


COMPOSITION
-
Composition and The Expressive Nature Of Light
Read more: Composition and The Expressive Nature Of Lighthttp://www.huffingtonpost.com/bill-danskin/post_12457_b_10777222.html
George Sand once said “ The artist vocation is to send light into the human heart.”






DESIGN
-
VQGAN + CLIP AI made Music Video for the song Canvas by Resonate
Read more: VQGAN + CLIP AI made Music Video for the song Canvas by Resonate
” In this video, I utilized artificial intelligence to generate an animated music video for the song Canvas by Resonate. This tool allows anyone to generate beautiful images using only text as the input. My question was, what if I used song lyrics as input to the AI, can I make perfect music synchronized videos automatically with the push of a button? Let me know how you think the AI did in this visual interpretation of the song.
After getting caught up in the excitement around DALL·E2 (latest and greatest AI system, it’s INSANE), I searched for any way I could use similar image generation for music synchronization. Since DALL·E2 is not available to the public yet, my search led me to VQGAN + CLIP (Vector Quantized Generative Adversarial Network and Contrastive Language–Image Pre-training), before settling more specifically on Disco Diffusion V5.2 Turbo. If you don’t know what any of these words or acronyms mean, don’t worry, I was just as confused when I first started learning about this technology. I believe we’re reaching a turning point where entire industries are about to shift in reaction to this new process (which is essentially magic!).
DoodleChaos”
-
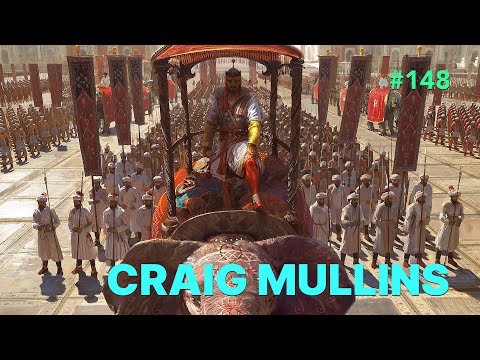
Pantheon of the War – The colossal war painting
Read more: Pantheon of the War – The colossal war paintingFour years in the making with the help of 150 artists, in commemoration of WW1.
edition.cnn.com/style/article/pantheon-de-la-guerre-wwi-painting/index.html
A panoramic canvas measuring 402 feet (122 meters) around and 45 feet (13.7 meters) high. It contained over 5,000 life-size portraits of war heroes, royalty and government officials from the Allies of World War I.
Partial section upload:











COLOR
-
Light and Matter : The 2018 theory of Physically-Based Rendering and Shading by Allegorithmic
Read more: Light and Matter : The 2018 theory of Physically-Based Rendering and Shading by Allegorithmicacademy.substance3d.com/courses/the-pbr-guide-part-1
academy.substance3d.com/courses/the-pbr-guide-part-2

 Local copy:
Local copy:
-
Colormaxxing – What if I told you that rgb(255, 0, 0) is not actually the reddest red you can have in your browser?
Read more: Colormaxxing – What if I told you that rgb(255, 0, 0) is not actually the reddest red you can have in your browser?https://karuna.dev/colormaxxing
https://webkit.org/blog-files/color-gamut/comparison.html
https://oklch.com/#70,0.1,197,100

-
THOMAS MANSENCAL – The Apparent Simplicity of RGB Rendering
Read more: THOMAS MANSENCAL – The Apparent Simplicity of RGB Rendering
https://thomasmansencal.substack.com/p/the-apparent-simplicity-of-rgb-rendering
The primary goal of physically-based rendering (PBR) is to create a simulation that accurately reproduces the imaging process of electro-magnetic spectrum radiation incident to an observer. This simulation should be indistinguishable from reality for a similar observer.
Because a camera is not sensitive to incident light the same way than a human observer, the images it captures are transformed to be colorimetric. A project might require infrared imaging simulation, a portion of the electro-magnetic spectrum that is invisible to us. Radically different observers might image the same scene but the act of observing does not change the intrinsic properties of the objects being imaged. Consequently, the physical modelling of the virtual scene should be independent of the observer.
-
Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminance
Read more: Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminancehttps://www.translatorscafe.com/unit-converter/en-US/illumination/1-11/

The power output of a light source is measured using the unit of watts W. This is a direct measure to calculate how much power the light is going to drain from your socket and it is not relatable to the light brightness itself.
The amount of energy emitted from it per second. That energy comes out in a form of photons which we can crudely represent with rays of light coming out of the source. The higher the power the more rays emitted from the source in a unit of time.
Not all energy emitted is visible to the human eye, so we often rely on photometric measurements, which takes in account the sensitivity of human eye to different wavelenghts


Details in the post
(more…)














LIGHTING
-
Cinematographers Blueprint 300dpi poster
Read more: Cinematographers Blueprint 300dpi posterThe 300dpi digital poster is now available to all PixelSham.com subscribers.

