


COMPOSITION






DESIGN
-
Kelly Boesch – Static and Toward The Light
Read more: Kelly Boesch – Static and Toward The Lighthttps://www.kellyboeschdesign.com
I was working an album cover last night and got these really cool images in midjourney so made a video out of it. Animated using Pika. Song made using Suno Full version on my bandcamp. It’s called Static.
https://www.linkedin.com/posts/kellyboesch_midjourney-keyframes-ai-activity-7359244714853736450-Wvcr(more…)
















COLOR
-
The 7 key elements of brand identity design + 10 corporate identity examples
Read more: The 7 key elements of brand identity design + 10 corporate identity exampleswww.lucidpress.com/blog/the-7-key-elements-of-brand-identity-design
1. Clear brand purpose and positioning
2. Thorough market research
3. Likable brand personality
4. Memorable logo
5. Attractive color palette
6. Professional typography
7. On-brand supporting graphics

-
Virtual Production volumes study
Read more: Virtual Production volumes studyColor Fidelity in LED Volumes
https://theasc.com/articles/color-fidelity-in-led-volumes
Virtual Production Glossary
https://vpglossary.com/What is Virtual Production – In depth analysis
https://www.leadingledtech.com/what-is-a-led-virtual-production-studio-in-depth-technical-analysis/
A comparison of LED panels for use in Virtual Production:
Findings and recommendations
https://eprints.bournemouth.ac.uk/36826/1/LED_Comparison_White_Paper%281%29.pdf -
PTGui 13 beta adds control through a Patch Editor
Read more: PTGui 13 beta adds control through a Patch EditorAdditions:
- Patch Editor (PTGui Pro)
- DNG output
- Improved RAW / DNG handling
- JPEG 2000 support
- Performance improvements












LIGHTING
-
RawTherapee – a free, open source, cross-platform raw image and HDRi processing program
Read more: RawTherapee – a free, open source, cross-platform raw image and HDRi processing program5.10 of this tool includes excellent tools to clean up cr2 and cr3 used on set to support HDRI processing.
Converting raw to AcesCG 32 bit tiffs with metadata.


-
Cinematographers Blueprint 300dpi poster
Read more: Cinematographers Blueprint 300dpi posterThe 300dpi digital poster is now available to all PixelSham.com subscribers.

If you have already subscribed and wish a copy, please send me a note through the contact page.
-
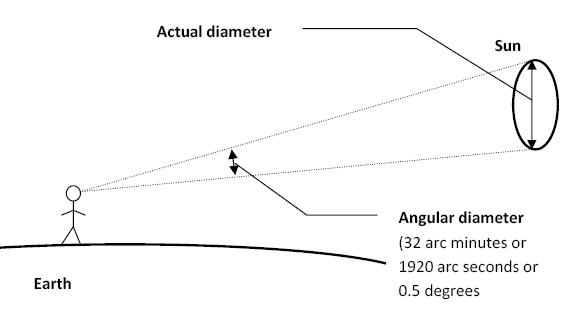
Sun cone angle (angular diameter) as perceived by earth viewers
Read more: Sun cone angle (angular diameter) as perceived by earth viewersAlso see:
https://www.pixelsham.com/2020/08/01/solid-angle-measures/
The cone angle of the sun refers to the angular diameter of the sun as observed from Earth, which is related to the apparent size of the sun in the sky.
The angular diameter of the sun, or the cone angle of the sunlight as perceived from Earth, is approximately 0.53 degrees on average. This value can vary slightly due to the elliptical nature of Earth’s orbit around the sun, but it generally stays within a narrow range.
Here’s a more precise breakdown:
-
- Average Angular Diameter: About 0.53 degrees (31 arcminutes)
- Minimum Angular Diameter: Approximately 0.52 degrees (when Earth is at aphelion, the farthest point from the sun)
- Maximum Angular Diameter: Approximately 0.54 degrees (when Earth is at perihelion, the closest point to the sun)
This angular diameter remains relatively constant throughout the day because the sun’s distance from Earth does not change significantly over a single day.
To summarize, the cone angle of the sun’s light, or its angular diameter, is typically around 0.53 degrees, regardless of the time of day.
https://en.wikipedia.org/wiki/Angular_diameter
-
-
GretagMacbeth Color Checker Numeric Values and Middle Gray
Read more: GretagMacbeth Color Checker Numeric Values and Middle GrayThe human eye perceives half scene brightness not as the linear 50% of the present energy (linear nature values) but as 18% of the overall brightness. We are biased to perceive more information in the dark and contrast areas. A Macbeth chart helps with calibrating back into a photographic capture into this “human perspective” of the world.
https://en.wikipedia.org/wiki/Middle_gray
In photography, painting, and other visual arts, middle gray or middle grey is a tone that is perceptually about halfway between black and white on a lightness scale in photography and printing, it is typically defined as 18% reflectance in visible light

