


COMPOSITION
-
Mastering Camera Shots and Angles: A Guide for Filmmakers
Read more: Mastering Camera Shots and Angles: A Guide for Filmmakershttps://website.ltx.studio/blog/mastering-camera-shots-and-angles
1. Extreme Wide Shot

2. Wide Shot

3. Medium Shot

4. Close Up

5. Extreme Close Up

-
HuggingFace ai-comic-factory – a FREE AI Comic Book Creator
Read more: HuggingFace ai-comic-factory – a FREE AI Comic Book Creatorhttps://huggingface.co/spaces/jbilcke-hf/ai-comic-factory

this is the epic story of a group of talented digital artists trying to overcame daily technical challenges to achieve incredibly photorealistic projects of monsters and aliens
















DESIGN
-
Magic Carpet by artist Daniel Wurtzel
Read more: Magic Carpet by artist Daniel Wurtzelhttps://www.youtube.com/watch?v=1C_40B9m4tI http://www.danielwurtzel.com
-
Cosmic Motors book by Daniel Simon
Read more: Cosmic Motors book by Daniel Simonhttp://danielsimon.com/cosmic-motors-the-book/

Book Cover Cosmic Motors, Copyright by Cosmic Motors LLC / Daniel Simon www.danielsimon.com










COLOR
-
OLED vs QLED – What TV is better?
Read more: OLED vs QLED – What TV is better?
Supported by LG, Philips, Panasonic and Sony sell the OLED system TVs.
OLED stands for “organic light emitting diode.”
It is a fundamentally different technology from LCD, the major type of TV today.
OLED is “emissive,” meaning the pixels emit their own light.Samsung is branding its best TVs with a new acronym: “QLED”
QLED (according to Samsung) stands for “quantum dot LED TV.”
It is a variation of the common LED LCD, adding a quantum dot film to the LCD “sandwich.”
QLED, like LCD, is, in its current form, “transmissive” and relies on an LED backlight.OLED is the only technology capable of absolute blacks and extremely bright whites on a per-pixel basis. LCD definitely can’t do that, and even the vaunted, beloved, dearly departed plasma couldn’t do absolute blacks.
QLED, as an improvement over OLED, significantly improves the picture quality. QLED can produce an even wider range of colors than OLED, which says something about this new tech. QLED is also known to produce up to 40% higher luminance efficiency than OLED technology. Further, many tests conclude that QLED is far more efficient in terms of power consumption than its predecessor, OLED.
(more…) -
The Color of Infinite Temperature
Read more: The Color of Infinite TemperatureThis is the color of something infinitely hot.

Of course you’d instantly be fried by gamma rays of arbitrarily high frequency, but this would be its spectrum in the visible range.
johncarlosbaez.wordpress.com/2022/01/16/the-color-of-infinite-temperature/
This is also the color of a typical neutron star. They’re so hot they look the same.
It’s also the color of the early Universe!This was worked out by David Madore.

The color he got is sRGB(148,177,255).
www.htmlcsscolor.com/hex/94B1FFAnd according to the experts who sip latte all day and make up names for colors, this color is called ‘Perano’.
-
Practical Aspects of Spectral Data and LEDs in Digital Content Production and Virtual Production – SIGGRAPH 2022
Read more: Practical Aspects of Spectral Data and LEDs in Digital Content Production and Virtual Production – SIGGRAPH 2022
Comparison to the commercial side

https://www.ecolorled.com/blog/detail/what-is-rgb-rgbw-rgbic-strip-lights
RGBW (RGB + White) LED strip uses a 4-in-1 LED chip made up of red, green, blue, and white.
RGBWW (RGB + White + Warm White) LED strip uses either a 5-in-1 LED chip with red, green, blue, white, and warm white for color mixing. The only difference between RGBW and RGBWW is the intensity of the white color. The term RGBCCT consists of RGB and CCT. CCT (Correlated Color Temperature) means that the color temperature of the led strip light can be adjusted to change between warm white and white. Thus, RGBWW strip light is another name of RGBCCT strip.
RGBCW is the acronym for Red, Green, Blue, Cold, and Warm. These 5-in-1 chips are used in supper bright smart LED lighting products
-
What is a Gamut or Color Space and why do I need to know about CIE
Read more: What is a Gamut or Color Space and why do I need to know about CIE

