


COMPOSITION
DESIGN
-
boldtron – 𝗗𝗘𝗣𝗜𝗖𝗧𝗜𝗡𝗚 𝗪𝗔𝗧𝗘𝗥𝗚𝗨𝗡𝗦
Read more: boldtron – 𝗗𝗘𝗣𝗜𝗖𝗧𝗜𝗡𝗚 𝗪𝗔𝗧𝗘𝗥𝗚𝗨𝗡𝗦See this Instagram post by @boldtron using ComfyUI + Krea
https://www.instagram.com/p/C5v-H0PNYYg/?utm_source=ig_web_button_share_sheet





















COLOR
-
HDR and Color
Read more: HDR and Colorhttps://www.soundandvision.com/content/nits-and-bits-hdr-and-color
In HD we often refer to the range of available colors as a color gamut. Such a color gamut is typically plotted on a two-dimensional diagram, called a CIE chart, as shown in at the top of this blog. Each color is characterized by its x/y coordinates.

Good enough for government work, perhaps. But for HDR, with its higher luminance levels and wider color, the gamut becomes three-dimensional.

For HDR the color gamut therefore becomes a characteristic we now call the color volume. It isn’t easy to show color volume on a two-dimensional medium like the printed page or a computer screen, but one method is shown below. As the luminance becomes higher, the picture eventually turns to white. As it becomes darker, it fades to black. The traditional color gamut shown on the CIE chart is simply a slice through this color volume at a selected luminance level, such as 50%.
Three different color volumes—we still refer to them as color gamuts though their third dimension is important—are currently the most significant. The first is BT.709 (sometimes referred to as Rec.709), the color gamut used for pre-UHD/HDR formats, including standard HD.
The largest is known as BT.2020; it encompasses (roughly) the range of colors visible to the human eye (though ET might find it insufficient!).
Between these two is the color gamut used in digital cinema, known as DCI-P3.

sRGB

D65

-
Scientists claim to have discovered ‘new colour’ no one has seen before: Olo
Read more: Scientists claim to have discovered ‘new colour’ no one has seen before: Olohttps://www.bbc.com/news/articles/clyq0n3em41o
By stimulating specific cells in the retina, the participants claim to have witnessed a blue-green colour that scientists have called “olo”, but some experts have said the existence of a new colour is “open to argument”.
The findings, published in the journal Science Advances on Friday, have been described by the study’s co-author, Prof Ren Ng from the University of California, as “remarkable”.

(A) System inputs. (i) Retina map of 103 cone cells preclassified by spectral type (7). (ii) Target visual percept (here, a video of a child, see movie S1 at 1:04). (iii) Infrared cellular-scale imaging of the retina with 60-frames-per-second rolling shutter. Fixational eye movement is visible over the three frames shown.
(B) System outputs. (iv) Real-time per-cone target activation levels to reproduce the target percept, computed by: extracting eye motion from the input video relative to the retina map; identifying the spectral type of every cone in the field of view; computing the per-cone activation the target percept would have produced. (v) Intensities of visible-wavelength 488-nm laser microdoses at each cone required to achieve its target activation level.
(C) Infrared imaging and visible-wavelength stimulation are physically accomplished in a raster scan across the retinal region using AOSLO. By modulating the visible-wavelength beam’s intensity, the laser microdoses shown in (v) are delivered. Drawing adapted with permission [Harmening and Sincich (54)].
(D) Examples of target percepts with corresponding cone activations and laser microdoses, ranging from colored squares to complex imagery. Teal-striped regions represent the color “olo” of stimulating only M cones.
-
Akiyoshi Kitaoka – Surround biased illumination perception
Read more: Akiyoshi Kitaoka – Surround biased illumination perceptionhttps://x.com/AkiyoshiKitaoka/status/1798705648001327209
The left face appears whitish and the right one blackish, but they are made up of the same luminance.

https://community.wolfram.com/groups/-/m/t/3191015
Illusory staircase Gelb effect
https://www.psy.ritsumei.ac.jp/akitaoka/illgelbe.html
-
Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental process
Read more: Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental processhttps://www.chrbutler.com/understanding-the-eye-mind-connection
The intricate relationship between the eyes and the brain, often termed the eye-mind connection, reveals that vision is predominantly a cognitive process. This understanding has profound implications for fields such as design, where capturing and maintaining attention is paramount. This essay delves into the nuances of visual perception, the brain’s role in interpreting visual data, and how this knowledge can be applied to effective design strategies.
This cognitive aspect of vision is evident in phenomena such as optical illusions, where the brain interprets visual information in a way that contradicts physical reality. These illusions underscore that what we “see” is not merely a direct recording of the external world but a constructed experience shaped by cognitive processes.
Understanding the cognitive nature of vision is crucial for effective design. Designers must consider how the brain processes visual information to create compelling and engaging visuals. This involves several key principles:
- Attention and Engagement
- Visual Hierarchy
- Cognitive Load Management
- Context and Meaning
-
What causes color
Read more: What causes colorwww.webexhibits.org/causesofcolor/5.html
Water itself has an intrinsic blue color that is a result of its molecular structure and its behavior.

