


COMPOSITION
-
Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacy
Read more: Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacynofilmschool.com/types-of-film-lights
“Not every light performs the same way. Lights and lighting are tricky to handle. You have to plan for every circumstance. But the good news is, lighting can be adjusted. Let’s look at different factors that affect lighting in every scene you shoot. “
Use CRI, Luminous Efficacy and color temperature controls to match your needs.
Color Temperature
Color temperature describes the “color” of white light by a light source radiated by a perfect black body at a given temperature measured in degrees Kelvinhttps://www.pixelsham.com/2019/10/18/color-temperature/
CRI
“The Color Rendering Index is a measurement of how faithfully a light source reveals the colors of whatever it illuminates, it describes the ability of a light source to reveal the color of an object, as compared to the color a natural light source would provide. The highest possible CRI is 100. A CRI of 100 generally refers to a perfect black body, like a tungsten light source or the sun. “https://www.studiobinder.com/blog/what-is-color-rendering-index
(more…) -
Photography basics: Camera Aspect Ratio, Sensor Size and Depth of Field – resolutions
Read more: Photography basics: Camera Aspect Ratio, Sensor Size and Depth of Field – resolutionshttp://www.shutterangle.com/2012/cinematic-look-aspect-ratio-sensor-size-depth-of-field/
http://www.shutterangle.com/2012/film-video-aspect-ratio-artistic-choice/















DESIGN
-
boldtron – 𝗗𝗘𝗣𝗜𝗖𝗧𝗜𝗡𝗚 𝗪𝗔𝗧𝗘𝗥𝗚𝗨𝗡𝗦
Read more: boldtron – 𝗗𝗘𝗣𝗜𝗖𝗧𝗜𝗡𝗚 𝗪𝗔𝗧𝗘𝗥𝗚𝗨𝗡𝗦See this Instagram post by @boldtron using ComfyUI + Krea
https://www.instagram.com/p/C5v-H0PNYYg/?utm_source=ig_web_button_share_sheet











COLOR
-
What is OLED and what can it do for your TV
Read more: What is OLED and what can it do for your TVhttps://www.cnet.com/news/what-is-oled-and-what-can-it-do-for-your-tv/
OLED stands for Organic Light Emitting Diode. Each pixel in an OLED display is made of a material that glows when you jab it with electricity. Kind of like the heating elements in a toaster, but with less heat and better resolution. This effect is called electroluminescence, which is one of those delightful words that is big, but actually makes sense: “electro” for electricity, “lumin” for light and “escence” for, well, basically “essence.”
OLED TV marketing often claims “infinite” contrast ratios, and while that might sound like typical hyperbole, it’s one of the extremely rare instances where such claims are actually true. Since OLED can produce a perfect black, emitting no light whatsoever, its contrast ratio (expressed as the brightest white divided by the darkest black) is technically infinite.
OLED is the only technology capable of absolute blacks and extremely bright whites on a per-pixel basis. LCD definitely can’t do that, and even the vaunted, beloved, dearly departed plasma couldn’t do absolute blacks.

-
Virtual Production volumes study
Read more: Virtual Production volumes studyColor Fidelity in LED Volumes
https://theasc.com/articles/color-fidelity-in-led-volumes
Virtual Production Glossary
https://vpglossary.com/What is Virtual Production – In depth analysis
https://www.leadingledtech.com/what-is-a-led-virtual-production-studio-in-depth-technical-analysis/
A comparison of LED panels for use in Virtual Production:
Findings and recommendations
https://eprints.bournemouth.ac.uk/36826/1/LED_Comparison_White_Paper%281%29.pdf -
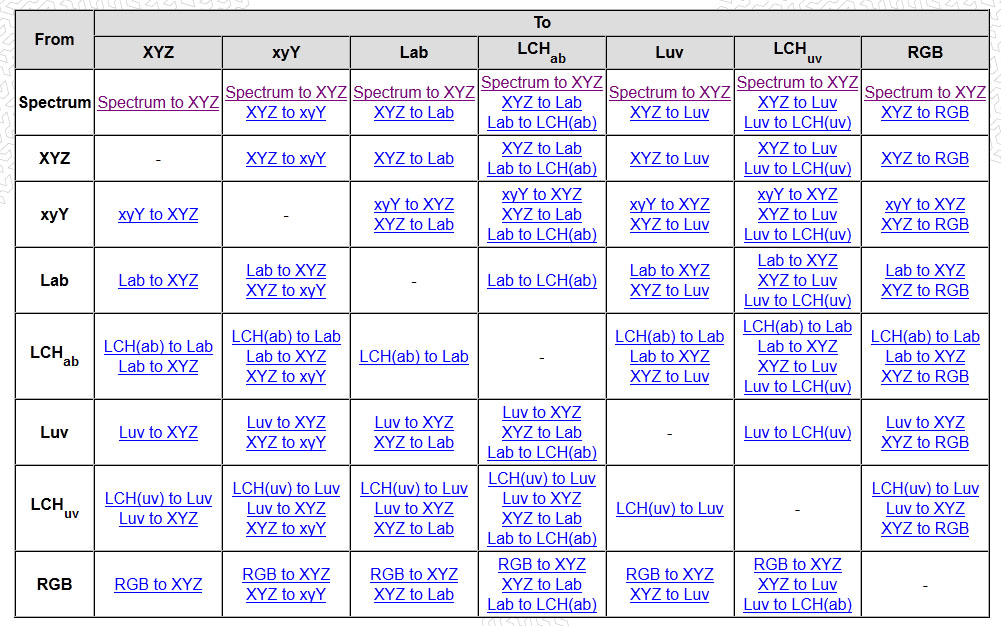
mmColorTarget – Nuke Gizmo for color matching a MacBeth chart
Read more: mmColorTarget – Nuke Gizmo for color matching a MacBeth charthttps://www.marcomeyer-vfx.de/posts/2014-04-11-mmcolortarget-nuke-gizmo/
https://www.marcomeyer-vfx.de/posts/mmcolortarget-nuke-gizmo/
https://vimeo.com/9.1652466e+07
https://www.nukepedia.com/gizmos/colour/mmcolortarget
-
What causes color
Read more: What causes colorwww.webexhibits.org/causesofcolor/5.html
Water itself has an intrinsic blue color that is a result of its molecular structure and its behavior.











