


COMPOSITION
-
StudioBinder – Roger Deakins on How to Choose a Camera Lens — Cinematography Composition Techniques
Read more: StudioBinder – Roger Deakins on How to Choose a Camera Lens — Cinematography Composition Techniques
https://www.studiobinder.com/blog/camera-lens-buying-guide/
https://www.studiobinder.com/blog/e-books/camera-lenses-explained-volume-1-ebook
-
SlowMoVideo – How to make a slow motion shot with the open source program
Read more: SlowMoVideo – How to make a slow motion shot with the open source programhttp://slowmovideo.granjow.net/
slowmoVideo is an OpenSource program that creates slow-motion videos from your footage.
Slow motion cinematography is the result of playing back frames for a longer duration than they were exposed. For example, if you expose 240 frames of film in one second, then play them back at 24 fps, the resulting movie is 10 times longer (slower) than the original filmed event….
Film cameras are relatively simple mechanical devices that allow you to crank up the speed to whatever rate the shutter and pull-down mechanism allow. Some film cameras can operate at 2,500 fps or higher (although film shot in these cameras often needs some readjustment in postproduction). Video, on the other hand, is always captured, recorded, and played back at a fixed rate, with a current limit around 60fps. This makes extreme slow motion effects harder to achieve (and less elegant) on video, because slowing down the video results in each frame held still on the screen for a long time, whereas with high-frame-rate film there are plenty of frames to fill the longer durations of time. On video, the slow motion effect is more like a slide show than smooth, continuous motion.
One obvious solution is to shoot film at high speed, then transfer it to video (a case where film still has a clear advantage, sorry George). Another possibility is to cross dissolve or blur from one frame to the next. This adds a smooth transition from one still frame to the next. The blur reduces the sharpness of the image, and compared to slowing down images shot at a high frame rate, this is somewhat of a cheat. However, there isn’t much you can do about it until video can be recorded at much higher rates. Of course, many film cameras can’t shoot at high frame rates either, so the whole super-slow-motion endeavor is somewhat specialized no matter what medium you are using. (There are some high speed digital cameras available now that allow you to capture lots of digital frames directly to your computer, so technology is starting to catch up with film. However, this feature isn’t going to appear in consumer camcorders any time soon.)
-
Composition – 5 tips for creating perfect cinematic lighting and making your work look stunning
Read more: Composition – 5 tips for creating perfect cinematic lighting and making your work look stunning
http://www.diyphotography.net/5-tips-creating-perfect-cinematic-lighting-making-work-look-stunning/
1. Learn the rules of lighting
2. Learn when to break the rules
3. Make your key light larger
4. Reverse keying
5. Always be backlighting













DESIGN
-
James Gerde – The way the leaves dance in the rain
Read more: James Gerde – The way the leaves dance in the rainhttps://www.instagram.com/gerdegotit/reel/C6s-2r2RgSu/
Since spending a lot of time recently with SDXL I’ve since made my way back to SD 1.5
While the models overall have less fidelity. There is just no comparing to the current motion models we have available for animatediff with 1.5 models.
To date this is one of my favorite pieces. Not because I think it’s even the best it can be. But because the workflow adjustments unlocked some very important ideas I can’t wait to try out.
Performance by @silkenkelly and @itxtheballerina on IG















