


COMPOSITION




DESIGN













COLOR
-
About green screens
Read more: About green screenshackaday.com/2015/02/07/how-green-screen-worked-before-computers/
www.newtek.com/blog/tips/best-green-screen-materials/
www.chromawall.com/blog//chroma-key-green

Chroma Key Green, the color of green screens is also known as Chroma Green and is valued at approximately 354C in the Pantone color matching system (PMS).
Chroma Green can be broken down in many different ways. Here is green screen green as other values useful for both physical and digital production:
Green Screen as RGB Color Value: 0, 177, 64
Green Screen as CMYK Color Value: 81, 0, 92, 0
Green Screen as Hex Color Value: #00b140
Green Screen as Websafe Color Value: #009933Chroma Key Green is reasonably close to an 18% gray reflectance.
Illuminate your green screen with an uniform source with less than 2/3 EV variation.
The level of brightness at any given f-stop should be equivalent to a 90% white card under the same lighting. -
Björn Ottosson – How software gets color wrong
Read more: Björn Ottosson – How software gets color wronghttps://bottosson.github.io/posts/colorwrong/
Most software around us today are decent at accurately displaying colors. Processing of colors is another story unfortunately, and is often done badly.
To understand what the problem is, let’s start with an example of three ways of blending green and magenta:
- Perceptual blend – A smooth transition using a model designed to mimic human perception of color. The blending is done so that the perceived brightness and color varies smoothly and evenly.
- Linear blend – A model for blending color based on how light behaves physically. This type of blending can occur in many ways naturally, for example when colors are blended together by focus blur in a camera or when viewing a pattern of two colors at a distance.
- sRGB blend – This is how colors would normally be blended in computer software, using sRGB to represent the colors.

Let’s look at some more examples of blending of colors, to see how these problems surface more practically. The examples use strong colors since then the differences are more pronounced. This is using the same three ways of blending colors as the first example.

Instead of making it as easy as possible to work with color, most software make it unnecessarily hard, by doing image processing with representations not designed for it. Approximating the physical behavior of light with linear RGB models is one easy thing to do, but more work is needed to create image representations tailored for image processing and human perception.
Also see:
-
OpenColorIO standard
Read more: OpenColorIO standardhttps://www.provideocoalition.com/color-management-part-11-introducing-opencolorio/
OpenColorIO (OCIO) is a new open source project from Sony Imageworks.
Based on development started in 2003, OCIO enables color transforms and image display to be handled in a consistent manner across multiple graphics applications. Unlike other color management solutions, OCIO is geared towards motion-picture post production, with an emphasis on visual effects and animation color pipelines.

-
Is a MacBeth Colour Rendition Chart the Safest Way to Calibrate a Camera?
Read more: Is a MacBeth Colour Rendition Chart the Safest Way to Calibrate a Camera?www.colour-science.org/posts/the-colorchecker-considered-mostly-harmless/
“Unless you have all the relevant spectral measurements, a colour rendition chart should not be used to perform colour-correction of camera imagery but only for white balancing and relative exposure adjustments.”
“Using a colour rendition chart for colour-correction might dramatically increase error if the scene light source spectrum is different from the illuminant used to compute the colour rendition chart’s reference values.”
“other factors make using a colour rendition chart unsuitable for camera calibration:
– Uncontrolled geometry of the colour rendition chart with the incident illumination and the camera.
– Unknown sample reflectances and ageing as the colour of the samples vary with time.
– Low samples count.
– Camera noise and flare.
– Etc…“Those issues are well understood in the VFX industry, and when receiving plates, we almost exclusively use colour rendition charts to white balance and perform relative exposure adjustments, i.e. plate neutralisation.”
-
Virtual Production volumes study
Read more: Virtual Production volumes studyColor Fidelity in LED Volumes
https://theasc.com/articles/color-fidelity-in-led-volumes
Virtual Production Glossary
https://vpglossary.com/What is Virtual Production – In depth analysis
https://www.leadingledtech.com/what-is-a-led-virtual-production-studio-in-depth-technical-analysis/
A comparison of LED panels for use in Virtual Production:
Findings and recommendations
https://eprints.bournemouth.ac.uk/36826/1/LED_Comparison_White_Paper%281%29.pdf -
Black Body color aka the Planckian Locus curve for white point eye perception
Read more: Black Body color aka the Planckian Locus curve for white point eye perceptionhttp://en.wikipedia.org/wiki/Black-body_radiation

