“Fix your gaze on the black dot on the left side of this image. But wait! Finish reading this paragraph first. As you gaze at the left dot, try to answer this question: In what direction is the object on the right moving? Is it drifting diagonally, or is it moving up and down?”
In color technology, color depth also known as bit depth, is either the number of bits used to indicate the color of a single pixel, OR the number of bits used for each color component of a single pixel.
When referring to a pixel, the concept can be defined as bits per pixel (bpp).
When referring to a color component, the concept can be defined as bits per component, bits per channel, bits per color (all three abbreviated bpc), and also bits per pixel component, bits per color channel or bits per sample (bps). Modern standards tend to use bits per component, but historical lower-depth systems used bits per pixel more often.
Color depth is only one aspect of color representation, expressing the precision with which the amount of each primary can be expressed; the other aspect is how broad a range of colors can be expressed (the gamut). The definition of both color precision and gamut is accomplished with a color encoding specification which assigns a digital code value to a location in a color space.
This 2025 I decided to start learning how to code, so I installed Visual Studio and I started looking into C++. After days of watching tutorials and guides about the basics of C++ and programming, I decided to make something physics-related. I started with a dot that fell to the ground and then I wanted to simulate gravitational attraction, so I made 2 circles attracting each other. I thought it was really cool to see something I made with code actually work, so I kept building