COLOR
-
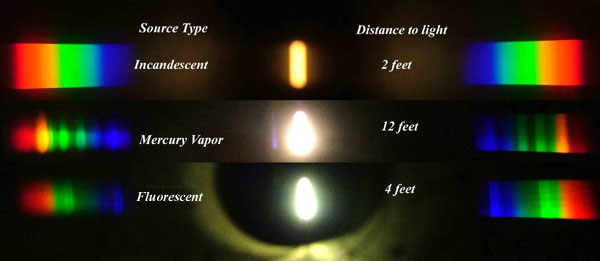
Space bodies’ components and light spectroscopy
Read more: Space bodies’ components and light spectroscopywww.plutorules.com/page-111-space-rocks.html
This help’s us understand the composition of components in/on solar system bodies.
Dips in the observed light spectrum, also known as, lines of absorption occur as gasses absorb energy from light at specific points along the light spectrum.
These dips or darkened zones (lines of absorption) leave a finger print which identify elements and compounds.
In this image the dark absorption bands appear as lines of emission which occur as the result of emitted not reflected (absorbed) light.
Lines of absorption
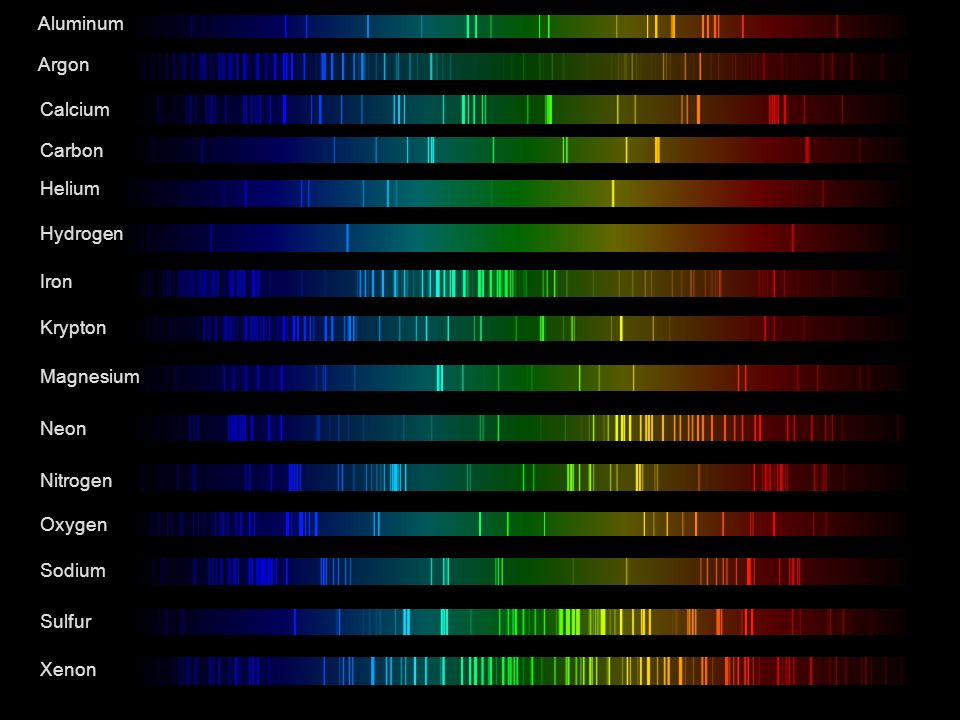 Lines of emission
Lines of emission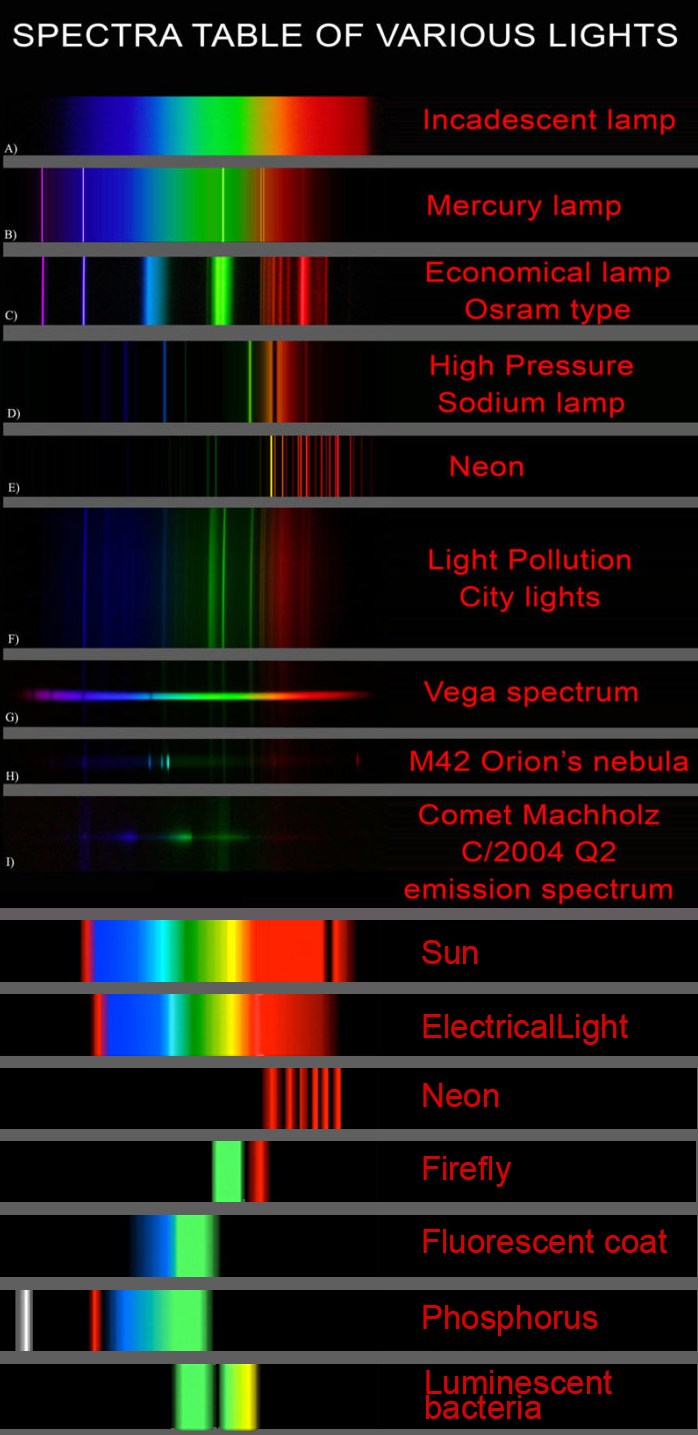


