


COMPOSITION
-
Cinematographers Blueprint 300dpi poster
Read more: Cinematographers Blueprint 300dpi posterThe 300dpi digital poster is now available to all PixelSham.com subscribers.

If you have already subscribed and wish a copy, please send me a note through the contact page.
-
Composition – These are the basic lighting techniques you need to know for photography and film
Read more: Composition – These are the basic lighting techniques you need to know for photography and film
http://www.diyphotography.net/basic-lighting-techniques-need-know-photography-film/
Amongst the basic techniques, there’s…
1- Side lighting – Literally how it sounds, lighting a subject from the side when they’re faced toward you
2- Rembrandt lighting – Here the light is at around 45 degrees over from the front of the subject, raised and pointing down at 45 degrees
3- Back lighting – Again, how it sounds, lighting a subject from behind. This can help to add drama with silouettes
4- Rim lighting – This produces a light glowing outline around your subject
5- Key light – The main light source, and it’s not necessarily always the brightest light source
6- Fill light – This is used to fill in the shadows and provide detail that would otherwise be blackness
7- Cross lighting – Using two lights placed opposite from each other to light two subjects
-
7 Commandments of Film Editing and composition
Read more: 7 Commandments of Film Editing and composition
1. Watch every frame of raw footage twice. On the second time, take notes. If you don’t do this and try to start developing a scene premature, then it’s a big disservice to yourself and to the director, actors and production crew.
2. Nurture the relationships with the director. You are the secondary person in the relationship. Be calm and continually offer solutions. Get the main intention of the film as soon as possible from the director.
3. Organize your media so that you can find any shot instantly.
4. Factor in extra time for renders, exports, errors and crashes.
5. Attempt edits and ideas that shouldn’t work. It just might work. Until you do it and watch it, you won’t know. Don’t rule out ideas just because they don’t make sense in your mind.
6. Spend more time on your audio. It’s the glue of your edit. AUDIO SAVES EVERYTHING. Create fluid and seamless audio under your video.
7. Make cuts for the scene, but always in context for the whole film. Have a macro and a micro view at all times.















DESIGN
-
Goga Tandashvili – bas-relief master
Read more: Goga Tandashvili – bas-relief master@moltenimmersiveart Goga Tandashvili is a master of the art of Bas-Relief. Using this technique, he creates stunning figures that are slightly raised from a flat surface, bringing scenes inspired by the natural world to life. #Art #Artists #GogaTandashvili #BasReliefSculpture #ArtInspiredByNature #ImpressionistArt #BasRelief #Sculptures #Sculptor #Molten #MoltenArt #MoltenImmersiveArt #MoltenAffect #Curation #Curator #ArtCuration #ArtCurator #DorothyDiStefano ♬ original sound – Molten Immersive Art


















































COLOR
-
OpenColorIO standard
Read more: OpenColorIO standardhttps://www.provideocoalition.com/color-management-part-11-introducing-opencolorio/
OpenColorIO (OCIO) is a new open source project from Sony Imageworks.
Based on development started in 2003, OCIO enables color transforms and image display to be handled in a consistent manner across multiple graphics applications. Unlike other color management solutions, OCIO is geared towards motion-picture post production, with an emphasis on visual effects and animation color pipelines.

-
Weta Digital – Manuka Raytracer and Gazebo GPU renderers – pipeline
Read more: Weta Digital – Manuka Raytracer and Gazebo GPU renderers – pipelinehttps://jo.dreggn.org/home/2018_manuka.pdf
http://www.fxguide.com/featured/manuka-weta-digitals-new-renderer/