-
Björn Ottosson – OKHSV and OKHSL – Two new color spaces for color picking
Read more: Björn Ottosson – OKHSV and OKHSL – Two new color spaces for color pickinghttps://bottosson.github.io/misc/colorpicker
https://bottosson.github.io/posts/colorpicker/
https://www.smashingmagazine.com/2024/10/interview-bjorn-ottosson-creator-oklab-color-space/
One problem with sRGB is that in a gradient between blue and white, it becomes a bit purple in the middle of the transition. That’s because sRGB really isn’t created to mimic how the eye sees colors; rather, it is based on how CRT monitors work. That means it works with certain frequencies of red, green, and blue, and also the non-linear coding called gamma. It’s a miracle it works as well as it does, but it’s not connected to color perception. When using those tools, you sometimes get surprising results, like purple in the gradient.

There were also attempts to create simple models matching human perception based on XYZ, but as it turned out, it’s not possible to model all color vision that way. Perception of color is incredibly complex and depends, among other things, on whether it is dark or light in the room and the background color it is against. When you look at a photograph, it also depends on what you think the color of the light source is. The dress is a typical example of color vision being very context-dependent. It is almost impossible to model this perfectly.
I based Oklab on two other color spaces, CIECAM16 and IPT. I used the lightness and saturation prediction from CIECAM16, which is a color appearance model, as a target. I actually wanted to use the datasets used to create CIECAM16, but I couldn’t find them.
IPT was designed to have better hue uniformity. In experiments, they asked people to match light and dark colors, saturated and unsaturated colors, which resulted in a dataset for which colors, subjectively, have the same hue. IPT has a few other issues but is the basis for hue in Oklab.
In the Munsell color system, colors are described with three parameters, designed to match the perceived appearance of colors: Hue, Chroma and Value. The parameters are designed to be independent and each have a uniform scale. This results in a color solid with an irregular shape. The parameters are designed to be independent and each have a uniform scale. This results in a color solid with an irregular shape. Modern color spaces and models, such as CIELAB, Cam16 and Björn Ottosson own Oklab, are very similar in their construction.

By far the most used color spaces today for color picking are HSL and HSV, two representations introduced in the classic 1978 paper “Color Spaces for Computer Graphics”. HSL and HSV designed to roughly correlate with perceptual color properties while being very simple and cheap to compute.
Today HSL and HSV are most commonly used together with the sRGB color space.

One of the main advantages of HSL and HSV over the different Lab color spaces is that they map the sRGB gamut to a cylinder. This makes them easy to use since all parameters can be changed independently, without the risk of creating colors outside of the target gamut.

The main drawback on the other hand is that their properties don’t match human perception particularly well.
Reconciling these conflicting goals perfectly isn’t possible, but given that HSV and HSL don’t use anything derived from experiments relating to human perception, creating something that makes a better tradeoff does not seem unreasonable.
With this new lightness estimate, we are ready to look into the construction of Okhsv and Okhsl.















LIGHTING
-
HDRI shooting and editing by Xuan Prada and Greg Zaal
Read more: HDRI shooting and editing by Xuan Prada and Greg Zaalwww.xuanprada.com/blog/2014/11/3/hdri-shooting
http://blog.gregzaal.com/2016/03/16/make-your-own-hdri/
http://blog.hdrihaven.com/how-to-create-high-quality-hdri/