on top of that small, basic program. And here we are after roughly 8 months of learning programming. This is Galaxy Engine, and it is a simulation software I have been making ever since I started my learning journey. It currently can simulate gravity, dark matter, galaxies, the Big Bang, temperature, fluid dynamics, breakable solids, planetary interactions, etc. The program can run many tens of thousands of particles in real time on the CPU thanks to the Barnes-Hut algorithm, mixed with Morton curves. It also includes its own PBR 2D path tracer with BVH optimizations. The path tracer can simulate a bunch of stuff like diffuse lighting, specular reflections, refraction, internal reflection, fresnel, emission, dispersion, roughness, IOR, nested IOR and more! I tried to make the path tracer closer to traditional 3D render engines like V-Ray. I honestly never imagined I would go this far with programming, and it has been an amazing learning experience so far. I think that mixing this knowledge with my 3D knowledge can unlock countless new possibilities. In case you are curious about Galaxy Engine, I made it completely free and Open-Source so that anyone can build and compile it locally! You can find the source code inGitHub
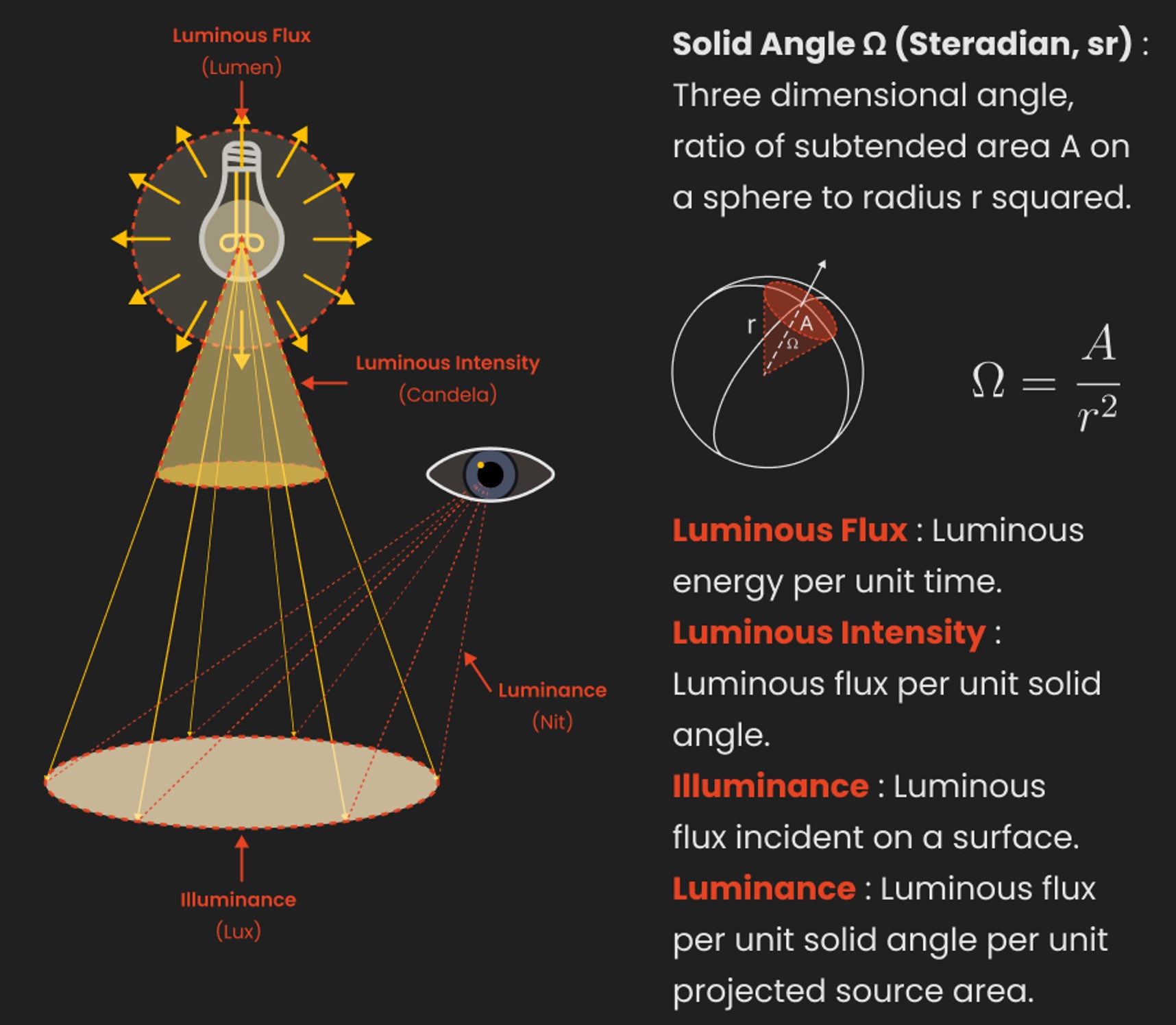
Candela is the basic unit of measure of the entire volume of light intensity from any point in a single direction from a light source. Note the detail: it measures the total volume of light within a certain beam angle and direction.
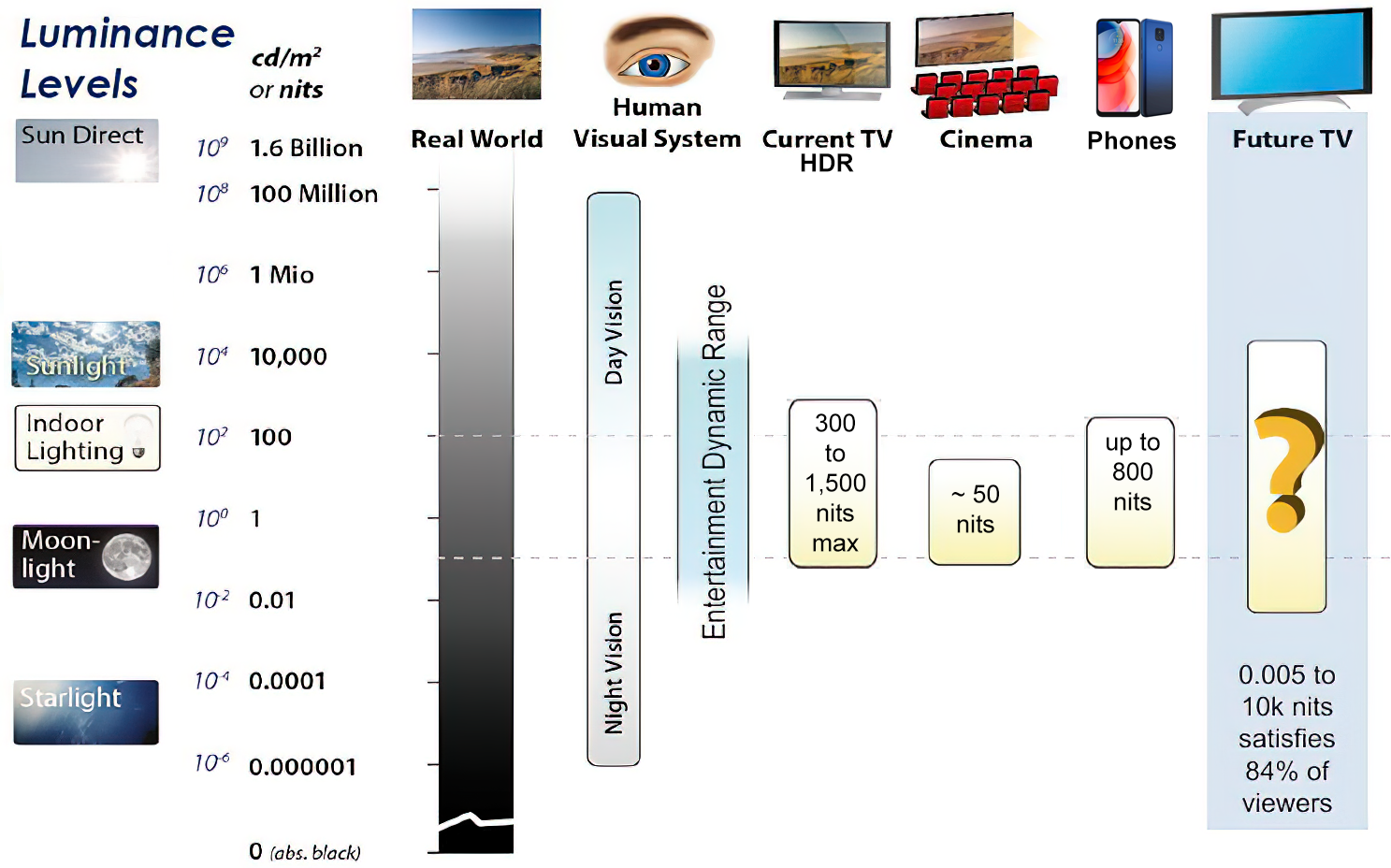
While the luminance of starlight is around 0.001 cd/m2, that of a sunlit scene is around 100,000 cd/m2, which is a hundred millions times higher. The luminance of the sun itself is approximately 1,000,000,000 cd/m2.