Light meters, cameras, and pictures are often calibrated using an 18% gray card[4][5][6] or a color reference card such as a ColorChecker. On the assumption that 18% is similar to the average reflectance of a scene, a grey card can be used to estimate the required exposure of the film.
https://en.wikipedia.org/wiki/ColorChecker
(more…) -
Magnific.ai Relight – change the entire lighting of a scene
Read more: Magnific.ai Relight – change the entire lighting of a scene
It’s a new Magnific spell that allows you to change the entire lighting of a scene and, optionally, the background with just:
1/ A prompt OR
2/ A reference image OR
3/ A light map (drawing your own lights)https://x.com/javilopen/status/1805274155065176489



-
3D Lighting Tutorial by Amaan Kram
Read more: 3D Lighting Tutorial by Amaan Kramhttp://www.amaanakram.com/lightingT/part1.htm
The goals of lighting in 3D computer graphics are more or less the same as those of real world lighting.
Lighting serves a basic function of bringing out, or pushing back the shapes of objects visible from the camera’s view.
It gives a two-dimensional image on the monitor an illusion of the third dimension-depth.But it does not just stop there. It gives an image its personality, its character. A scene lit in different ways can give a feeling of happiness, of sorrow, of fear etc., and it can do so in dramatic or subtle ways. Along with personality and character, lighting fills a scene with emotion that is directly transmitted to the viewer.
Trying to simulate a real environment in an artificial one can be a daunting task. But even if you make your 3D rendering look absolutely photo-realistic, it doesn’t guarantee that the image carries enough emotion to elicit a “wow” from the people viewing it.
Making 3D renderings photo-realistic can be hard. Putting deep emotions in them can be even harder. However, if you plan out your lighting strategy for the mood and emotion that you want your rendering to express, you make the process easier for yourself.
Each light source can be broken down in to 4 distinct components and analyzed accordingly.
· Intensity
· Direction
· Color
· SizeThe overall thrust of this writing is to produce photo-realistic images by applying good lighting techniques.

-
Capturing the world in HDR for real time projects – Call of Duty: Advanced Warfare
Read more: Capturing the world in HDR for real time projects – Call of Duty: Advanced WarfareReal-World Measurements for Call of Duty: Advanced Warfare
www.activision.com/cdn/research/Real_World_Measurements_for_Call_of_Duty_Advanced_Warfare.pdf
Local version
Real_World_Measurements_for_Call_of_Duty_Advanced_Warfare.pdf












{kind=link}
COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Kling 1.6 and competitors – advanced tests and comparisons
-
Yann Lecun: Meta AI, Open Source, Limits of LLMs, AGI & the Future of AI | Lex Fridman Podcast #416
-
GretagMacbeth Color Checker Numeric Values and Middle Gray
-
AI Search – Find The Best AI Tools & Apps
-
How to paint a boardgame miniatures
-
WhatDreamsCost Spline-Path-Control – Create motion controls for ComfyUI
-
3D Gaussian Splatting step by step beginner course
-
Convert 2D Images or Text to 3D Models
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
