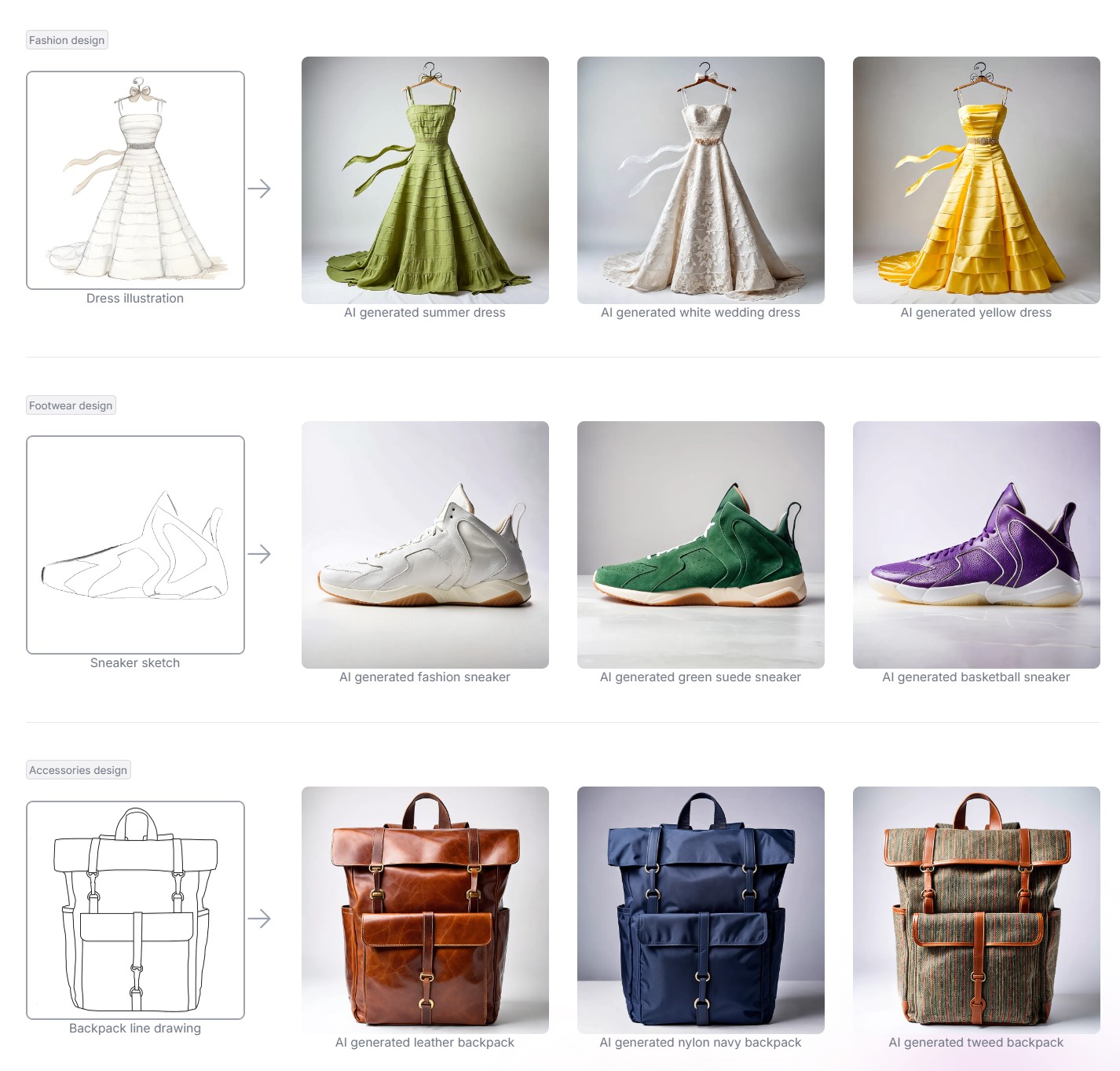
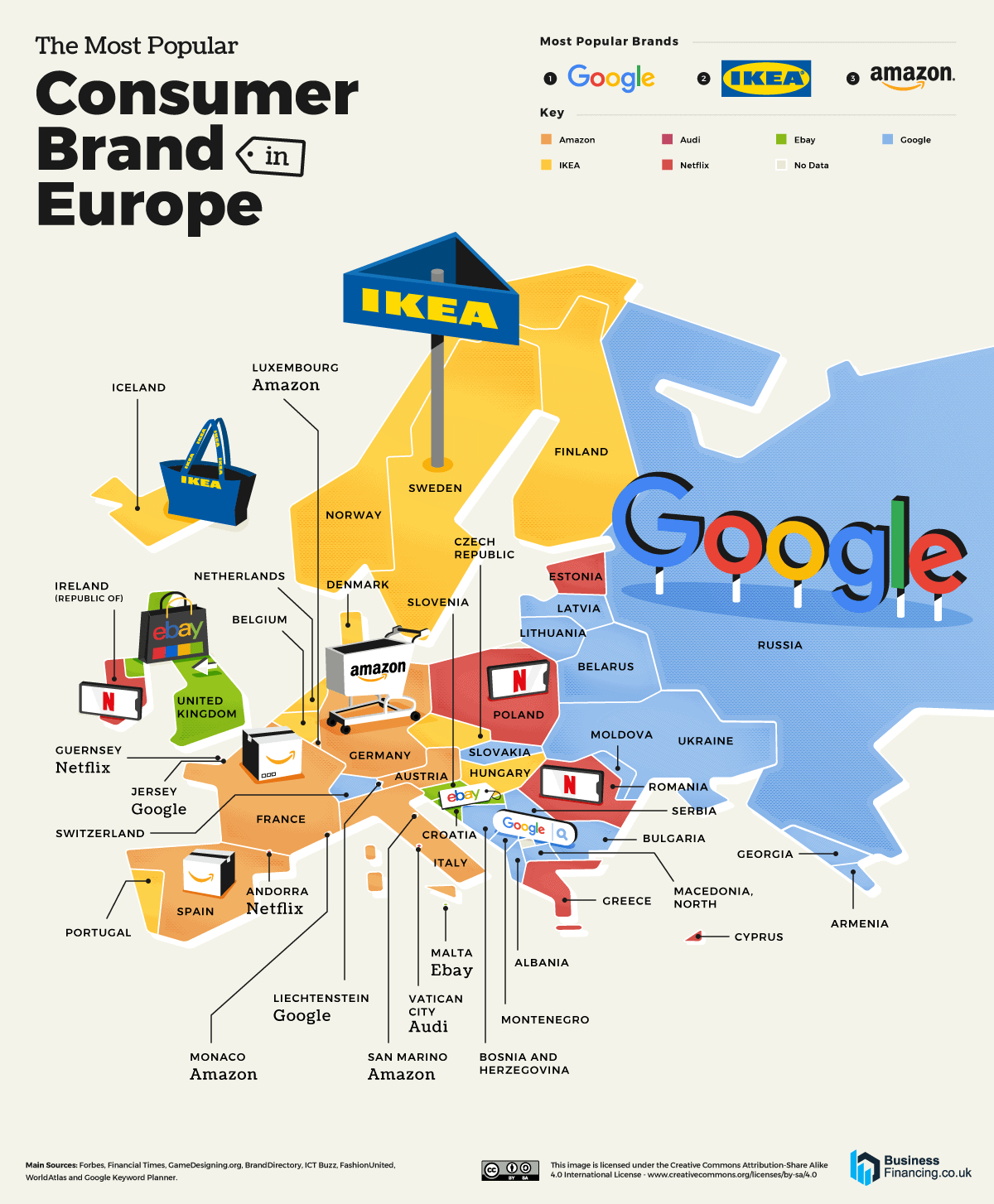
The intricate relationship between the eyes and the brain, often termed the eye-mind connection, reveals that vision is predominantly a cognitive process. This understanding has profound implications for fields such as design, where capturing and maintaining attention is paramount. This essay delves into the nuances of visual perception, the brain’s role in interpreting visual data, and how this knowledge can be applied to effective design strategies.
This cognitive aspect of vision is evident in phenomena such as optical illusions, where the brain interprets visual information in a way that contradicts physical reality. These illusions underscore that what we “see” is not merely a direct recording of the external world but a constructed experience shaped by cognitive processes.