Black-body radiation is the type of electromagnetic radiation within or surrounding a body in thermodynamic equilibrium with its environment, or emitted by a black body (an opaque and non-reflective body) held at constant, uniform temperature. The radiation has a specific spectrum and intensity that depends only on the temperature of the body.
A black-body at room temperature appears black, as most of the energy it radiates is infra-red and cannot be perceived by the human eye. At higher temperatures, black bodies glow with increasing intensity and colors that range from dull red to blindingly brilliant blue-white as the temperature increases.
(more…) -
Thomas Mansencal – Colour Science for Python
Read more: Thomas Mansencal – Colour Science for Pythonhttps://thomasmansencal.substack.com/p/colour-science-for-python
https://www.colour-science.org/
Colour is an open-source Python package providing a comprehensive number of algorithms and datasets for colour science. It is freely available under the BSD-3-Clause terms.









LIGHTING
-
How to Direct and Edit a Fight Scene for Rhythm and Pacing
Read more: How to Direct and Edit a Fight Scene for Rhythm and Pacingwww.premiumbeat.com/blog/directing-fight-scene-cinematography/

1- Frame the action
2- Stage the action
3- Use camera movements
4- Set a rhythm
5- Control the speed of the action
-
What light is best to illuminate gems for resale
Read more: What light is best to illuminate gems for resalewww.palagems.com/gem-lighting2
Artificial light sources, not unlike the diverse phases of natural light, vary considerably in their properties. As a result, some lamps render an object’s color better than others do.
The most important criterion for assessing the color-rendering ability of any lamp is its spectral power distribution curve.
Natural daylight varies too much in strength and spectral composition to be taken seriously as a lighting standard for grading and dealing colored stones. For anything to be a standard, it must be constant in its properties, which natural light is not.
For dealers in particular to make the transition from natural light to an artificial light source, that source must offer:
1- A degree of illuminance at least as strong as the common phases of natural daylight.
2- Spectral properties identical or comparable to a phase of natural daylight.A source combining these two things makes gems appear much the same as when viewed under a given phase of natural light. From the viewpoint of many dealers, this corresponds to a naturalappearance.
The 6000° Kelvin xenon short-arc lamp appears closest to meeting the criteria for a standard light source. Besides the strong illuminance this lamp affords, its spectrum is very similar to CIE standard illuminants of similar color temperature.


-
7 Easy Portrait Lighting Setups
Read more: 7 Easy Portrait Lighting Setups
Butterfly
Loop
Rembrandt
Split
Rim
Broad
Short
-
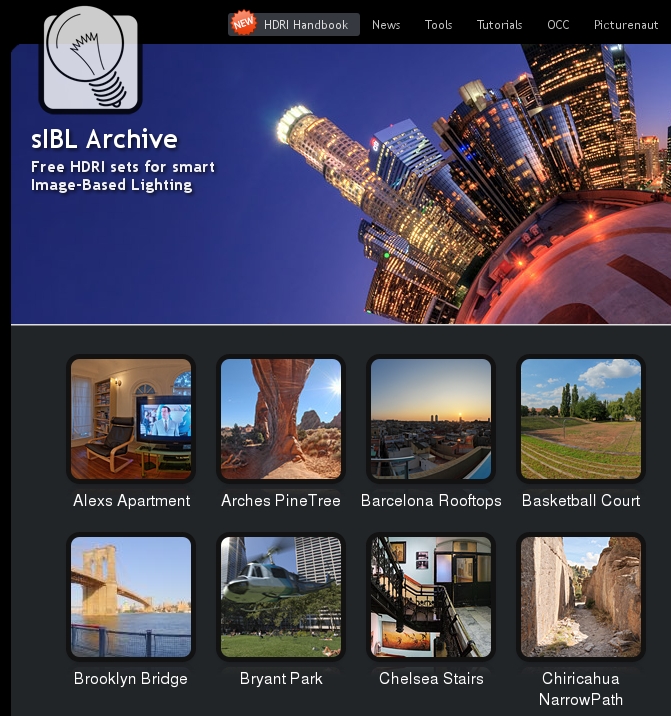
HDRI Resources
Read more: HDRI ResourcesText2Light
- https://www.cgtrader.com/free-3d-models/exterior/other/10-free-hdr-panoramas-created-with-text2light-zero-shot
- https://frozenburning.github.io/projects/text2light/
- https://github.com/FrozenBurning/Text2Light
Royalty free links
- https://locationtextures.com/panoramas/
- http://www.noahwitchell.com/freebies
- https://polyhaven.com/hdris
- https://hdrmaps.com/
- https://www.ihdri.com/
- https://hdrihaven.com/
- https://www.domeble.com/
- http://www.hdrlabs.com/sibl/archive.html
- https://www.hdri-hub.com/hdrishop/hdri
- http://noemotionhdrs.net/hdrevening.html
- https://www.openfootage.net/hdri-panorama/
- https://www.zwischendrin.com/en/browse/hdri
Nvidia GauGAN360
-
NVidia DiffusionRenderer – Neural Inverse and Forward Rendering with Video Diffusion Models. How NVIDIA reimagined relighting
Read more: NVidia DiffusionRenderer – Neural Inverse and Forward Rendering with Video Diffusion Models. How NVIDIA reimagined relightinghttps://www.fxguide.com/quicktakes/diffusing-reality-how-nvidia-reimagined-relighting/
https://research.nvidia.com/labs/toronto-ai/DiffusionRenderer/


