


COMPOSITION
-
Composition – These are the basic lighting techniques you need to know for photography and film
Read more: Composition – These are the basic lighting techniques you need to know for photography and film
http://www.diyphotography.net/basic-lighting-techniques-need-know-photography-film/
Amongst the basic techniques, there’s…
1- Side lighting – Literally how it sounds, lighting a subject from the side when they’re faced toward you
2- Rembrandt lighting – Here the light is at around 45 degrees over from the front of the subject, raised and pointing down at 45 degrees
3- Back lighting – Again, how it sounds, lighting a subject from behind. This can help to add drama with silouettes
4- Rim lighting – This produces a light glowing outline around your subject
5- Key light – The main light source, and it’s not necessarily always the brightest light source
6- Fill light – This is used to fill in the shadows and provide detail that would otherwise be blackness
7- Cross lighting – Using two lights placed opposite from each other to light two subjects




















DESIGN
COLOR
-
colorhunt.co
Read more: colorhunt.coColor Hunt is a free and open platform for color inspiration with thousands of trendy hand-picked color palettes.

-
Capturing the world in HDR for real time projects – Call of Duty: Advanced Warfare
Read more: Capturing the world in HDR for real time projects – Call of Duty: Advanced WarfareReal-World Measurements for Call of Duty: Advanced Warfare
www.activision.com/cdn/research/Real_World_Measurements_for_Call_of_Duty_Advanced_Warfare.pdf
Local version
Real_World_Measurements_for_Call_of_Duty_Advanced_Warfare.pdf

-
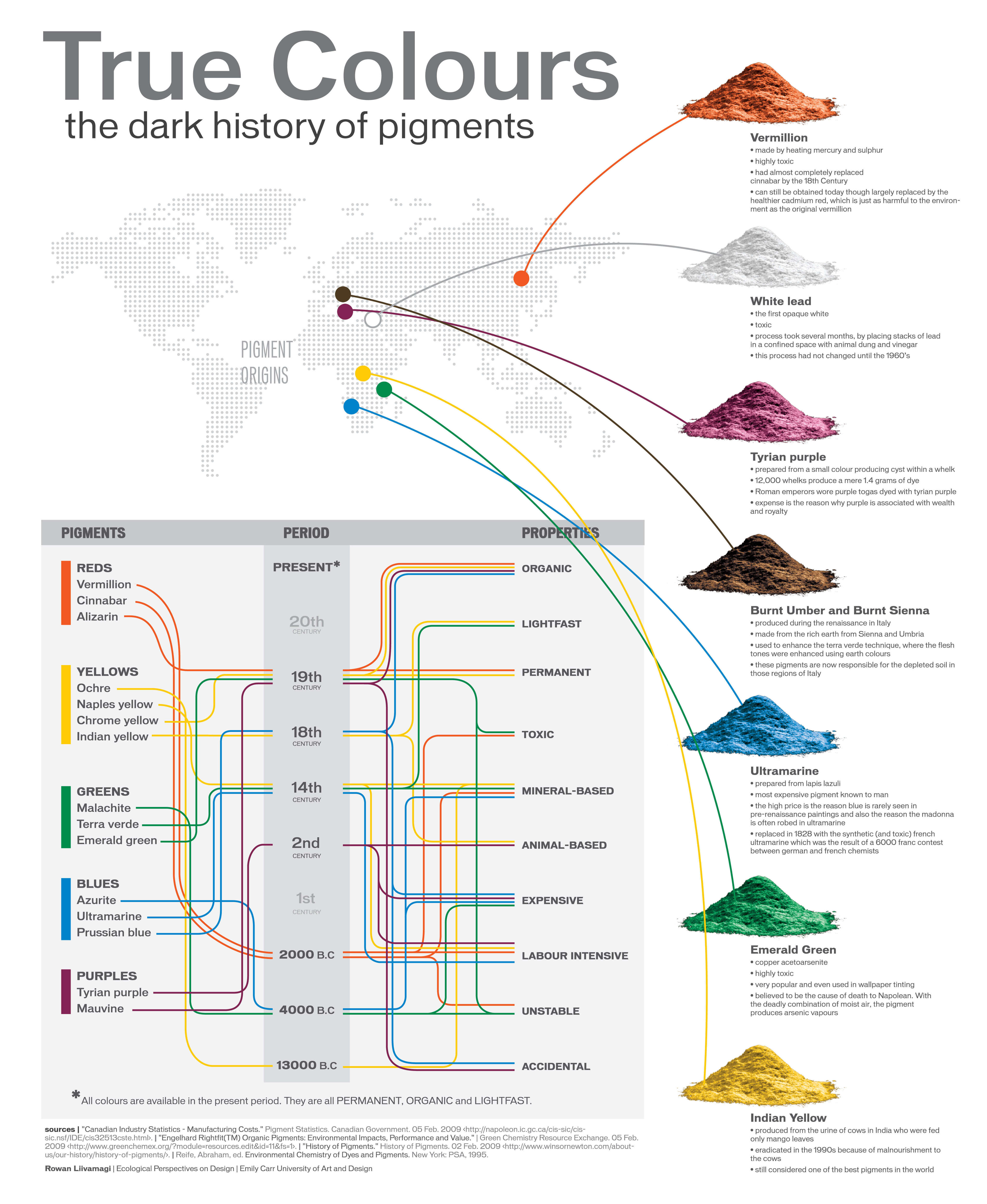
The Maya civilization and the color blue
Read more: The Maya civilization and the color blueMaya blue is a highly unusual pigment because it is a mix of organic indigo and an inorganic clay mineral called palygorskite.
Echoing the color of an azure sky, the indelible pigment was used to accentuate everything from ceramics to human sacrifices in the Late Preclassic period (300 B.C. to A.D. 300).
A team of researchers led by Dean Arnold, an adjunct curator of anthropology at the Field Museum in Chicago, determined that the key to Maya blue was actually a sacred incense called copal.
By heating the mixture of indigo, copal and palygorskite over a fire, the Maya produced the unique pigment, he reported at the time.
-
A Brief History of Color in Art
Read more: A Brief History of Color in Artwww.artsy.net/article/the-art-genome-project-a-brief-history-of-color-in-art
Of all the pigments that have been banned over the centuries, the color most missed by painters is likely Lead White.
This hue could capture and reflect a gleam of light like no other, though its production was anything but glamorous. The 17th-century Dutch method for manufacturing the pigment involved layering cow and horse manure over lead and vinegar. After three months in a sealed room, these materials would combine to create flakes of pure white. While scientists in the late 19th century identified lead as poisonous, it wasn’t until 1978 that the United States banned the production of lead white paint.
More reading:
www.canva.com/learn/color-meanings/https://www.infogrades.com/history-events-infographics/bizarre-history-of-colors/

