


COMPOSITION
-
Composition and The Expressive Nature Of Light
Read more: Composition and The Expressive Nature Of Lighthttp://www.huffingtonpost.com/bill-danskin/post_12457_b_10777222.html
George Sand once said “ The artist vocation is to send light into the human heart.”

-
SlowMoVideo – How to make a slow motion shot with the open source program
Read more: SlowMoVideo – How to make a slow motion shot with the open source programhttp://slowmovideo.granjow.net/
slowmoVideo is an OpenSource program that creates slow-motion videos from your footage.
Slow motion cinematography is the result of playing back frames for a longer duration than they were exposed. For example, if you expose 240 frames of film in one second, then play them back at 24 fps, the resulting movie is 10 times longer (slower) than the original filmed event….
Film cameras are relatively simple mechanical devices that allow you to crank up the speed to whatever rate the shutter and pull-down mechanism allow. Some film cameras can operate at 2,500 fps or higher (although film shot in these cameras often needs some readjustment in postproduction). Video, on the other hand, is always captured, recorded, and played back at a fixed rate, with a current limit around 60fps. This makes extreme slow motion effects harder to achieve (and less elegant) on video, because slowing down the video results in each frame held still on the screen for a long time, whereas with high-frame-rate film there are plenty of frames to fill the longer durations of time. On video, the slow motion effect is more like a slide show than smooth, continuous motion.
One obvious solution is to shoot film at high speed, then transfer it to video (a case where film still has a clear advantage, sorry George). Another possibility is to cross dissolve or blur from one frame to the next. This adds a smooth transition from one still frame to the next. The blur reduces the sharpness of the image, and compared to slowing down images shot at a high frame rate, this is somewhat of a cheat. However, there isn’t much you can do about it until video can be recorded at much higher rates. Of course, many film cameras can’t shoot at high frame rates either, so the whole super-slow-motion endeavor is somewhat specialized no matter what medium you are using. (There are some high speed digital cameras available now that allow you to capture lots of digital frames directly to your computer, so technology is starting to catch up with film. However, this feature isn’t going to appear in consumer camcorders any time soon.)













