Spectral sensitivity of eye is influenced by light intensity. And the light intensity determines the level of activity of cones cell and rod cell. This is the main characteristic of human vision. Sensitivity to individual colors, in other words, wavelengths of the light spectrum, is explained by the RGB (red-green-blue) theory. This theory assumed that there are three kinds of cones. It’s selectively sensitive to red (700-630 nm), green (560-500 nm), and blue (490-450 nm) light. And their mutual interaction allow to perceive all colors of the spectrum.
By stimulating specific cells in the retina, the participants claim to have witnessed a blue-green colour that scientists have called “olo”, but some experts have said the existence of a new colour is “open to argument”.
The findings, published in the journal Science Advances on Friday, have been described by the study’s co-author, Prof Ren Ng from the University of California, as “remarkable”.
(A) System inputs. (i) Retina map of 103 cone cells preclassified by spectral type (7). (ii) Target visual percept (here, a video of a child, see movie S1 at 1:04). (iii) Infrared cellular-scale imaging of the retina with 60-frames-per-second rolling shutter. Fixational eye movement is visible over the three frames shown.
(B) System outputs. (iv) Real-time per-cone target activation levels to reproduce the target percept, computed by: extracting eye motion from the input video relative to the retina map; identifying the spectral type of every cone in the field of view; computing the per-cone activation the target percept would have produced. (v) Intensities of visible-wavelength 488-nm laser microdoses at each cone required to achieve its target activation level.
(C) Infrared imaging and visible-wavelength stimulation are physically accomplished in a raster scan across the retinal region using AOSLO. By modulating the visible-wavelength beam’s intensity, the laser microdoses shown in (v) are delivered. Drawing adapted with permission [Harmening and Sincich (54)].
(D) Examples of target percepts with corresponding cone activations and laser microdoses, ranging from colored squares to complex imagery. Teal-striped regions represent the color “olo” of stimulating only M cones.
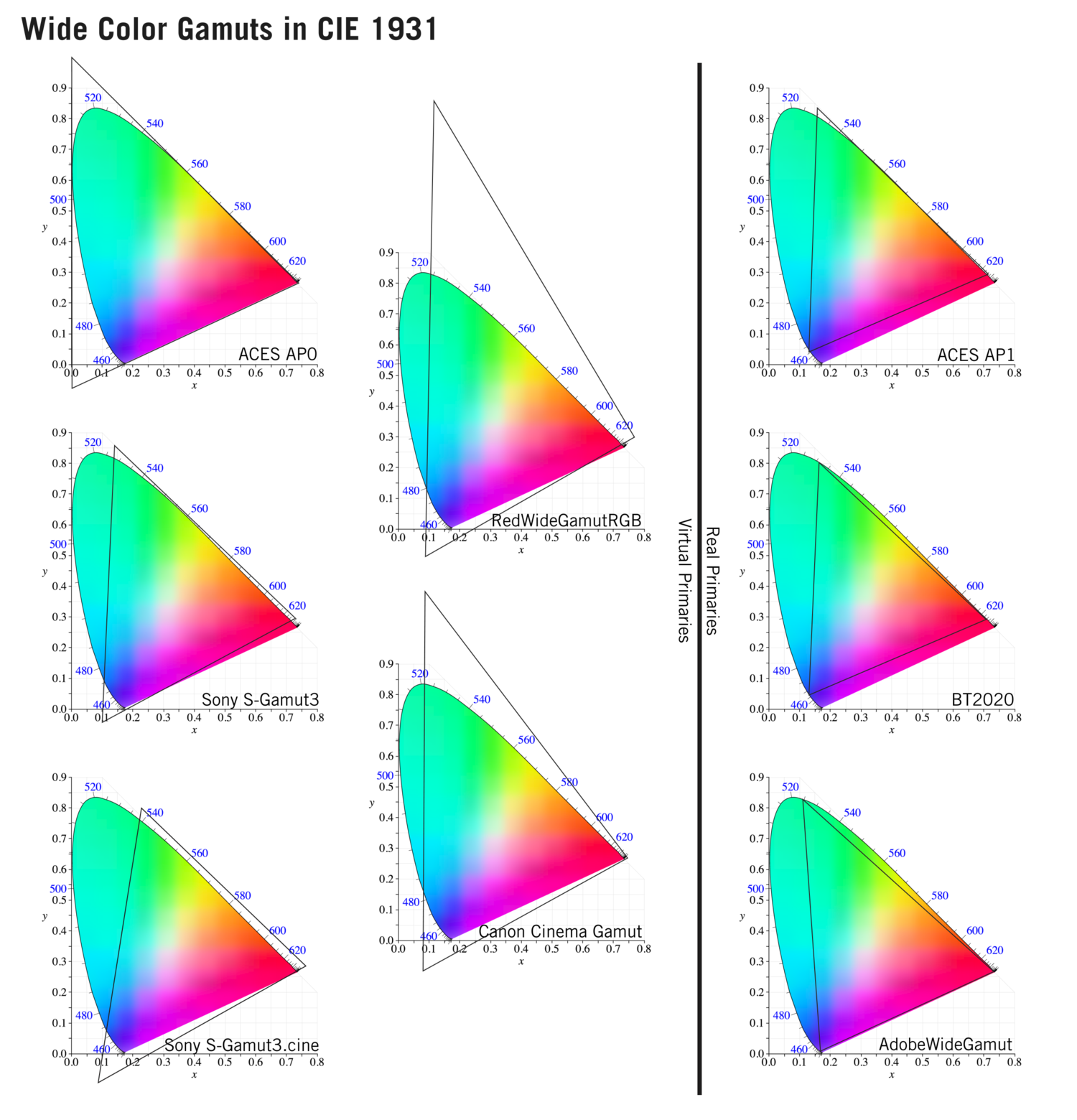
In video terms gamut is normally related to as the full range of colours and brightness that can be either captured or displayed.
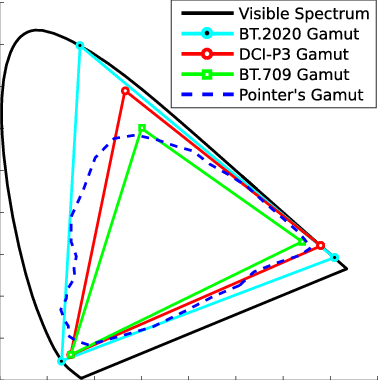
Generally speaking all color gamuts recommendations are trying to define a reasonable level of color representation based on available technology and hardware. REC-601 represents the old TVs. REC-709 is currently the most distributed solution. P3 is mainly available in movie theaters and is now being adopted in some of the best new 4K HDR TVs. Rec2020 (a wider space than P3 that improves on visibke color representation) and ACES (the full coverage of visible color) are other common standards which see major hardware development these days.