-
Victor Perez – ACES Color Management in DaVinci Resolve
Read more: Victor Perez – ACES Color Management in DaVinci Resolvehttpv://www.youtube.com/watch?v=i–TS88-6xA
-
Capturing textures albedo
Read more: Capturing textures albedoBuilding a Portable PBR Texture Scanner by Stephane Lb
http://rtgfx.com/pbr-texture-scanner/

How To Split Specular And Diffuse In Real Images, by John Hable
http://filmicworlds.com/blog/how-to-split-specular-and-diffuse-in-real-images/Capturing albedo using a Spectralon
https://www.activision.com/cdn/research/Real_World_Measurements_for_Call_of_Duty_Advanced_Warfare.pdfReal_World_Measurements_for_Call_of_Duty_Advanced_Warfare.pdf
Spectralon is a teflon-based pressed powderthat comes closest to being a pure Lambertian diffuse material that reflects 100% of all light. If we take an HDR photograph of the Spectralon alongside the material to be measured, we can derive thediffuse albedo of that material.

The process to capture diffuse reflectance is very similar to the one outlined by Hable.
1. We put a linear polarizing filter in front of the camera lens and a second linear polarizing filterin front of a modeling light or a flash such that the two filters are oriented perpendicular to eachother, i.e. cross polarized.
2. We place Spectralon close to and parallel with the material we are capturing and take brack-eted shots of the setup7. Typically, we’ll take nine photographs, from -4EV to +4EV in 1EVincrements.
3. We convert the bracketed shots to a linear HDR image. We found that many HDR packagesdo not produce an HDR image in which the pixel values are linear. PTGui is an example of apackage which does generate a linear HDR image. At this point, because of the cross polarization,the image is one of surface diffuse response.
4. We open the file in Photoshop and normalize the image by color picking the Spectralon, filling anew layer with that color and setting that layer to “Divide”. This sets the Spectralon to 1 in theimage. All other color values are relative to this so we can consider them as diffuse albedo.