DESIGN
















COLOR
-
HDR and Color
Read more: HDR and Colorhttps://www.soundandvision.com/content/nits-and-bits-hdr-and-color
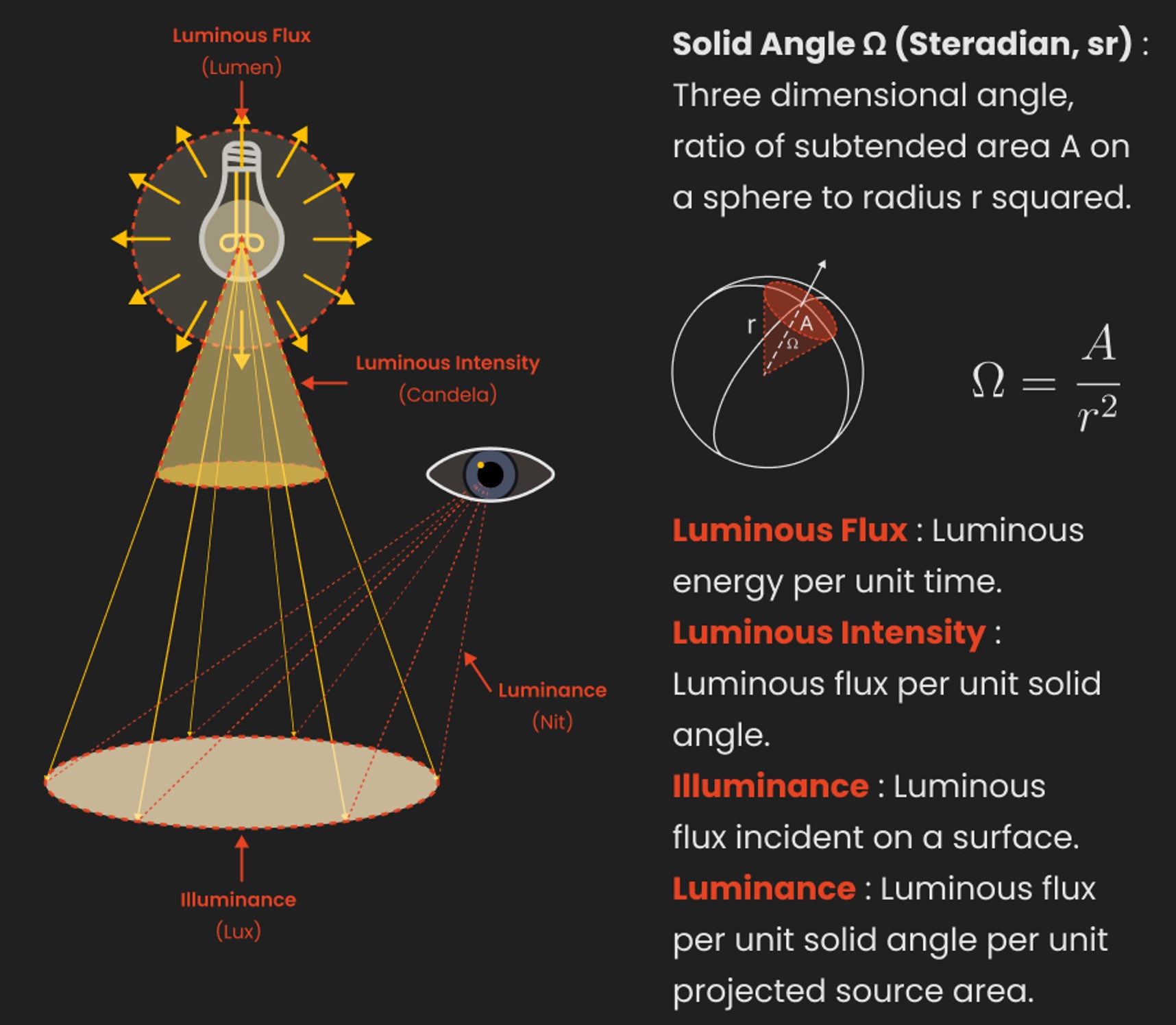
In HD we often refer to the range of available colors as a color gamut. Such a color gamut is typically plotted on a two-dimensional diagram, called a CIE chart, as shown in at the top of this blog. Each color is characterized by its x/y coordinates.

Good enough for government work, perhaps. But for HDR, with its higher luminance levels and wider color, the gamut becomes three-dimensional.

For HDR the color gamut therefore becomes a characteristic we now call the color volume. It isn’t easy to show color volume on a two-dimensional medium like the printed page or a computer screen, but one method is shown below. As the luminance becomes higher, the picture eventually turns to white. As it becomes darker, it fades to black. The traditional color gamut shown on the CIE chart is simply a slice through this color volume at a selected luminance level, such as 50%.
Three different color volumes—we still refer to them as color gamuts though their third dimension is important—are currently the most significant. The first is BT.709 (sometimes referred to as Rec.709), the color gamut used for pre-UHD/HDR formats, including standard HD.
The largest is known as BT.2020; it encompasses (roughly) the range of colors visible to the human eye (though ET might find it insufficient!).
Between these two is the color gamut used in digital cinema, known as DCI-P3.

sRGB

D65

-
mmColorTarget – Nuke Gizmo for color matching a MacBeth chart
Read more: mmColorTarget – Nuke Gizmo for color matching a MacBeth charthttps://www.marcomeyer-vfx.de/posts/2014-04-11-mmcolortarget-nuke-gizmo/
https://www.marcomeyer-vfx.de/posts/mmcolortarget-nuke-gizmo/
https://vimeo.com/9.1652466e+07
https://www.nukepedia.com/gizmos/colour/mmcolortarget
-
RawTherapee – a free, open source, cross-platform raw image and HDRi processing program
Read more: RawTherapee – a free, open source, cross-platform raw image and HDRi processing program5.10 of this tool includes excellent tools to clean up cr2 and cr3 used on set to support HDRI processing.
Converting raw to AcesCG 32 bit tiffs with metadata.