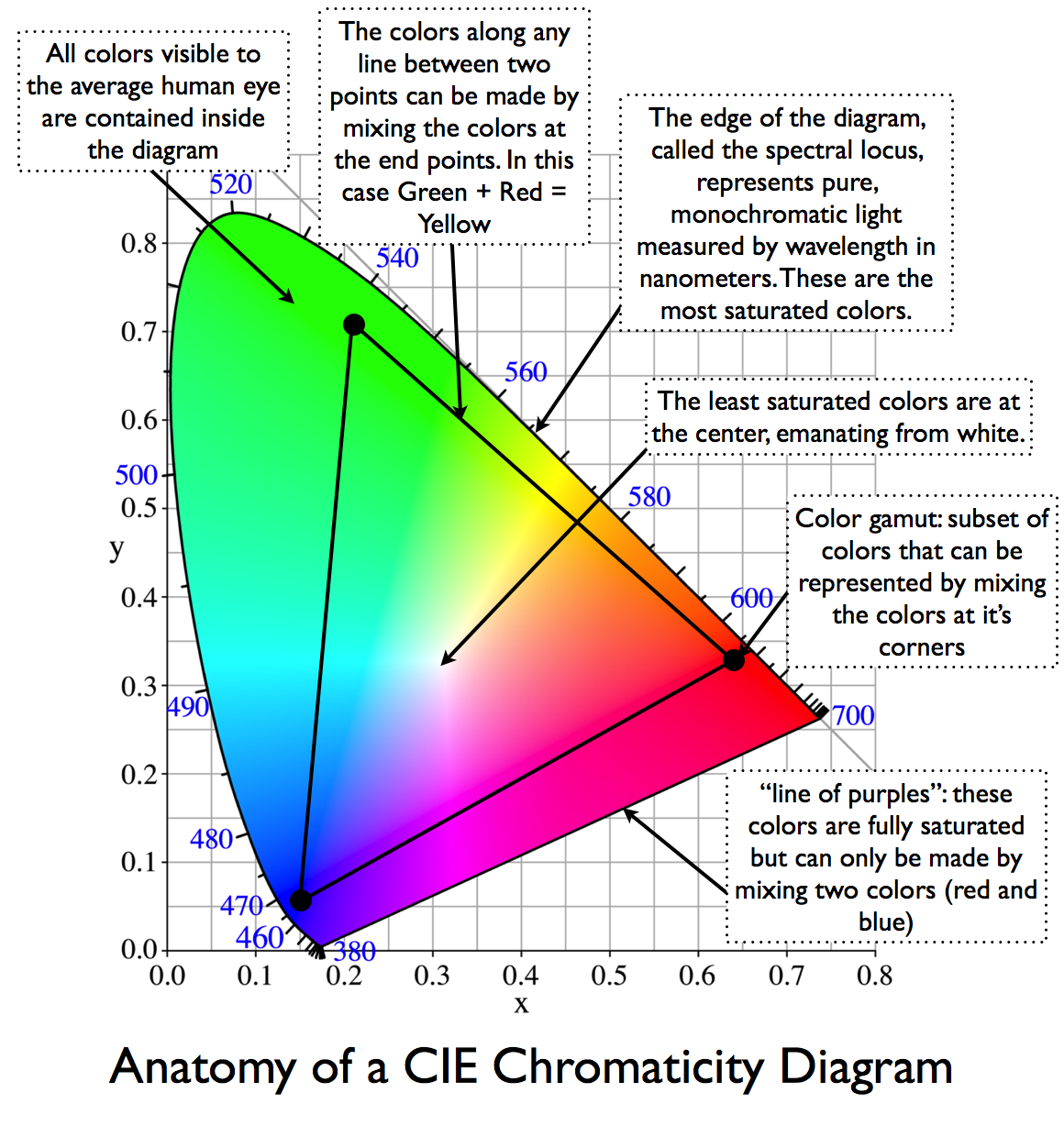
To compare and visualize different solution (across video and printing solutions), most developers use the CIE color model chart as a reference.
The CIE color model is a color space model created by the International Commission on Illumination known as the Commission Internationale de l’Elcairage (CIE) in 1931. It is also known as the CIE XYZ color space or the CIE 1931 XYZ color space.
This chart represents the first defined quantitative link between distributions of wavelengths in the electromagnetic visible spectrum, and physiologically perceived colors in human color vision. Or basically, the range of color a typical human eye can perceive through visible light.
Note that while the human perception is quite wide, and generally speaking biased towards greens (we are apes after all), the amount of colors available through nature, generated through light reflection, tend to be a much smaller section. This is defined by the Pointer’s Chart.
In short. Color gamut is a representation of color coverage, used to describe data stored in images against available hardware and viewer technologies.
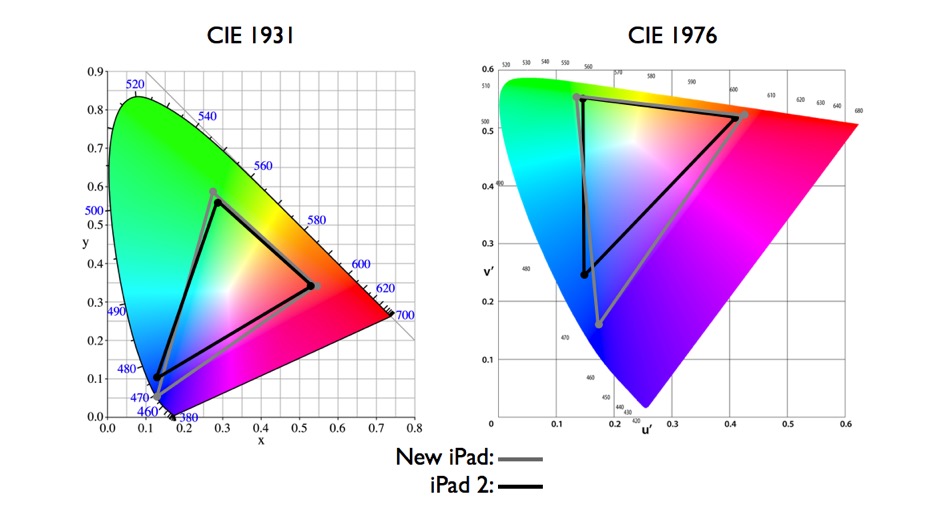
The CIE 1931 standard has been replaced by a CIE 1976 standard. Below we can see the significance of this.
