In the Illusion of Sex, two faces are perceived as male and female.
However, both faces are actually versions of the same androgynous face.
One face was created by increasing the contrast of the androgynous face, while the other face was created by decreasing the contrast. The face with more contrast is perceived as female, while the face with less contrast is perceived as male. The Illusion of Sex demonstrates that contrast is an important cue for perceiving the sex of a face, with greater contrast appearing feminine, and lesser contrast appearing masculine.
Russell, R. (2009) A sex difference in facial pigmentation and its exaggeration by cosmetics. Perception, (38)1211-1219.
5.10 of this tool includes excellent tools to clean up cr2 and cr3 used on set to support HDRI processing.
Converting raw to AcesCG 32 bit tiffs with metadata.
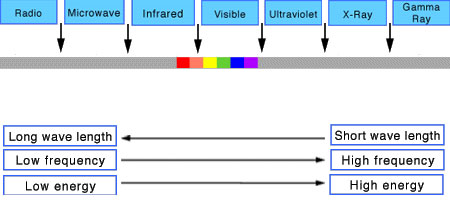
Spectral sensitivity of eye is influenced by light intensity. And the light intensity determines the level of activity of cones cell and rod cell. This is the main characteristic of human vision. Sensitivity to individual colors, in other words, wavelengths of the light spectrum, is explained by the RGB (red-green-blue) theory. This theory assumed that there are three kinds of cones. It’s selectively sensitive to red (700-630 nm), green (560-500 nm), and blue (490-450 nm) light. And their mutual interaction allow to perceive all colors of the spectrum.
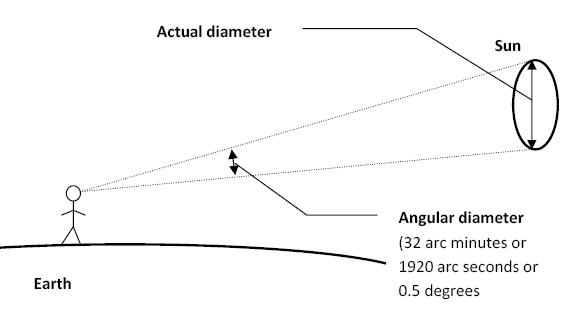
The cone angle of the sun refers to the angular diameter of the sun as observed from Earth, which is related to the apparent size of the sun in the sky.
The angular diameter of the sun, or the cone angle of the sunlight as perceived from Earth, is approximately 0.53 degrees on average. This value can vary slightly due to the elliptical nature of Earth’s orbit around the sun, but it generally stays within a narrow range.
Here’s a more precise breakdown:
Average Angular Diameter: About 0.53 degrees (31 arcminutes)
Minimum Angular Diameter: Approximately 0.52 degrees (when Earth is at aphelion, the farthest point from the sun)
Maximum Angular Diameter: Approximately 0.54 degrees (when Earth is at perihelion, the closest point to the sun)
This angular diameter remains relatively constant throughout the day because the sun’s distance from Earth does not change significantly over a single day.
To summarize, the cone angle of the sun’s light, or its angular diameter, is typically around 0.53 degrees, regardless of the time of day.
Note: In Foundry’s Nuke, the software will map 18% gray to whatever your center f/stop is set to in the viewer settings (f/8 by default… change that to EV by following the instructions below).
You can experiment with this by attaching an Exposure node to a Constant set to 0.18, setting your viewer read-out to Spotmeter, and adjusting the stops in the node up and down. You will see that a full stop up or down will give you the respective next value on the aperture scale (f8, f11, f16 etc.).
One stop doubles or halves the amount or light that hits the filmback/ccd, so everything works in powers of 2.
So starting with 0.18 in your constant, you will see that raising it by a stop will give you .36 as a floating point number (in linear space), while your f/stop will be f/11 and so on.
If you set your center stop to 0 (see below) you will get a relative readout in EVs, where EV 0 again equals 18% constant gray.
In other words. Setting the center f-stop to 0 means that in a neutral plate, the middle gray in the macbeth chart will equal to exposure value 0. EV 0 corresponds to an exposure time of 1 sec and an aperture of f/1.0.
This will set the sun usually around EV12-17 and the sky EV1-4 , depending on cloud coverage.
To switch Foundry’s Nuke’s SpotMeter to return the EV of an image, click on the main viewport, and then press s, this opens the viewer’s properties. Now set the center f-stop to 0 in there. And the SpotMeter in the viewport will change from aperture and fstops to EV.
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.






















































{kind=link}
{kind=link}