Understanding the cognitive nature of vision is crucial for effective design. Designers must consider how the brain processes visual information to create compelling and engaging visuals. This involves several key principles:
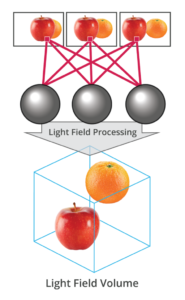
The primary goal of physically-based rendering (PBR) is to create a simulation that accurately reproduces the imaging process of electro-magnetic spectrum radiation incident to an observer. This simulation should be indistinguishable from reality for a similar observer.
Because a camera is not sensitive to incident light the same way than a human observer, the images it captures are transformed to be colorimetric. A project might require infrared imaging simulation, a portion of the electro-magnetic spectrum that is invisible to us. Radically different observers might image the same scene but the act of observing does not change the intrinsic properties of the objects being imaged. Consequently, the physical modelling of the virtual scene should be independent of the observer.
“Fix your gaze on the black dot on the left side of this image. But wait! Finish reading this paragraph first. As you gaze at the left dot, try to answer this question: In what direction is the object on the right moving? Is it drifting diagonally, or is it moving up and down?”
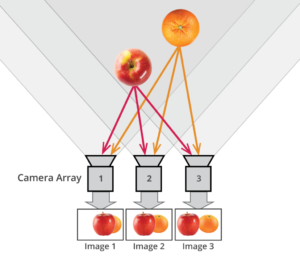
A number of problems in computer vision and related fields would be mitigated if camera spectral sensitivities were known. As consumer cameras are not designed for high-precision visual tasks, manufacturers do not disclose spectral sensitivities. Their estimation requires a costly optical setup, which triggered researchers to come up with numerous indirect methods that aim to lower cost and complexity by using color targets. However, the use of color targets gives rise to new complications that make the estimation more difficult, and consequently, there currently exists no simple, low-cost, robust go-to method for spectral sensitivity estimation that non-specialized research labs can adopt. Furthermore, even if not limited by hardware or cost, researchers frequently work with imagery from multiple cameras that they do not have in their possession.
To provide a practical solution to this problem, we propose a framework for spectral sensitivity estimation that not only does not require any hardware (including a color target), but also does not require physical access to the camera itself. Similar to other work, we formulate an optimization problem that minimizes a two-term objective function: a camera-specific term from a system of equations, and a universal term that bounds the solution space.
Different than other work, we utilize publicly available high-quality calibration data to construct both terms. We use the colorimetric mapping matrices provided by the Adobe DNG Converter to formulate the camera-specific system of equations, and constrain the solutions using an autoencoder trained on a database of ground-truth curves. On average, we achieve reconstruction errors as low as those that can arise due to manufacturing imperfections between two copies of the same camera. We provide predicted sensitivities for more than 1,000 cameras that the Adobe DNG Converter currently supports, and discuss which tasks can become trivial when camera responses are available.
In color technology, color depth also known as bit depth, is either the number of bits used to indicate the color of a single pixel, OR the number of bits used for each color component of a single pixel.
When referring to a pixel, the concept can be defined as bits per pixel (bpp).
When referring to a color component, the concept can be defined as bits per component, bits per channel, bits per color (all three abbreviated bpc), and also bits per pixel component, bits per color channel or bits per sample (bps). Modern standards tend to use bits per component, but historical lower-depth systems used bits per pixel more often.
Color depth is only one aspect of color representation, expressing the precision with which the amount of each primary can be expressed; the other aspect is how broad a range of colors can be expressed (the gamut). The definition of both color precision and gamut is accomplished with a color encoding specification which assigns a digital code value to a location in a color space.
A measure of how large the object appears to an observer looking from that point. Thus. A measure for objects in the sky. Useful to retuen the size of the sun and moon… and in perspective, how much of their contribution to lighting. Solid angle can be represented in ‘angular diameter’ as well.
A solid angle is expressed in a dimensionless unit called a steradian (symbol: sr). By default in terms of the total celestial sphere and before atmospheric’s scattering, the Sun and the Moon subtend fractional areas of 0.000546% (Sun) and 0.000531% (Moon).