People have observed that the biggest issue with CIE 1931 is the lack of uniformity with chromaticity, the three dimension color space in rectangular coordinates is not visually uniformed.
The CIE 1976 (also called CIELUV) was created by the CIE in 1976. It was put forward in an attempt to provide a more uniform color spacing than CIE 1931 for colors at approximately the same luminance
The CIE 1976 standard colour space is more linear and variations in perceived colour between different people has also been reduced. The disproportionately large green-turquoise area in CIE 1931, which cannot be generated with existing computer screens, has been reduced.
If we move from CIE 1931 to the CIE 1976 standard colour space we can see that the improvements made in the gamut for the “new” iPad screen (as compared to the “old” iPad 2) are more evident in the CIE 1976 colour space than in the CIE 1931 colour space, particularly in the blues from aqua to deep blue.
Despite its age, CIE 1931, named for the year of its adoption, remains a well-worn and familiar shorthand throughout the display industry. CIE 1931 is the primary language of customers. When a customer says that their current display “can do 72% of NTSC,” they implicitly mean 72% of NTSC 1953 color gamut as mapped against CIE 1931.
A number of problems in computer vision and related fields would be mitigated if camera spectral sensitivities were known. As consumer cameras are not designed for high-precision visual tasks, manufacturers do not disclose spectral sensitivities. Their estimation requires a costly optical setup, which triggered researchers to come up with numerous indirect methods that aim to lower cost and complexity by using color targets. However, the use of color targets gives rise to new complications that make the estimation more difficult, and consequently, there currently exists no simple, low-cost, robust go-to method for spectral sensitivity estimation that non-specialized research labs can adopt. Furthermore, even if not limited by hardware or cost, researchers frequently work with imagery from multiple cameras that they do not have in their possession.
To provide a practical solution to this problem, we propose a framework for spectral sensitivity estimation that not only does not require any hardware (including a color target), but also does not require physical access to the camera itself. Similar to other work, we formulate an optimization problem that minimizes a two-term objective function: a camera-specific term from a system of equations, and a universal term that bounds the solution space.
Different than other work, we utilize publicly available high-quality calibration data to construct both terms. We use the colorimetric mapping matrices provided by the Adobe DNG Converter to formulate the camera-specific system of equations, and constrain the solutions using an autoencoder trained on a database of ground-truth curves. On average, we achieve reconstruction errors as low as those that can arise due to manufacturing imperfections between two copies of the same camera. We provide predicted sensitivities for more than 1,000 cameras that the Adobe DNG Converter currently supports, and discuss which tasks can become trivial when camera responses are available.
Ethan Roffler I recently had the honor of interviewing this VFX genius and gained great insight into what it takes to work in the entertainment industry. Keep in mind, these questions are coming from an artist’s perspective but can be applied to any creative individual looking for some wisdom from a professional. So grab a drink, sit back, and enjoy this fun and insightful conversation.
Ethan To start, I just wanted to say thank you so much for taking the time for this interview!
Daniele My pleasure. When I started my career I struggled to find help. Even people in the industry at the time were not that helpful. Because of that, I decided very early on that I was going to do exactly the opposite. I spend most of my weekends talking or helping students. ;)
Ethan That’s awesome! I have also come across the same struggle! Just a heads up, this will probably be the most informal interview you’ll ever have haha! Okay, so let’s start with a small introduction!
LightIt is a script for Maya and Arnold that will help you and improve your lighting workflow.
Thanks to preset studio lighting components (lights, backdrop…), high quality studio scenes and HDRI library manager.