The Manuka rendering architecture has been designed in the spirit of the classic reyes rendering architecture. In its core, reyes is based on stochastic rasterisation of micropolygons, facilitating depth of field, motion blur, high geometric complexity,and programmable shading.
This is commonly achieved with Monte Carlo path tracing, using a paradigm often called shade-on-hit, in which the renderer alternates tracing rays with running shaders on the various ray hits. The shaders take the role of generating the inputs of the local material structure which is then used bypath sampling logic to evaluate contributions and to inform what further rays to cast through the scene.
Over the years, however, the expectations have risen substantially when it comes to image quality. Computing pictures which are indistinguishable from real footage requires accurate simulation of light transport, which is most often performed using some variant of Monte Carlo path tracing. Unfortunately this paradigm requires random memory accesses to the whole scene and does not lend itself well to a rasterisation approach at all.
Manuka is both a uni-directional and bidirectional path tracer and encompasses multiple importance sampling (MIS). Interestingly, and importantly for production character skin work, it is the first major production renderer to incorporate spectral MIS in the form of a new ‘Hero Spectral Sampling’ technique, which was recently published at Eurographics Symposium on Rendering 2014.
Manuka propose a shade-before-hit paradigm in-stead and minimise I/O strain (and some memory costs) on the system, leveraging locality of reference by running pattern generation shaders before we execute light transport simulation by path sampling, “compressing” any bvh structure as needed, and as such also limiting duplication of source data.
The difference with reyes is that instead of baking colors into the geometry like in Reyes, manuka bakes surface closures. This means that light transport is still calculated with path tracing, but all texture lookups etc. are done up-front and baked into the geometry.The main drawback with this method is that geometry has to be tessellated to its highest, stable topology before shading can be evaluated properly. As such, the high cost to first pixel. Even a basic 4 vertices square becomes a much more complex model with this approach.

Manuka use the RenderMan Shading Language (rsl) for programmable shading [Pixar Animation Studios 2015], but we do not invoke rsl shaders when intersecting a ray with a surface (often called shade-on-hit). Instead, we pre-tessellate and pre-shade all the input geometry in the front end of the renderer.
This way, we can efficiently order shading computations to sup-port near-optimal texture locality, vectorisation, and parallelism. This system avoids repeated evaluation of shaders at the same surface point, and presents a minimal amount of memory to be accessed during light transport time. An added benefit is that the acceleration structure for ray tracing (abounding volume hierarchy, bvh) is built once on the final tessellated geometry, which allows us to ray trace more efficiently than multi-level bvhs and avoids costly caching of on-demand tessellated micropolygons and the associated scheduling issues.For the shading reasons above, in terms of AOVs, the studio approach is to succeed at combining complex shading with ray paths in the render rather than pass a multi-pass render to compositing.
For the Spectral Rendering component. The light transport stage is fully spectral, using a continuously sampled wavelength which is traced with each path and used to apply the spectral camera sensitivity of the sensor. This allows for faithfully support any degree of observer metamerism as the camera footage they are intended to match as well as complex materials which require wavelength dependent phenomena such as diffraction, dispersion, interference, iridescence, or chromatic extinction and Rayleigh scattering in participating media.
As opposed to the original reyes paper, we use bilinear interpolation of these bsdf inputs later when evaluating bsdfs per pathv ertex during light transport4. This improves temporal stability of geometry which moves very slowly with respect to the pixel raster
In terms of the pipeline, everything rendered at Weta was already completely interwoven with their deep data pipeline. Manuka very much was written with deep data in mind. Here, Manuka not so much extends the deep capabilities, rather it fully matches the already extremely complex and powerful setup Weta Digital already enjoy with RenderMan. For example, an ape in a scene can be selected, its ID is available and a NUKE artist can then paint in 3D say a hand and part of the way up the neutral posed ape.
We called our system Manuka, as a respectful nod to reyes: we had heard a story froma former ILM employee about how reyes got its name from how fond the early Pixar people were of their lunches at Point Reyes, and decided to name our system after our surrounding natural environment, too. Manuka is a kind of tea tree very common in New Zealand which has very many very small leaves, in analogy to micropolygons ina tree structure for ray tracing. It also happens to be the case that Weta Digital’s main site is on Manuka Street.

-
Anders Langlands – Render Color Spaces
Read more: Anders Langlands – Render Color Spaceshttps://www.colour-science.org/anders-langlands/
This page compares images rendered in Arnold using spectral rendering and different sets of colourspace primaries: Rec.709, Rec.2020, ACES and DCI-P3. The SPD data for the GretagMacbeth Color Checker are the measurements of Noburu Ohta, taken from Mansencal, Mauderer and Parsons (2014) colour-science.org.

-
Polarised vs unpolarized filtering
Read more: Polarised vs unpolarized filteringA light wave that is vibrating in more than one plane is referred to as unpolarized light. …
Polarized light waves are light waves in which the vibrations occur in a single plane. The process of transforming unpolarized light into polarized light is known as polarization.

en.wikipedia.org/wiki/Polarizing_filter_(photography)
The most common use of polarized technology is to reduce lighting complexity on the subject.
(more…)
Details such as glare and hard edges are not removed, but greatly reduced.