-
What is OLED and what can it do for your TV
Read more: What is OLED and what can it do for your TVhttps://www.cnet.com/news/what-is-oled-and-what-can-it-do-for-your-tv/
OLED stands for Organic Light Emitting Diode. Each pixel in an OLED display is made of a material that glows when you jab it with electricity. Kind of like the heating elements in a toaster, but with less heat and better resolution. This effect is called electroluminescence, which is one of those delightful words that is big, but actually makes sense: “electro” for electricity, “lumin” for light and “escence” for, well, basically “essence.”
OLED TV marketing often claims “infinite” contrast ratios, and while that might sound like typical hyperbole, it’s one of the extremely rare instances where such claims are actually true. Since OLED can produce a perfect black, emitting no light whatsoever, its contrast ratio (expressed as the brightest white divided by the darkest black) is technically infinite.
OLED is the only technology capable of absolute blacks and extremely bright whites on a per-pixel basis. LCD definitely can’t do that, and even the vaunted, beloved, dearly departed plasma couldn’t do absolute blacks.

-
Yasuharu YOSHIZAWA – Comparison of sRGB vs ACREScg in Nuke
Read more: Yasuharu YOSHIZAWA – Comparison of sRGB vs ACREScg in NukeAnswering the question that is often asked, “Do I need to use ACEScg to display an sRGB monitor in the end?” (Demonstration shown at an in-house seminar)
Comparison of scanlineRender output with extreme color lights on color charts with sRGB/ACREScg in color – OCIO -working space in NukeDownload the Nuke script:
-
Brett Jones / Phil Reyneri (Lightform) / Philipp7pc: The study of Projection Mapping through Projectors
Read more: Brett Jones / Phil Reyneri (Lightform) / Philipp7pc: The study of Projection Mapping through Projectors