-
Brett Jones / Phil Reyneri (Lightform) / Philipp7pc: The study of Projection Mapping through Projectors
Read more: Brett Jones / Phil Reyneri (Lightform) / Philipp7pc: The study of Projection Mapping through Projectors


Video Projection Tool Software
https://hcgilje.wordpress.com/vpt/
https://www.projectorpoint.co.uk/news/how-bright-should-my-projector-be/
http://www.adwindowscreens.com/the_calculator/
heavym
https://heavym.net/en/
MadMapper
https://madmapper.com/
-
OpenColorIO standard
Read more: OpenColorIO standardhttps://www.provideocoalition.com/color-management-part-11-introducing-opencolorio/
OpenColorIO (OCIO) is a new open source project from Sony Imageworks.
Based on development started in 2003, OCIO enables color transforms and image display to be handled in a consistent manner across multiple graphics applications. Unlike other color management solutions, OCIO is geared towards motion-picture post production, with an emphasis on visual effects and animation color pipelines.










LIGHTING
-
Debayer – A free command line tool to convert camera raw images into scene-linear exr
Read more: Debayer – A free command line tool to convert camera raw images into scene-linear exr
https://github.com/jedypod/debayer
The only required dependency is oiiotool. However other “debayer engines” are also supported.
- OpenImageIO – oiiotool is used for converting debayered tif images to exr.
- Debayer Engines
- RawTherapee – Powerful raw development software used to decode raw images. High quality, good selection of debayer algorithms, and more advanced raw processing like chromatic aberration removal.
- LibRaw – dcraw_emu commandline utility included with LibRaw. Optional alternative for debayer. Simple, fast and effective.
- Darktable – Uses darktable-cli plus an xmp config to process.
- vkdt – uses vkdt-cli to debayer. Pretty experimental still. Uses Vulkan for image processing. Stupidly fast. Pretty limited.
-
studiobinder.com – What is Tenebrism and Hard Lighting — The Art of Light and Shadow and chiaroscuro Explained
Read more: studiobinder.com – What is Tenebrism and Hard Lighting — The Art of Light and Shadow and chiaroscuro Explainedhttps://www.studiobinder.com/blog/what-is-tenebrism-art-definition/
https://www.studiobinder.com/blog/what-is-hard-light-photography/


-
Rendering – BRDF – Bidirectional reflectance distribution function
Read more: Rendering – BRDF – Bidirectional reflectance distribution functionhttp://en.wikipedia.org/wiki/Bidirectional_reflectance_distribution_function
The bidirectional reflectance distribution function is a four-dimensional function that defines how light is reflected at an opaque surface
http://www.cs.ucla.edu/~zhu/tutorial/An_Introduction_to_BRDF-Based_Lighting.pdf
In general, when light interacts with matter, a complicated light-matter dynamic occurs. This interaction depends on the physical characteristics of the light as well as the physical composition and characteristics of the matter.
That is, some of the incident light is reflected, some of the light is transmitted, and another portion of the light is absorbed by the medium itself.
A BRDF describes how much light is reflected when light makes contact with a certain material. Similarly, a BTDF (Bi-directional Transmission Distribution Function) describes how much light is transmitted when light makes contact with a certain material
http://www.cs.princeton.edu/~smr/cs348c-97/surveypaper.html
It is difficult to establish exactly how far one should go in elaborating the surface model. A truly complete representation of the reflective behavior of a surface might take into account such phenomena as polarization, scattering, fluorescence, and phosphorescence, all of which might vary with position on the surface. Therefore, the variables in this complete function would be:
incoming and outgoing angle incoming and outgoing wavelength incoming and outgoing polarization (both linear and circular) incoming and outgoing position (which might differ due to subsurface scattering) time delay between the incoming and outgoing light ray







COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Convert 2D Images or Text to 3D Models
-
MiniMax-Remover – Taming Bad Noise Helps Video Object Removal Rotoscoping
-
3D Gaussian Splatting step by step beginner course
-
Most common ways to smooth 3D prints
-
Sensitivity of human eye
-
Want to build a start up company that lasts? Think three-layer cake
-
SourceTree vs Github Desktop – Which one to use
-
Tencent Hunyuan3D 2.1 goes Open Source and adds MV (Multi-view) and MV Mini
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