If you have already subscribed and wish a copy, please send me a note through the contact page.
-
Ethan Roffler interviews CG Supervisor Daniele Tosti
Read more: Ethan Roffler interviews CG Supervisor Daniele TostiEthan Roffler
I recently had the honor of interviewing this VFX genius and gained great insight into what it takes to work in the entertainment industry. Keep in mind, these questions are coming from an artist’s perspective but can be applied to any creative individual looking for some wisdom from a professional. So grab a drink, sit back, and enjoy this fun and insightful conversation.
Ethan
To start, I just wanted to say thank you so much for taking the time for this interview!Daniele
My pleasure.
When I started my career I struggled to find help. Even people in the industry at the time were not that helpful. Because of that, I decided very early on that I was going to do exactly the opposite. I spend most of my weekends talking or helping students. ;)Ethan
(more…)
That’s awesome! I have also come across the same struggle! Just a heads up, this will probably be the most informal interview you’ll ever have haha! Okay, so let’s start with a small introduction! -
GretagMacbeth Color Checker Numeric Values and Middle Gray
Read more: GretagMacbeth Color Checker Numeric Values and Middle GrayThe human eye perceives half scene brightness not as the linear 50% of the present energy (linear nature values) but as 18% of the overall brightness. We are biased to perceive more information in the dark and contrast areas. A Macbeth chart helps with calibrating back into a photographic capture into this “human perspective” of the world.
https://en.wikipedia.org/wiki/Middle_gray
In photography, painting, and other visual arts, middle gray or middle grey is a tone that is perceptually about halfway between black and white on a lightness scale in photography and printing, it is typically defined as 18% reflectance in visible light

Light meters, cameras, and pictures are often calibrated using an 18% gray card[4][5][6] or a color reference card such as a ColorChecker. On the assumption that 18% is similar to the average reflectance of a scene, a grey card can be used to estimate the required exposure of the film.
https://en.wikipedia.org/wiki/ColorChecker
(more…) -
Debayer – A free command line tool to convert camera raw images into scene-linear exr
Read more: Debayer – A free command line tool to convert camera raw images into scene-linear exr
https://github.com/jedypod/debayer
The only required dependency is oiiotool. However other “debayer engines” are also supported.
- OpenImageIO – oiiotool is used for converting debayered tif images to exr.
- Debayer Engines
- RawTherapee – Powerful raw development software used to decode raw images. High quality, good selection of debayer algorithms, and more advanced raw processing like chromatic aberration removal.
- LibRaw – dcraw_emu commandline utility included with LibRaw. Optional alternative for debayer. Simple, fast and effective.
- Darktable – Uses darktable-cli plus an xmp config to process.
- vkdt – uses vkdt-cli to debayer. Pretty experimental still. Uses Vulkan for image processing. Stupidly fast. Pretty limited.
-
Narcis Calin’s Galaxy Engine – A free, open source simulation software
Read more: Narcis Calin’s Galaxy Engine – A free, open source simulation softwareThis 2025 I decided to start learning how to code, so I installed Visual Studio and I started looking into C++. After days of watching tutorials and guides about the basics of C++ and programming, I decided to make something physics-related. I started with a dot that fell to the ground and then I wanted to simulate gravitational attraction, so I made 2 circles attracting each other. I thought it was really cool to see something I made with code actually work, so I kept building on top of that small, basic program. And here we are after roughly 8 months of learning programming. This is Galaxy Engine, and it is a simulation software I have been making ever since I started my learning journey. It currently can simulate gravity, dark matter, galaxies, the Big Bang, temperature, fluid dynamics, breakable solids, planetary interactions, etc. The program can run many tens of thousands of particles in real time on the CPU thanks to the Barnes-Hut algorithm, mixed with Morton curves. It also includes its own PBR 2D path tracer with BVH optimizations. The path tracer can simulate a bunch of stuff like diffuse lighting, specular reflections, refraction, internal reflection, fresnel, emission, dispersion, roughness, IOR, nested IOR and more! I tried to make the path tracer closer to traditional 3D render engines like V-Ray. I honestly never imagined I would go this far with programming, and it has been an amazing learning experience so far. I think that mixing this knowledge with my 3D knowledge can unlock countless new possibilities. In case you are curious about Galaxy Engine, I made it completely free and Open-Source so that anyone can build and compile it locally! You can find the source code in GitHub
https://github.com/NarcisCalin/Galaxy-Engine
-
Insta360-Research-Team DiT360 – High-Fidelity Panoramic Image Generation via Hybrid Training
Read more: Insta360-Research-Team DiT360 – High-Fidelity Panoramic Image Generation via Hybrid Traininghttps://github.com/Insta360-Research-Team/DiT360
DiT360 is a framework for high-quality panoramic image generation, leveraging both perspective and panoramic data in a hybrid training scheme. It adopts a two-level strategy—image-level cross-domain guidance and token-level hybrid supervision—to enhance perceptual realism and geometric fidelity.

-
Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental process
Read more: Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental processhttps://www.chrbutler.com/understanding-the-eye-mind-connection
The intricate relationship between the eyes and the brain, often termed the eye-mind connection, reveals that vision is predominantly a cognitive process. This understanding has profound implications for fields such as design, where capturing and maintaining attention is paramount. This essay delves into the nuances of visual perception, the brain’s role in interpreting visual data, and how this knowledge can be applied to effective design strategies.
This cognitive aspect of vision is evident in phenomena such as optical illusions, where the brain interprets visual information in a way that contradicts physical reality. These illusions underscore that what we “see” is not merely a direct recording of the external world but a constructed experience shaped by cognitive processes.
Understanding the cognitive nature of vision is crucial for effective design. Designers must consider how the brain processes visual information to create compelling and engaging visuals. This involves several key principles:
- Attention and Engagement
- Visual Hierarchy
- Cognitive Load Management
- Context and Meaning










![[gamma correction test]](http://www.madore.org/~david/misc/color/gammatest.png "sRGB gamma correction test")

COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Convert 2D Images or Text to 3D Models
-
How does Stable Diffusion work?
-
Emmanuel Tsekleves – Writing Research Papers
-
Free fonts
-
Photography basics: Color Temperature and White Balance
-
How do LLMs like ChatGPT (Generative Pre-Trained Transformer) work? Explained by Deep-Fake Ryan Gosling
-
Guide to Prompt Engineering
-
Embedding frame ranges into Quicktime movies with FFmpeg
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