Shooting checklist
- Full coverage of the scene (fish-eye shots)
- Backplates for look-development (including ground or floor)
- Macbeth chart for white balance
- Grey ball for lighting calibration
- Chrome ball for lighting orientation
- Basic scene measurements
- Material samples
- Individual HDR artificial lighting sources if required
Methodology
(more…) -
Tracing Spherical harmonics and how Weta used them in production
Read more: Tracing Spherical harmonics and how Weta used them in productionA way to approximate complex lighting in ultra realistic renders.
All SH lighting techniques involve replacing parts of standard lighting equations with spherical functions that have been projected into frequency space using the spherical harmonics as a basis.
http://www.cs.columbia.edu/~cs4162/slides/spherical-harmonic-lighting.pdf
Spherical harmonics as used at Weta Digital
-
What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…
Read more: What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…RASTERIZATION
Rasterisation (or rasterization) is the task of taking the information described in a vector graphics format OR the vertices of triangles making 3D shapes and converting them into a raster image (a series of pixels, dots or lines, which, when displayed together, create the image which was represented via shapes), or in other words “rasterizing” vectors or 3D models onto a 2D plane for display on a computer screen.For each triangle of a 3D shape, you project the corners of the triangle on the virtual screen with some math (projective geometry). Then you have the position of the 3 corners of the triangle on the pixel screen. Those 3 points have texture coordinates, so you know where in the texture are the 3 corners. The cost is proportional to the number of triangles, and is only a little bit affected by the screen resolution.
In computer graphics, a raster graphics or bitmap image is a dot matrix data structure that represents a generally rectangular grid of pixels (points of color), viewable via a monitor, paper, or other display medium.
With rasterization, objects on the screen are created from a mesh of virtual triangles, or polygons, that create 3D models of objects. A lot of information is associated with each vertex, including its position in space, as well as information about color, texture and its “normal,” which is used to determine the way the surface of an object is facing.
Computers then convert the triangles of the 3D models into pixels, or dots, on a 2D screen. Each pixel can be assigned an initial color value from the data stored in the triangle vertices.
Further pixel processing or “shading,” including changing pixel color based on how lights in the scene hit the pixel, and applying one or more textures to the pixel, combine to generate the final color applied to a pixel.
The main advantage of rasterization is its speed. However, rasterization is simply the process of computing the mapping from scene geometry to pixels and does not prescribe a particular way to compute the color of those pixels. So it cannot take shading, especially the physical light, into account and it cannot promise to get a photorealistic output. That’s a big limitation of rasterization.
There are also multiple problems:
If you have two triangles one is behind the other, you will draw twice all the pixels. you only keep the pixel from the triangle that is closer to you (Z-buffer), but you still do the work twice.
The borders of your triangles are jagged as it is hard to know if a pixel is in the triangle or out. You can do some smoothing on those, that is anti-aliasing.
You have to handle every triangles (including the ones behind you) and then see that they do not touch the screen at all. (we have techniques to mitigate this where we only look at triangles that are in the field of view)
Transparency is hard to handle (you can’t just do an average of the color of overlapping transparent triangles, you have to do it in the right order)



RAY CASTING
It is almost the exact reverse of rasterization: you start from the virtual screen instead of the vector or 3D shapes, and you project a ray, starting from each pixel of the screen, until it intersect with a triangle.The cost is directly correlated to the number of pixels in the screen and you need a really cheap way of finding the first triangle that intersect a ray. In the end, it is more expensive than rasterization but it will, by design, ignore the triangles that are out of the field of view.
You can use it to continue after the first triangle it hit, to take a little bit of the color of the next one, etc… This is useful to handle the border of the triangle cleanly (less jagged) and to handle transparency correctly.
RAYTRACING



Same idea as ray casting except once you hit a triangle you reflect on it and go into a different direction. The number of reflection you allow is the “depth” of your ray tracing. The color of the pixel can be calculated, based off the light source and all the polygons it had to reflect off of to get to that screen pixel.The easiest way to think of ray tracing is to look around you, right now. The objects you’re seeing are illuminated by beams of light. Now turn that around and follow the path of those beams backwards from your eye to the objects that light interacts with. That’s ray tracing.
Ray tracing is eye-oriented process that needs walking through each pixel looking for what object should be shown there, which is also can be described as a technique that follows a beam of light (in pixels) from a set point and simulates how it reacts when it encounters objects.
Compared with rasterization, ray tracing is hard to be implemented in real time, since even one ray can be traced and processed without much trouble, but after one ray bounces off an object, it can turn into 10 rays, and those 10 can turn into 100, 1000…The increase is exponential, and the the calculation for all these rays will be time consuming.
Historically, computer hardware hasn’t been fast enough to use these techniques in real time, such as in video games. Moviemakers can take as long as they like to render a single frame, so they do it offline in render farms. Video games have only a fraction of a second. As a result, most real-time graphics rely on the another technique called rasterization.