On earth the sun is likely closer to 0.00011 solid angle after athmospheric scattering. The sun as perceived from earth has a diameter of 0.53 degrees. This is about 0.000064 solid angle.
The mean angular diameter of the full moon is 2q = 0.52° (it varies with time around that average, by about 0.009°). This translates into a solid angle of 0.0000647 sr, which means that the whole night sky covers a solid angle roughly one hundred thousand times greater than the full moon.
The apparent size of an object as seen by an observer; expressed in units of degrees (of arc), arc minutes, or arc seconds. The moon, as viewed from the Earth, has an angular diameter of one-half a degree.
The angle covered by the diameter of the full moon is about 31 arcmin or 1/2°, so astronomers would say the Moon’s angular diameter is 31 arcmin, or the Moon subtends an angle of 31 arcmin.
import math,sys
def Exposure2Intensity(exposure):
exp = float(exposure)
result = math.pow(2,exp)
print(result)
Exposure2Intensity(0)
def Intensity2Exposure(intensity):
inarg = float(intensity)
if inarg == 0:
print("Exposure of zero intensity is undefined.")
return
if inarg < 1e-323:
inarg = max(inarg, 1e-323)
print("Exposure of negative intensities is undefined. Clamping to a very small value instead (1e-323)")
result = math.log(inarg, 2)
print(result)
Intensity2Exposure(0.1)
Why Exposure?
Exposure is a stop value that multiplies the intensity by 2 to the power of the stop. Increasing exposure by 1 results in double the amount of light.
Artists think in “stops.” Doubling or halving brightness is easy math and common in grading and look-dev. Exposure counts doublings in whole stops:
+1 stop = ×2 brightness
−1 stop = ×0.5 brightness
This gives perceptually even controls across both bright and dark values.
Why Intensity?
Intensity is linear. It’s what render engines and compositors expect when:
Summing values
Averaging pixels
Multiplying or filtering pixel data
Use intensity when you need the actual math on pixel/light data.
Formulas (from your Python)
Intensity from exposure: intensity = 2**exposure
Exposure from intensity: exposure = log₂(intensity)
Guardrails:
Intensity must be > 0 to compute exposure.
If intensity = 0 → exposure is undefined.
Clamp tiny values (e.g. 1e−323) before using log₂.
Use Exposure (stops) when…
You want artist-friendly sliders (−5…+5 stops)
Adjusting look-dev or grading in even stops
Matching plates with quick ±1 stop tweaks
Tweening brightness changes smoothly across ranges
Use Intensity (linear) when…
Storing raw pixel/light values
Multiplying textures or lights by a gain
Performing sums, averages, and filters
Feeding values to render engines expecting linear data
Examples
+2 stops → 2**2 = 4.0 (×4)
+1 stop → 2**1 = 2.0 (×2)
0 stop → 2**0 = 1.0 (×1)
−1 stop → 2**(−1) = 0.5 (×0.5)
−2 stops → 2**(−2) = 0.25 (×0.25)
Intensity 0.1 → exposure = log₂(0.1) ≈ −3.32
Rule of thumb
Think in stops (exposure) for controls and matching. Compute in linear (intensity) for rendering and math.
Chroma Key Green, the color of green screens is also known as Chroma Green and is valued at approximately 354C in the Pantone color matching system (PMS).
Chroma Green can be broken down in many different ways. Here is green screen green as other values useful for both physical and digital production:
Green Screen as RGB Color Value: 0, 177, 64
Green Screen as CMYK Color Value: 81, 0, 92, 0
Green Screen as Hex Color Value: #00b140
Green Screen as Websafe Color Value: #009933
Chroma Key Green is reasonably close to an 18% gray reflectance.
Illuminate your green screen with an uniform source with less than 2/3 EV variation.
The level of brightness at any given f-stop should be equivalent to a 90% white card under the same lighting.
DiT360 is a framework for high-quality panoramic image generation, leveraging both perspective and panoramic data in a hybrid training scheme. It adopts a two-level strategy—image-level cross-domain guidance and token-level hybrid supervision—to enhance perceptual realism and geometric fidelity.
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.