Real_World_Measurements_for_Call_of_Duty_Advanced_Warfare.pdf

-
IES Light Profiles and editing software
Read more: IES Light Profiles and editing softwarehttp://www.derekjenson.com/3d-blog/ies-light-profiles
https://ieslibrary.com/en/browse#ies
https://leomoon.com/store/shaders/ies-lights-pack
https://docs.arnoldrenderer.com/display/a5afmug/ai+photometric+light
IES profiles are useful for creating life-like lighting, as they can represent the physical distribution of light from any light source.
The IES format was created by the Illumination Engineering Society, and most lighting manufacturers provide IES profile for the lights they manufacture.


-
Photography basics: Exposure Value vs Photographic Exposure vs Il/Luminance vs Pixel luminance measurements
Read more: Photography basics: Exposure Value vs Photographic Exposure vs Il/Luminance vs Pixel luminance measurementsAlso see: https://www.pixelsham.com/2015/05/16/how-aperture-shutter-speed-and-iso-affect-your-photos/
In photography, exposure value (EV) is a number that represents a combination of a camera’s shutter speed and f-number, such that all combinations that yield the same exposure have the same EV (for any fixed scene luminance).
The EV concept was developed in an attempt to simplify choosing among combinations of equivalent camera settings. Although all camera settings with the same EV nominally give the same exposure, they do not necessarily give the same picture. EV is also used to indicate an interval on the photographic exposure scale. 1 EV corresponding to a standard power-of-2 exposure step, commonly referred to as a stop
EV 0 corresponds to an exposure time of 1 sec and a relative aperture of f/1.0. If the EV is known, it can be used to select combinations of exposure time and f-number.Note EV does not equal to photographic exposure. Photographic Exposure is defined as how much light hits the camera’s sensor. It depends on the camera settings mainly aperture and shutter speed. Exposure value (known as EV) is a number that represents the exposure setting of the camera.
Thus, strictly, EV is not a measure of luminance (indirect or reflected exposure) or illuminance (incidentl exposure); rather, an EV corresponds to a luminance (or illuminance) for which a camera with a given ISO speed would use the indicated EV to obtain the nominally correct exposure. Nonetheless, it is common practice among photographic equipment manufacturers to express luminance in EV for ISO 100 speed, as when specifying metering range or autofocus sensitivity.
The exposure depends on two things: how much light gets through the lenses to the camera’s sensor and for how long the sensor is exposed. The former is a function of the aperture value while the latter is a function of the shutter speed. Exposure value is a number that represents this potential amount of light that could hit the sensor. It is important to understand that exposure value is a measure of how exposed the sensor is to light and not a measure of how much light actually hits the sensor. The exposure value is independent of how lit the scene is. For example a pair of aperture value and shutter speed represents the same exposure value both if the camera is used during a very bright day or during a dark night.
Each exposure value number represents all the possible shutter and aperture settings that result in the same exposure. Although the exposure value is the same for different combinations of aperture values and shutter speeds the resulting photo can be very different (the aperture controls the depth of field while shutter speed controls how much motion is captured).
EV 0.0 is defined as the exposure when setting the aperture to f-number 1.0 and the shutter speed to 1 second. All other exposure values are relative to that number. Exposure values are on a base two logarithmic scale. This means that every single step of EV – plus or minus 1 – represents the exposure (actual light that hits the sensor) being halved or doubled.Formulas
(more…) -
Arto T. – A workflow for creating photorealistic, equirectangular 360° panoramas in ComfyUI using Flux
Read more: Arto T. – A workflow for creating photorealistic, equirectangular 360° panoramas in ComfyUI using Fluxhttps://civitai.com/models/735980/flux-equirectangular-360-panorama
https://civitai.com/models/745010?modelVersionId=833115
The trigger phrase is “equirectangular 360 degree panorama”. I would avoid saying “spherical projection” since that tends to result in non-equirectangular spherical images.
Image resolution should always be a 2:1 aspect ratio. 1024 x 512 or 1408 x 704 work quite well and were used in the training data. 2048 x 1024 also works.
I suggest using a weight of 0.5 – 1.5. If you are having issues with the image generating too flat instead of having the necessary spherical distortion, try increasing the weight above 1, though this could negatively impact small details of the image. For Flux guidance, I recommend a value of about 2.5 for realistic scenes.
8-bit output at the moment