![[gamma correction test]](http://www.madore.org/~david/misc/color/gammatest.png "sRGB gamma correction test")









LIGHTING
-
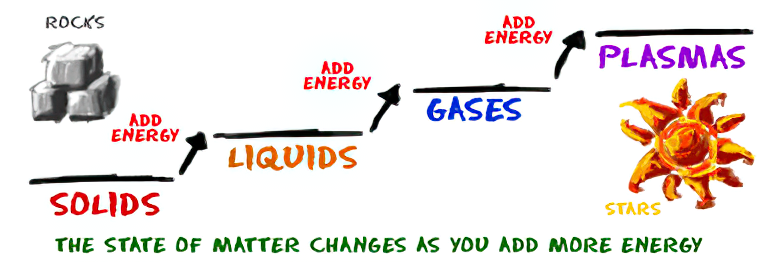
How are Energy and Matter the Same?
Read more: How are Energy and Matter the Same?www.turnerpublishing.com/blog/detail/everything-is-energy-everything-is-one-everything-is-possible/
www.universetoday.com/116615/how-are-energy-and-matter-the-same/
As Einstein showed us, light and matter and just aspects of the same thing. Matter is just frozen light. And light is matter on the move. Albert Einstein’s most famous equation says that energy and matter are two sides of the same coin. How does one become the other?
Relativity requires that the faster an object moves, the more mass it appears to have. This means that somehow part of the energy of the car’s motion appears to transform into mass. Hence the origin of Einstein’s equation. How does that happen? We don’t really know. We only know that it does.
Matter is 99.999999999999 percent empty space. Not only do the atom and solid matter consist mainly of empty space, it is the same in outer space
The quantum theory researchers discovered the answer: Not only do particles consist of energy, but so does the space between. This is the so-called zero-point energy. Therefore it is true: Everything consists of energy.
Energy is the basis of material reality. Every type of particle is conceived of as a quantum vibration in a field: Electrons are vibrations in electron fields, protons vibrate in a proton field, and so on. Everything is energy, and everything is connected to everything else through fields.
-
HDRI Resources
Read more: HDRI ResourcesText2Light
- https://www.cgtrader.com/free-3d-models/exterior/other/10-free-hdr-panoramas-created-with-text2light-zero-shot
- https://frozenburning.github.io/projects/text2light/
- https://github.com/FrozenBurning/Text2Light
Royalty free links
- https://locationtextures.com/panoramas/
- http://www.noahwitchell.com/freebies
- https://polyhaven.com/hdris
- https://hdrmaps.com/
- https://www.ihdri.com/
- https://hdrihaven.com/
- https://www.domeble.com/
- http://www.hdrlabs.com/sibl/archive.html
- https://www.hdri-hub.com/hdrishop/hdri
- http://noemotionhdrs.net/hdrevening.html
- https://www.openfootage.net/hdri-panorama/
- https://www.zwischendrin.com/en/browse/hdri
Nvidia GauGAN360
-
Cinematographers Blueprint 300dpi poster
Read more: Cinematographers Blueprint 300dpi posterThe 300dpi digital poster is now available to all PixelSham.com subscribers.

If you have already subscribed and wish a copy, please send me a note through the contact page.
















COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
What Is The Resolution and view coverage Of The human Eye. And what distance is TV at best?
-
Want to build a start up company that lasts? Think three-layer cake
-
Types of AI Explained in a few Minutes – AI Glossary
-
4dv.ai – Remote Interactive 3D Holographic Presentation Technology and System running on the PlayCanvas engine
-
Black Body color aka the Planckian Locus curve for white point eye perception
-
Film Production walk-through – pipeline – I want to make a … movie
-
Convert 2D Images or Text to 3D Models
-
AI Search – Find The Best AI Tools & Apps
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