Video Projection Tool Software
https://hcgilje.wordpress.com/vpt/
https://www.projectorpoint.co.uk/news/how-bright-should-my-projector-be/
http://www.adwindowscreens.com/the_calculator/
heavym
https://heavym.net/en/
MadMapper
https://madmapper.com/
-
Weta Digital – Manuka Raytracer and Gazebo GPU renderers – pipeline
Read more: Weta Digital – Manuka Raytracer and Gazebo GPU renderers – pipelinehttps://jo.dreggn.org/home/2018_manuka.pdf
http://www.fxguide.com/featured/manuka-weta-digitals-new-renderer/

The Manuka rendering architecture has been designed in the spirit of the classic reyes rendering architecture. In its core, reyes is based on stochastic rasterisation of micropolygons, facilitating depth of field, motion blur, high geometric complexity,and programmable shading.
This is commonly achieved with Monte Carlo path tracing, using a paradigm often called shade-on-hit, in which the renderer alternates tracing rays with running shaders on the various ray hits. The shaders take the role of generating the inputs of the local material structure which is then used bypath sampling logic to evaluate contributions and to inform what further rays to cast through the scene.
Over the years, however, the expectations have risen substantially when it comes to image quality. Computing pictures which are indistinguishable from real footage requires accurate simulation of light transport, which is most often performed using some variant of Monte Carlo path tracing. Unfortunately this paradigm requires random memory accesses to the whole scene and does not lend itself well to a rasterisation approach at all.
Manuka is both a uni-directional and bidirectional path tracer and encompasses multiple importance sampling (MIS). Interestingly, and importantly for production character skin work, it is the first major production renderer to incorporate spectral MIS in the form of a new ‘Hero Spectral Sampling’ technique, which was recently published at Eurographics Symposium on Rendering 2014.
Manuka propose a shade-before-hit paradigm in-stead and minimise I/O strain (and some memory costs) on the system, leveraging locality of reference by running pattern generation shaders before we execute light transport simulation by path sampling, “compressing” any bvh structure as needed, and as such also limiting duplication of source data.
The difference with reyes is that instead of baking colors into the geometry like in Reyes, manuka bakes surface closures. This means that light transport is still calculated with path tracing, but all texture lookups etc. are done up-front and baked into the geometry.The main drawback with this method is that geometry has to be tessellated to its highest, stable topology before shading can be evaluated properly. As such, the high cost to first pixel. Even a basic 4 vertices square becomes a much more complex model with this approach.

Manuka use the RenderMan Shading Language (rsl) for programmable shading [Pixar Animation Studios 2015], but we do not invoke rsl shaders when intersecting a ray with a surface (often called shade-on-hit). Instead, we pre-tessellate and pre-shade all the input geometry in the front end of the renderer.
This way, we can efficiently order shading computations to sup-port near-optimal texture locality, vectorisation, and parallelism. This system avoids repeated evaluation of shaders at the same surface point, and presents a minimal amount of memory to be accessed during light transport time. An added benefit is that the acceleration structure for ray tracing (abounding volume hierarchy, bvh) is built once on the final tessellated geometry, which allows us to ray trace more efficiently than multi-level bvhs and avoids costly caching of on-demand tessellated micropolygons and the associated scheduling issues.For the shading reasons above, in terms of AOVs, the studio approach is to succeed at combining complex shading with ray paths in the render rather than pass a multi-pass render to compositing.
For the Spectral Rendering component. The light transport stage is fully spectral, using a continuously sampled wavelength which is traced with each path and used to apply the spectral camera sensitivity of the sensor. This allows for faithfully support any degree of observer metamerism as the camera footage they are intended to match as well as complex materials which require wavelength dependent phenomena such as diffraction, dispersion, interference, iridescence, or chromatic extinction and Rayleigh scattering in participating media.
As opposed to the original reyes paper, we use bilinear interpolation of these bsdf inputs later when evaluating bsdfs per pathv ertex during light transport4. This improves temporal stability of geometry which moves very slowly with respect to the pixel raster
In terms of the pipeline, everything rendered at Weta was already completely interwoven with their deep data pipeline. Manuka very much was written with deep data in mind. Here, Manuka not so much extends the deep capabilities, rather it fully matches the already extremely complex and powerful setup Weta Digital already enjoy with RenderMan. For example, an ape in a scene can be selected, its ID is available and a NUKE artist can then paint in 3D say a hand and part of the way up the neutral posed ape.
We called our system Manuka, as a respectful nod to reyes: we had heard a story froma former ILM employee about how reyes got its name from how fond the early Pixar people were of their lunches at Point Reyes, and decided to name our system after our surrounding natural environment, too. Manuka is a kind of tea tree very common in New Zealand which has very many very small leaves, in analogy to micropolygons ina tree structure for ray tracing. It also happens to be the case that Weta Digital’s main site is on Manuka Street.