LIGHTING
-
Capturing the world in HDR for real time projects – Call of Duty: Advanced Warfare
Read more: Capturing the world in HDR for real time projects – Call of Duty: Advanced WarfareReal-World Measurements for Call of Duty: Advanced Warfare
www.activision.com/cdn/research/Real_World_Measurements_for_Call_of_Duty_Advanced_Warfare.pdf
Local version
Real_World_Measurements_for_Call_of_Duty_Advanced_Warfare.pdf

-
Polarised vs unpolarized filtering
Read more: Polarised vs unpolarized filteringA light wave that is vibrating in more than one plane is referred to as unpolarized light. …
Polarized light waves are light waves in which the vibrations occur in a single plane. The process of transforming unpolarized light into polarized light is known as polarization.

en.wikipedia.org/wiki/Polarizing_filter_(photography)
The most common use of polarized technology is to reduce lighting complexity on the subject.
(more…)
Details such as glare and hard edges are not removed, but greatly reduced. -
Beeble Switchlight’s Plugin for Foundry Nuke
Read more: Beeble Switchlight’s Plugin for Foundry Nukehttps://www.cutout.pro/learn/beeble-switchlight/
https://www.switchlight-api.beeble.ai/pricing
https://www.switchlight-api.beeble.ai
https://github.com/beeble-ai/SwitchLight-Studio
https://beeble.ai/terms-of-use
https://www.switchlight-api.beeble.ai/docs





-
7 Easy Portrait Lighting Setups
Read more: 7 Easy Portrait Lighting Setups
Butterfly
Loop
Rembrandt
Split
Rim
Broad
Short
-
HDRI Resources
Read more: HDRI ResourcesText2Light
- https://www.cgtrader.com/free-3d-models/exterior/other/10-free-hdr-panoramas-created-with-text2light-zero-shot
- https://frozenburning.github.io/projects/text2light/
- https://github.com/FrozenBurning/Text2Light
Royalty free links
- https://locationtextures.com/panoramas/
- http://www.noahwitchell.com/freebies
- https://polyhaven.com/hdris
- https://hdrmaps.com/
- https://www.ihdri.com/
- https://hdrihaven.com/
- https://www.domeble.com/
- http://www.hdrlabs.com/sibl/archive.html
- https://www.hdri-hub.com/hdrishop/hdri
- http://noemotionhdrs.net/hdrevening.html
- https://www.openfootage.net/hdri-panorama/
- https://www.zwischendrin.com/en/browse/hdri
Nvidia GauGAN360












COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Advanced Computer Vision with Python OpenCV and Mediapipe
-
FFmpeg – examples and convenience lines
-
Eyeline Labs VChain – Chain-of-Visual-Thought for Reasoning in Video Generation for better AI physics
-
RawTherapee – a free, open source, cross-platform raw image and HDRi processing program
-
Kling 1.6 and competitors – advanced tests and comparisons
-
Survivorship Bias: The error resulting from systematically focusing on successes and ignoring failures. How a young statistician saved his planes during WW2.
-
PixelSham – Introduction to Python 2022
-
MiniMax-Remover – Taming Bad Noise Helps Video Object Removal Rotoscoping
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