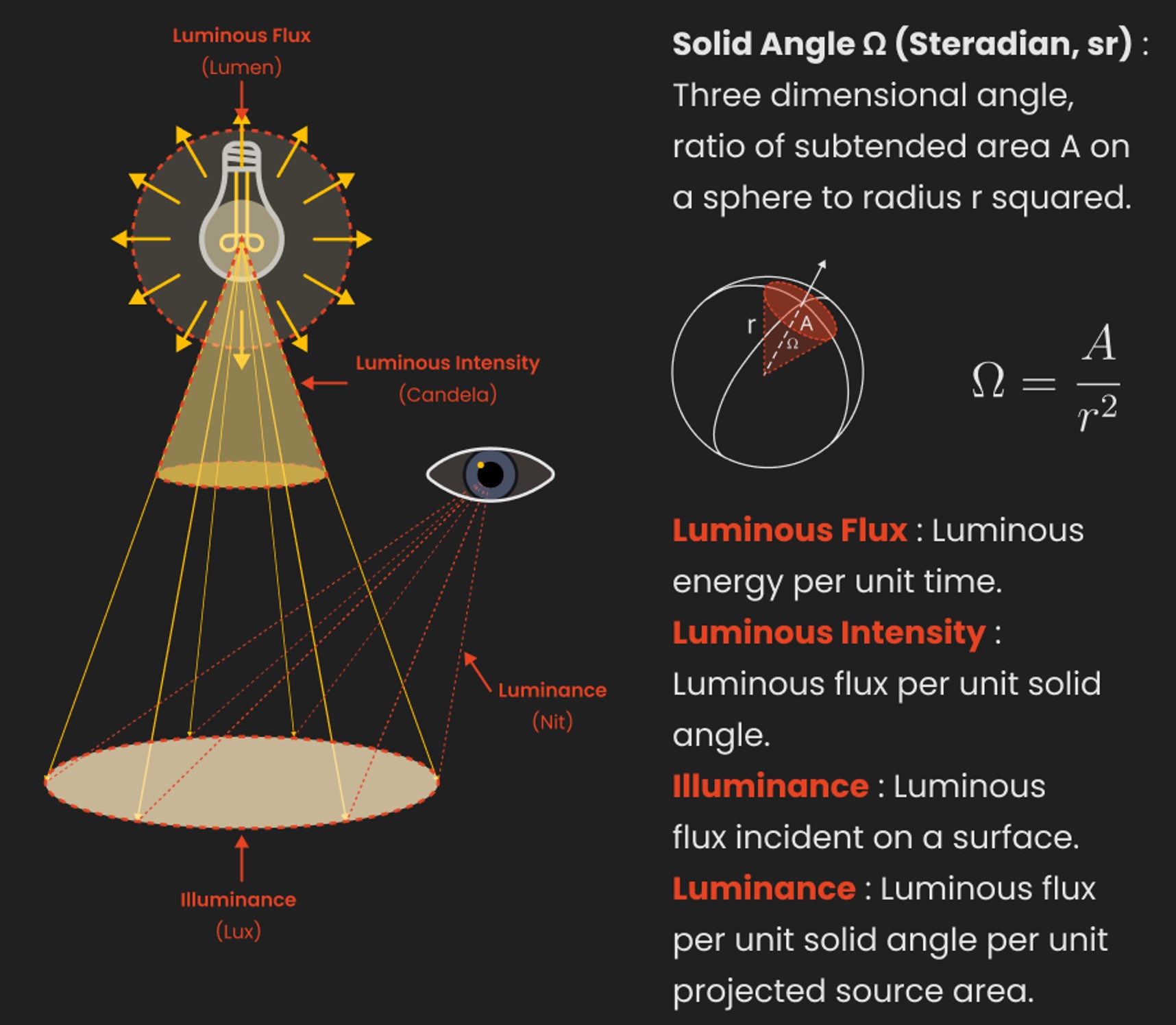
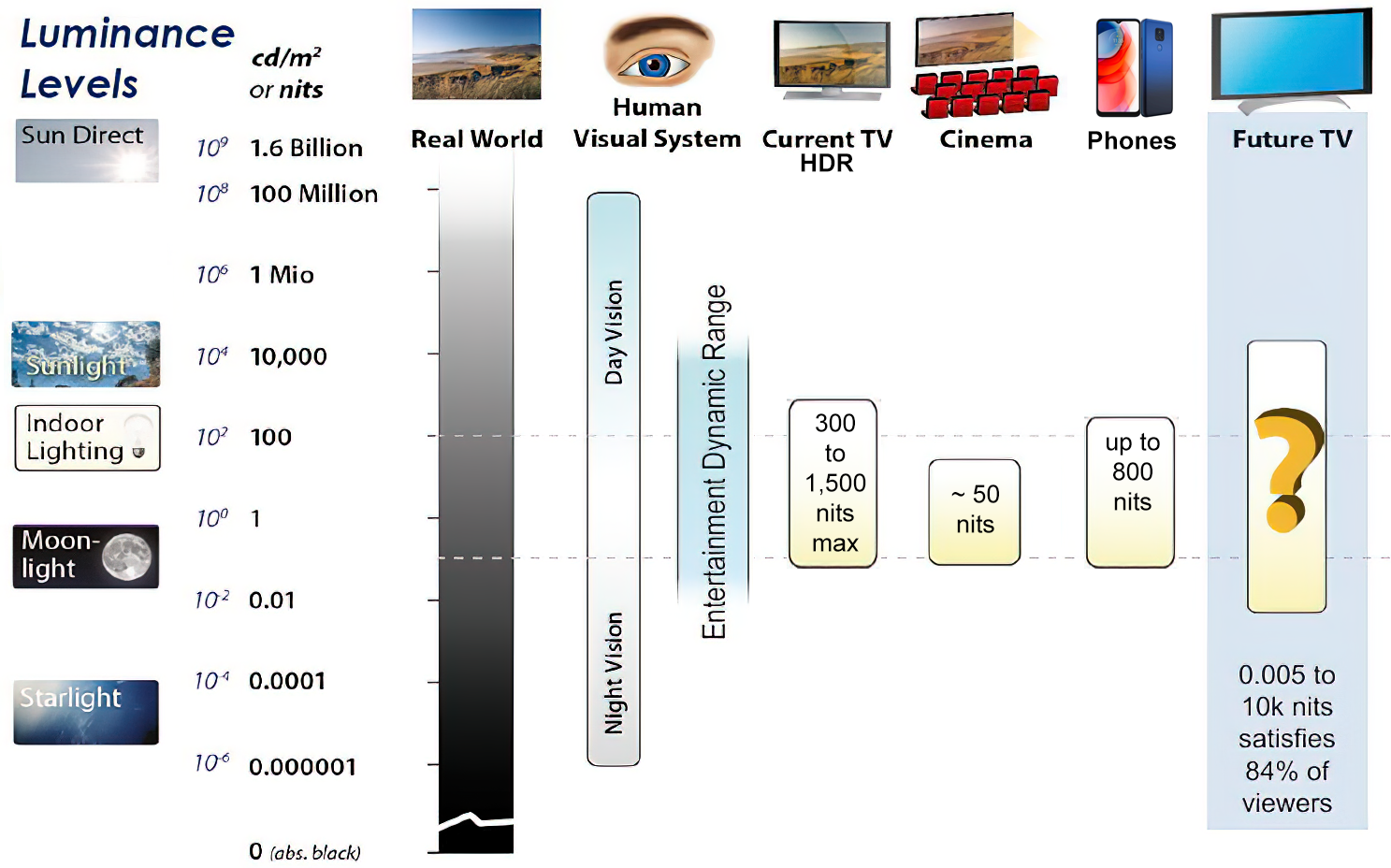
Candela is the basic unit of measure of the entire volume of light intensity from any point in a single direction from a light source. Note the detail: it measures the total volume of light within a certain beam angle and direction.
While the luminance of starlight is around 0.001 cd/m2, that of a sunlit scene is around 100,000 cd/m2, which is a hundred millions times higher. The luminance of the sun itself is approximately 1,000,000,000 cd/m2.
The candela per square metre (symbol: cd/m2) is the unit of luminance in the International System of Units (SI). The unit is based on the candela, the SI unit of luminous intensity, and the square metre, the SI unit of area. The nit (symbol: nt) is a non-SI name also used for this unit (1 nt = 1 cd/m2).[1] The term nit is believed to come from the Latin word nitēre, “to shine”. As a measure of light emitted per unit area, this unit is frequently used to specify the brightness of a display device.