-
RawTherapee – a free, open source, cross-platform raw image and HDRi processing program
Read more: RawTherapee – a free, open source, cross-platform raw image and HDRi processing program5.10 of this tool includes excellent tools to clean up cr2 and cr3 used on set to support HDRI processing.
Converting raw to AcesCG 32 bit tiffs with metadata.


-
Light and Matter : The 2018 theory of Physically-Based Rendering and Shading by Allegorithmic
Read more: Light and Matter : The 2018 theory of Physically-Based Rendering and Shading by Allegorithmicacademy.substance3d.com/courses/the-pbr-guide-part-1
academy.substance3d.com/courses/the-pbr-guide-part-2

 Local copy:
Local copy:








LIGHTING
-
7 Easy Portrait Lighting Setups
Read more: 7 Easy Portrait Lighting Setups
Butterfly
Loop
Rembrandt
Split
Rim
Broad
Short
-
Arto T. – A workflow for creating photorealistic, equirectangular 360° panoramas in ComfyUI using Flux
Read more: Arto T. – A workflow for creating photorealistic, equirectangular 360° panoramas in ComfyUI using Fluxhttps://civitai.com/models/735980/flux-equirectangular-360-panorama
https://civitai.com/models/745010?modelVersionId=833115
The trigger phrase is “equirectangular 360 degree panorama”. I would avoid saying “spherical projection” since that tends to result in non-equirectangular spherical images.
Image resolution should always be a 2:1 aspect ratio. 1024 x 512 or 1408 x 704 work quite well and were used in the training data. 2048 x 1024 also works.
I suggest using a weight of 0.5 – 1.5. If you are having issues with the image generating too flat instead of having the necessary spherical distortion, try increasing the weight above 1, though this could negatively impact small details of the image. For Flux guidance, I recommend a value of about 2.5 for realistic scenes.
8-bit output at the moment


-
Simulon – a Hollywood production studio app in the hands of an independent creator with access to consumer hardware, LDRi to HDRi through ML
Read more: Simulon – a Hollywood production studio app in the hands of an independent creator with access to consumer hardware, LDRi to HDRi through MLDivesh Naidoo: The video below was made with a live in-camera preview and auto-exposure matching, no camera solve, no HDRI capture and no manual compositing setup. Using the new Simulon phone app.
LDR to HDR through ML
https://simulon.typeform.com/betatest
(more…)Process example




















COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Glossary of Lighting Terms – cheat sheet
-
Ross Pettit on The Agile Manager – How tech firms went for prioritizing cash flow instead of talent (and artists)
-
HDRI Median Cut plugin
-
Jesse Zumstein – Jobs in games
-
Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacy
-
Want to build a start up company that lasts? Think three-layer cake
-
Top 3D Printing Website Resources
-
59 AI Filmmaking Tools For Your Workflow
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