LIGHTING
-
Narcis Calin’s Galaxy Engine – A free, open source simulation software
Read more: Narcis Calin’s Galaxy Engine – A free, open source simulation softwareThis 2025 I decided to start learning how to code, so I installed Visual Studio and I started looking into C++. After days of watching tutorials and guides about the basics of C++ and programming, I decided to make something physics-related. I started with a dot that fell to the ground and then I wanted to simulate gravitational attraction, so I made 2 circles attracting each other. I thought it was really cool to see something I made with code actually work, so I kept building on top of that small, basic program. And here we are after roughly 8 months of learning programming. This is Galaxy Engine, and it is a simulation software I have been making ever since I started my learning journey. It currently can simulate gravity, dark matter, galaxies, the Big Bang, temperature, fluid dynamics, breakable solids, planetary interactions, etc. The program can run many tens of thousands of particles in real time on the CPU thanks to the Barnes-Hut algorithm, mixed with Morton curves. It also includes its own PBR 2D path tracer with BVH optimizations. The path tracer can simulate a bunch of stuff like diffuse lighting, specular reflections, refraction, internal reflection, fresnel, emission, dispersion, roughness, IOR, nested IOR and more! I tried to make the path tracer closer to traditional 3D render engines like V-Ray. I honestly never imagined I would go this far with programming, and it has been an amazing learning experience so far. I think that mixing this knowledge with my 3D knowledge can unlock countless new possibilities. In case you are curious about Galaxy Engine, I made it completely free and Open-Source so that anyone can build and compile it locally! You can find the source code in GitHub
https://github.com/NarcisCalin/Galaxy-Engine
-
Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacy
Read more: Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacynofilmschool.com/types-of-film-lights
“Not every light performs the same way. Lights and lighting are tricky to handle. You have to plan for every circumstance. But the good news is, lighting can be adjusted. Let’s look at different factors that affect lighting in every scene you shoot. “
Use CRI, Luminous Efficacy and color temperature controls to match your needs.
Color Temperature
Color temperature describes the “color” of white light by a light source radiated by a perfect black body at a given temperature measured in degrees Kelvinhttps://www.pixelsham.com/2019/10/18/color-temperature/
CRI
“The Color Rendering Index is a measurement of how faithfully a light source reveals the colors of whatever it illuminates, it describes the ability of a light source to reveal the color of an object, as compared to the color a natural light source would provide. The highest possible CRI is 100. A CRI of 100 generally refers to a perfect black body, like a tungsten light source or the sun. “https://www.studiobinder.com/blog/what-is-color-rendering-index
(more…) -
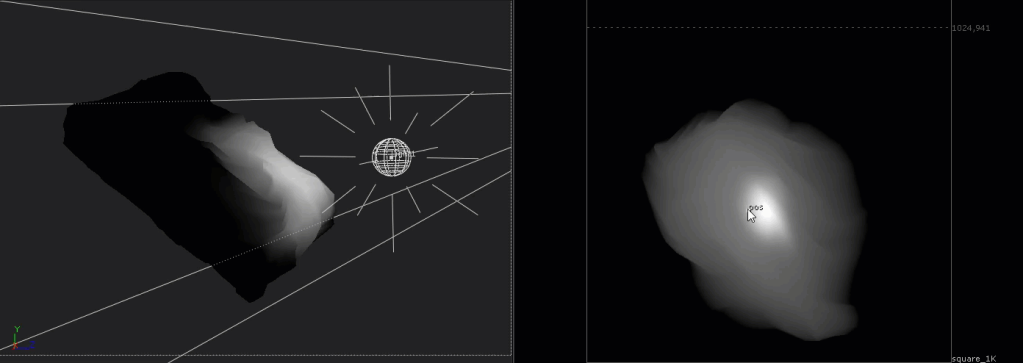
Neural Microfacet Fields for Inverse Rendering
Read more: Neural Microfacet Fields for Inverse Renderinghttps://half-potato.gitlab.io/posts/nmf/













COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
QR code logos
-
Daniele Tosti Interview for the magazine InCG, Taiwan, Issue 28, 201609
-
Want to build a start up company that lasts? Think three-layer cake
-
Canva bought Affinity – Now Affinity Photo and Affinity Designer are… GONE?!
-
Game Development tips
-
Eddie Yoon – There’s a big misconception about AI creative
-
Tencent Hunyuan3D 2.1 goes Open Source and adds MV (Multi-view) and MV Mini
-
Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminance
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