PATH TRACING
Path tracing can be used to solve more complex lighting situations.
Path tracing is a type of ray tracing. When using path tracing for rendering, the rays only produce a single ray per bounce. The rays do not follow a defined line per bounce (to a light, for example), but rather shoot off in a random direction. The path tracing algorithm then takes a random sampling of all of the rays to create the final image. This results in sampling a variety of different types of lighting.When a ray hits a surface it doesn’t trace a path to every light source, instead it bounces the ray off the surface and keeps bouncing it until it hits a light source or exhausts some bounce limit.
It then calculates the amount of light transferred all the way to the pixel, including any color information gathered from surfaces along the way.
It then averages out the values calculated from all the paths that were traced into the scene to get the final pixel color value.It requires a ton of computing power and if you don’t send out enough rays per pixel or don’t trace the paths far enough into the scene then you end up with a very spotty image as many pixels fail to find any light sources from their rays. So when you increase the the samples per pixel, you can see the image quality becomes better and better.
Ray tracing tends to be more efficient than path tracing. Basically, the render time of a ray tracer depends on the number of polygons in the scene. The more polygons you have, the longer it will take.
Meanwhile, the rendering time of a path tracer can be indifferent to the number of polygons, but it is related to light situation: If you add a light, transparency, translucence, or other shader effects, the path tracer will slow down considerably.
blogs.nvidia.com/blog/2018/03/19/whats-difference-between-ray-tracing-rasterization/
https://en.wikipedia.org/wiki/Rasterisation
https://www.quora.com/Whats-the-difference-between-ray-tracing-and-path-tracing
-
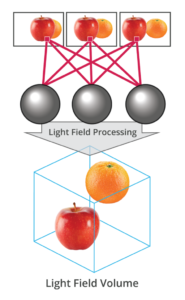
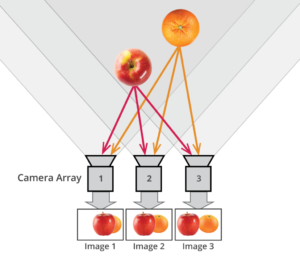
What is the Light Field?
Read more: What is the Light Field?http://lightfield-forum.com/what-is-the-lightfield/
The light field consists of the total of all light rays in 3D space, flowing through every point and in every direction.
How to Record a Light Field
- a single, robotically controlled camera
- a rotating arc of cameras
- an array of cameras or camera modules
- a single camera or camera lens fitted with a microlens array
-
What is physically correct lighting all about?
Read more: What is physically correct lighting all about?http://gamedev.stackexchange.com/questions/60638/what-is-physically-correct-lighting-all-about
2012-08 Nathan Reed wrote:
Physically-based shading means leaving behind phenomenological models, like the Phong shading model, which are simply built to “look good” subjectively without being based on physics in any real way, and moving to lighting and shading models that are derived from the laws of physics and/or from actual measurements of the real world, and rigorously obey physical constraints such as energy conservation.
For example, in many older rendering systems, shading models included separate controls for specular highlights from point lights and reflection of the environment via a cubemap. You could create a shader with the specular and the reflection set to wildly different values, even though those are both instances of the same physical process. In addition, you could set the specular to any arbitrary brightness, even if it would cause the surface to reflect more energy than it actually received.
In a physically-based system, both the point light specular and the environment reflection would be controlled by the same parameter, and the system would be set up to automatically adjust the brightness of both the specular and diffuse components to maintain overall energy conservation. Moreover you would want to set the specular brightness to a realistic value for the material you’re trying to simulate, based on measurements.
Physically-based lighting or shading includes physically-based BRDFs, which are usually based on microfacet theory, and physically correct light transport, which is based on the rendering equation (although heavily approximated in the case of real-time games).
It also includes the necessary changes in the art process to make use of these features. Switching to a physically-based system can cause some upsets for artists. First of all it requires full HDR lighting with a realistic level of brightness for light sources, the sky, etc. and this can take some getting used to for the lighting artists. It also requires texture/material artists to do some things differently (particularly for specular), and they can be frustrated by the apparent loss of control (e.g. locking together the specular highlight and environment reflection as mentioned above; artists will complain about this). They will need some time and guidance to adapt to the physically-based system.
On the plus side, once artists have adapted and gained trust in the physically-based system, they usually end up liking it better, because there are fewer parameters overall (less work for them to tweak). Also, materials created in one lighting environment generally look fine in other lighting environments too. This is unlike more ad-hoc models, where a set of material parameters might look good during daytime, but it comes out ridiculously glowy at night, or something like that.
Here are some resources to look at for physically-based lighting in games:
SIGGRAPH 2013 Physically Based Shading Course, particularly the background talk by Naty Hoffman at the beginning. You can also check out the previous incarnations of this course for more resources.
Sébastien Lagarde, Adopting a physically-based shading model and Feeding a physically-based shading model
And of course, I would be remiss if I didn’t mention Physically-Based Rendering by Pharr and Humphreys, an amazing reference on this whole subject and well worth your time, although it focuses on offline rather than real-time rendering.
-
Composition and The Expressive Nature Of Light
Read more: Composition and The Expressive Nature Of Lighthttp://www.huffingtonpost.com/bill-danskin/post_12457_b_10777222.html
George Sand once said “ The artist vocation is to send light into the human heart.”










{kind=link}
COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