-
Convert between light exposure and intensity
Read more: Convert between light exposure and intensityimport math,sys def Exposure2Intensity(exposure): exp = float(exposure) result = math.pow(2,exp) print(result) Exposure2Intensity(0) def Intensity2Exposure(intensity): inarg = float(intensity) if inarg == 0: print("Exposure of zero intensity is undefined.") return if inarg < 1e-323: inarg = max(inarg, 1e-323) print("Exposure of negative intensities is undefined. Clamping to a very small value instead (1e-323)") result = math.log(inarg, 2) print(result) Intensity2Exposure(0.1)Why Exposure?
Exposure is a stop value that multiplies the intensity by 2 to the power of the stop. Increasing exposure by 1 results in double the amount of light.
Artists think in “stops.” Doubling or halving brightness is easy math and common in grading and look-dev.
Exposure counts doublings in whole stops:- +1 stop = ×2 brightness
- −1 stop = ×0.5 brightness
This gives perceptually even controls across both bright and dark values.
Why Intensity?
Intensity is linear.
It’s what render engines and compositors expect when:- Summing values
- Averaging pixels
- Multiplying or filtering pixel data
Use intensity when you need the actual math on pixel/light data.
Formulas (from your Python)
- Intensity from exposure: intensity = 2**exposure
- Exposure from intensity: exposure = log₂(intensity)
Guardrails:
- Intensity must be > 0 to compute exposure.
- If intensity = 0 → exposure is undefined.
- Clamp tiny values (e.g.
1e−323) before using log₂.
Use Exposure (stops) when…
- You want artist-friendly sliders (−5…+5 stops)
- Adjusting look-dev or grading in even stops
- Matching plates with quick ±1 stop tweaks
- Tweening brightness changes smoothly across ranges
Use Intensity (linear) when…
- Storing raw pixel/light values
- Multiplying textures or lights by a gain
- Performing sums, averages, and filters
- Feeding values to render engines expecting linear data
Examples
- +2 stops → 2**2 = 4.0 (×4)
- +1 stop → 2**1 = 2.0 (×2)
- 0 stop → 2**0 = 1.0 (×1)
- −1 stop → 2**(−1) = 0.5 (×0.5)
- −2 stops → 2**(−2) = 0.25 (×0.25)
- Intensity 0.1 → exposure = log₂(0.1) ≈ −3.32
Rule of thumb
Think in stops (exposure) for controls and matching.
Compute in linear (intensity) for rendering and math.






![[gamma correction test]](http://www.madore.org/~david/misc/color/gammatest.png "sRGB gamma correction test")





COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Tencent Hunyuan3D 2.1 goes Open Source and adds MV (Multi-view) and MV Mini
-
Want to build a start up company that lasts? Think three-layer cake
-
Glossary of Lighting Terms – cheat sheet
-
Animation/VFX/Game Industry JOB POSTINGS by Chris Mayne
-
WhatDreamsCost Spline-Path-Control – Create motion controls for ComfyUI
-
Photography basics: Shutter angle and shutter speed and motion blur
-
Photography basics: Production Rendering Resolution Charts
-
JavaScript how-to free resources
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