NIT and cd/m2 (candela power) represent the same thing and can be used interchangeably. One nit is equivalent to one candela per square meter, where the candela is the amount of light which has been emitted by a common tallow candle, but NIT is not part of the International System of Units (abbreviated SI, from Systeme International, in French).
It’s easiest to think of a TV as emitting light directly, in much the same way as the Sun does. Nits are simply the measurement of the level of light (luminance) in a given area which the emitting source sends to your eyes or a camera sensor.
The Nit can be considered a unit of visible-light intensity which is often used to specify the brightness level of an LCD.
1 Nit is approximately equal to 3.426 Lumens. To work out a comparable number of Nits to Lumens, you need to multiply the number of Nits by 3.426. If you know the number of Lumens, and wish to know the Nits, simply divide the number of Lumens by 3.426.
Most consumer desktop LCDs have Nits of 200 to 300, the average TV most likely has an output capability of between 100 and 200 Nits, and an HDR TV ranges from 400 to 1,500 Nits.
Virtual Production sets currently sport around 6000 NIT ceiling and 1000 NIT wall panels.
The ambient brightness of a sunny day with clear blue skies is between 7000-10,000 nits (between 3000-7000 nits for overcast skies and indirect sunlight).
A bright sunny day can have specular highlights that reach over 100,000 nits. Direct sunlight is around 1,600,000,000 nits.
10,000 nits is also the typical brightness of a fluorescent tube – bright, but not painful to look at.
Tests showed that a “black level” of 0.005 nits (cd/m²) satisfied the vast majority of viewers. While 0.005 nits is very close to true black, Griffis says Dolby can go down to a black of 0.0001 nits, even though there is no need or ability for displays to get that dark today.
How bright is white? Dolby says the range of 0.005 nits – 10,000 nits satisfied 84% of the viewers in their viewing tests.
The brightest consumer HDR displays today are about 1,500 nits. Professional displays where HDR content is color-graded can achieve up to 4,000 nits peak brightness.
High brightness that would be in danger of damaging the eye would be in the neighborhood of 250,000 nits.
Lumens
Lumen is a measure of how much light is emitted (luminance, luminous flux) by an object. It indicates the total potential amount of light from a light source that is visible to the human eye.
Lumen is commonly used in the context of light bulbs or video-projectors as a metric for their brightness power.
Lumen is used to describe light output, and about video projectors, it is commonly referred to as ANSI Lumens. Simply put, lumens is how to find out how bright a LED display is. The higher the lumens, the brighter to display!
Technically speaking, a Lumen is the SI unit of luminous flux, which is equal to the amount of light which is emitted per second in a unit solid angle of one steradian from a uniform source of one-candela intensity radiating in all directions.
LUX
Lux(lx) or often Illuminance, is a photometric unit along a given area, which takes in account the sensitivity of human eye to different wavelenghts. It is the measure of light at a specific distance within a specific area at that distance. Often used to measure the incidental sun’s intensity.
RASTERIZATION Rasterisation (or rasterization) is the task of taking the information described in a vector graphics format OR the vertices of triangles making 3D shapes and converting them into a raster image (a series of pixels, dots or lines, which, when displayed together, create the image which was represented via shapes), or in other words “rasterizing” vectors or 3D models onto a 2D plane for display on a computer screen.
For each triangle of a 3D shape, you project the corners of the triangle on the virtual screen with some math (projective geometry). Then you have the position of the 3 corners of the triangle on the pixel screen. Those 3 points have texture coordinates, so you know where in the texture are the 3 corners. The cost is proportional to the number of triangles, and is only a little bit affected by the screen resolution.
In computer graphics, a raster graphics orbitmap image is a dot matrix data structure that represents a generally rectangular grid of pixels (points of color), viewable via a monitor, paper, or other display medium.
With rasterization, objects on the screen are created from a mesh of virtual triangles, or polygons, that create 3D models of objects. A lot of information is associated with each vertex, including its position in space, as well as information about color, texture and its “normal,” which is used to determine the way the surface of an object is facing.
Computers then convert the triangles of the 3D models into pixels, or dots, on a 2D screen. Each pixel can be assigned an initial color value from the data stored in the triangle vertices.
Further pixel processing or “shading,” including changing pixel color based on how lights in the scene hit the pixel, and applying one or more textures to the pixel, combine to generate the final color applied to a pixel.