The candela per square metre (symbol: cd/m2) is the unit of luminance in the International System of Units (SI). The unit is based on the candela, the SI unit of luminous intensity, and the square metre, the SI unit of area. The nit (symbol: nt) is a non-SI name also used for this unit (1 nt = 1 cd/m2).[1] The term nit is believed to come from the Latin word nitēre, “to shine”. As a measure of light emitted per unit area, this unit is frequently used to specify the brightness of a display device.
NIT and cd/m2 (candela power) represent the same thing and can be used interchangeably. One nit is equivalent to one candela per square meter, where the candela is the amount of light which has been emitted by a common tallow candle, but NIT is not part of the International System of Units (abbreviated SI, from Systeme International, in French).
It’s easiest to think of a TV as emitting light directly, in much the same way as the Sun does. Nits are simply the measurement of the level of light (luminance) in a given area which the emitting source sends to your eyes or a camera sensor.
The Nit can be considered a unit of visible-light intensity which is often used to specify the brightness level of an LCD.
1 Nit is approximately equal to 3.426 Lumens. To work out a comparable number of Nits to Lumens, you need to multiply the number of Nits by 3.426. If you know the number of Lumens, and wish to know the Nits, simply divide the number of Lumens by 3.426.
Most consumer desktop LCDs have Nits of 200 to 300, the average TV most likely has an output capability of between 100 and 200 Nits, and an HDR TV ranges from 400 to 1,500 Nits.
Virtual Production sets currently sport around 6000 NIT ceiling and 1000 NIT wall panels.
The ambient brightness of a sunny day with clear blue skies is between 7000-10,000 nits (between 3000-7000 nits for overcast skies and indirect sunlight).
A bright sunny day can have specular highlights that reach over 100,000 nits. Direct sunlight is around 1,600,000,000 nits.
10,000 nits is also the typical brightness of a fluorescent tube – bright, but not painful to look at.
Tests showed that a “black level” of 0.005 nits (cd/m²) satisfied the vast majority of viewers. While 0.005 nits is very close to true black, Griffis says Dolby can go down to a black of 0.0001 nits, even though there is no need or ability for displays to get that dark today.
How bright is white? Dolby says the range of 0.005 nits – 10,000 nits satisfied 84% of the viewers in their viewing tests.
The brightest consumer HDR displays today are about 1,500 nits. Professional displays where HDR content is color-graded can achieve up to 4,000 nits peak brightness.
High brightness that would be in danger of damaging the eye would be in the neighborhood of 250,000 nits.
Lumens
Lumen is a measure of how much light is emitted (luminance, luminous flux) by an object. It indicates the total potential amount of light from a light source that is visible to the human eye.
Lumen is commonly used in the context of light bulbs or video-projectors as a metric for their brightness power.
Lumen is used to describe light output, and about video projectors, it is commonly referred to as ANSI Lumens. Simply put, lumens is how to find out how bright a LED display is. The higher the lumens, the brighter to display!
Technically speaking, a Lumen is the SI unit of luminous flux, which is equal to the amount of light which is emitted per second in a unit solid angle of one steradian from a uniform source of one-candela intensity radiating in all directions.
LUX
Lux(lx) or often Illuminance, is a photometric unit along a given area, which takes in account the sensitivity of human eye to different wavelenghts. It is the measure of light at a specific distance within a specific area at that distance. Often used to measure the incidental sun’s intensity.
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.