-
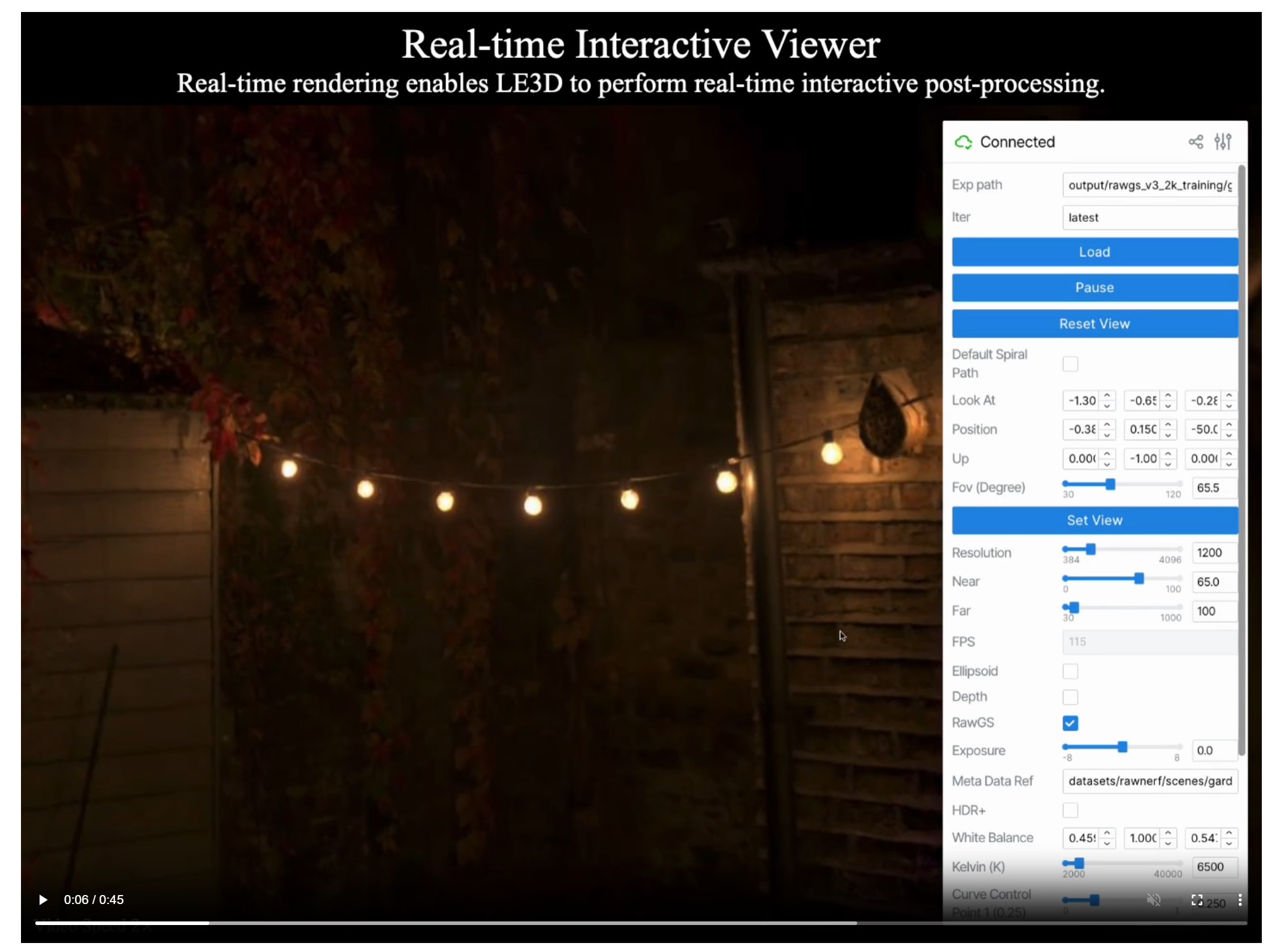
Lighting Every Darkness with 3DGS: Fast Training and Real-Time Rendering and Denoising for HDR View Synthesis
Read more: Lighting Every Darkness with 3DGS: Fast Training and Real-Time Rendering and Denoising for HDR View Synthesishttps://srameo.github.io/projects/le3d/
LE3D is a method for real-time HDR view synthesis from RAW images. It is particularly effective for nighttime scenes.
https://github.com/Srameo/LE3D










COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
The Perils of Technical Debt – Understanding Its Impact on Security, Usability, and Stability
-
How does Stable Diffusion work?
-
Film Production walk-through – pipeline – I want to make a … movie
-
Guide to Prompt Engineering
-
Types of AI Explained in a few Minutes – AI Glossary
-
3D Gaussian Splatting step by step beginner course
-
4dv.ai – Remote Interactive 3D Holographic Presentation Technology and System running on the PlayCanvas engine
-
AI Search – Find The Best AI Tools & Apps
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