The main advantage of rasterization is its speed. However, rasterization is simply the process of computing the mapping from scene geometry to pixels and does not prescribe a particular way to compute the color of those pixels. So it cannot take shading, especially the physical light, into account and it cannot promise to get a photorealistic output. That’s a big limitation of rasterization.
There are also multiple problems:
If you have two triangles one is behind the other, you will draw twice all the pixels. you only keep the pixel from the triangle that is closer to you (Z-buffer), but you still do the work twice.
The borders of your triangles are jagged as it is hard to know if a pixel is in the triangle or out. You can do some smoothing on those, that is anti-aliasing.
You have to handle every triangles (including the ones behind you) and then see that they do not touch the screen at all. (we have techniques to mitigate this where we only look at triangles that are in the field of view)
Transparency is hard to handle (you can’t just do an average of the color of overlapping transparent triangles, you have to do it in the right order)
RAY CASTING It is almost the exact reverse of rasterization: you start from the virtual screen instead of the vector or 3D shapes, and you project a ray, starting from each pixel of the screen, until it intersect with a triangle.
The cost is directly correlated to the number of pixels in the screen and you need a really cheap way of finding the first triangle that intersect a ray. In the end, it is more expensive than rasterization but it will, by design, ignore the triangles that are out of the field of view.
You can use it to continue after the first triangle it hit, to take a little bit of the color of the next one, etc… This is useful to handle the border of the triangle cleanly (less jagged) and to handle transparency correctly.
RAYTRACING
Same idea as ray casting except once you hit a triangle you reflect on it and go into a different direction. The number of reflection you allow is the “depth” of your ray tracing. The color of the pixel can be calculated, based off the light source and all the polygons it had to reflect off of to get to that screen pixel.
The easiest way to think of ray tracing is to look around you, right now. The objects you’re seeing are illuminated by beams of light. Now turn that around and follow the path of those beams backwards from your eye to the objects that light interacts with. That’s ray tracing.
Ray tracing is eye-oriented process that needs walking through each pixel looking for what object should be shown there, which is also can be described as a technique that follows a beam of light (in pixels) from a set point and simulates how it reacts when it encounters objects.
Compared with rasterization, ray tracing is hard to be implemented in real time, since even one ray can be traced and processed without much trouble, but after one ray bounces off an object, it can turn into 10 rays, and those 10 can turn into 100, 1000…The increase is exponential, and the the calculation for all these rays will be time consuming.
Historically, computer hardware hasn’t been fast enough to use these techniques in real time, such as in video games. Moviemakers can take as long as they like to render a single frame, so they do it offline in render farms. Video games have only a fraction of a second. As a result, most real-time graphics rely on the another technique called rasterization.
PATH TRACING Path tracing can be used to solve more complex lighting situations. Path tracing is a type of ray tracing. When using path tracing for rendering, the rays only produce a single ray per bounce. The rays do not follow a defined line per bounce(to a light, for example), but rather shoot off in a random direction. The path tracing algorithm then takes a random sampling of all of the rays to create the final image. This results in sampling a variety of different types of lighting.
When a ray hits a surface it doesn’t trace a path to every light source, instead it bounces the ray off the surface and keeps bouncing it until it hits a light source or exhausts some bounce limit. It then calculates the amount of light transferred all the way to the pixel, including any color information gathered from surfaces along the way. It then averages out the values calculated from all the paths that were traced into the scene to get the final pixel color value.
It requires a ton of computing power and if you don’t send out enough rays per pixel or don’t trace the paths far enough into the scene then you end up with a very spotty image as many pixels fail to find any light sources from their rays. So when you increase the the samples per pixel, you can see the image quality becomes better and better.
Ray tracing tends to be more efficient than path tracing. Basically, the render time of a ray tracer depends on the number of polygons in the scene. The more polygons you have, the longer it will take. Meanwhile, the rendering time of a path tracer can be indifferent to the number of polygons, but it is related to light situation: If you add a light, transparency, translucence, or other shader effects, the path tracer will slow down considerably.
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.











































 Local copy:
Local copy:































{kind=link}