http://www.xdcam-user.com/2014/05/what-is-a-gamut-or-color-space-and-why-do-i-need-to-know-about-it/
In video terms gamut is normally related to as the full range of colours and brightness that can be either captured or displayed.
(more…) -
Thomas Mansencal – Colour Science for Python
Read more: Thomas Mansencal – Colour Science for Pythonhttps://thomasmansencal.substack.com/p/colour-science-for-python
https://www.colour-science.org/
Colour is an open-source Python package providing a comprehensive number of algorithms and datasets for colour science. It is freely available under the BSD-3-Clause terms.












LIGHTING
-
Open Source Nvidia Omniverse
Read more: Open Source Nvidia Omniverseblogs.nvidia.com/blog/2019/03/18/omniverse-collaboration-platform/

developer.nvidia.com/nvidia-omniverse
An open, Interactive 3D Design Collaboration Platform for Multi-Tool Workflows to simplify studio workflows for real-time graphics.
It supports Pixar’s Universal Scene Description technology for exchanging information about modeling, shading, animation, lighting, visual effects and rendering across multiple applications.
It also supports NVIDIA’s Material Definition Language, which allows artists to exchange information about surface materials across multiple tools.
With Omniverse, artists can see live updates made by other artists working in different applications. They can also see changes reflected in multiple tools at the same time.
For example an artist using Maya with a portal to Omniverse can collaborate with another artist using UE4 and both will see live updates of each others’ changes in their application.
-
Romain Chauliac – LightIt a lighting script for Maya and Arnold
Read more: Romain Chauliac – LightIt a lighting script for Maya and ArnoldLightIt is a script for Maya and Arnold that will help you and improve your lighting workflow.
Thanks to preset studio lighting components (lights, backdrop…), high quality studio scenes and HDRI library manager.
https://www.artstation.com/artwork/393emJ
-
Magnific.ai Relight – change the entire lighting of a scene
Read more: Magnific.ai Relight – change the entire lighting of a scene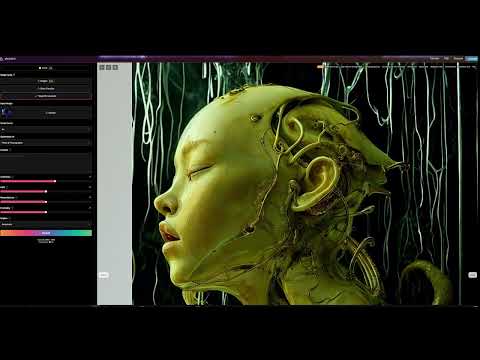
It’s a new Magnific spell that allows you to change the entire lighting of a scene and, optionally, the background with just:
1/ A prompt OR
2/ A reference image OR
3/ A light map (drawing your own lights)https://x.com/javilopen/status/1805274155065176489



-
Outpost VFX lighting tips
Read more: Outpost VFX lighting tipswww.outpost-vfx.com/en/news/18-pro-tips-and-tricks-for-lighting
Get as much information regarding your plate lighting as possible
- Always use a reference
- Replicate what is happening in real life
- Invest into a solid HDRI
- Start Simple
- Observe real world lighting, photography and cinematography
- Don’t neglect the theory
- Learn the difference between realism and photo-realism.
- Keep your scenes organised

-
What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…
Read more: What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…RASTERIZATION
Rasterisation (or rasterization) is the task of taking the information described in a vector graphics format OR the vertices of triangles making 3D shapes and converting them into a raster image (a series of pixels, dots or lines, which, when displayed together, create the image which was represented via shapes), or in other words “rasterizing” vectors or 3D models onto a 2D plane for display on a computer screen.For each triangle of a 3D shape, you project the corners of the triangle on the virtual screen with some math (projective geometry). Then you have the position of the 3 corners of the triangle on the pixel screen. Those 3 points have texture coordinates, so you know where in the texture are the 3 corners. The cost is proportional to the number of triangles, and is only a little bit affected by the screen resolution.
In computer graphics, a raster graphics or bitmap image is a dot matrix data structure that represents a generally rectangular grid of pixels (points of color), viewable via a monitor, paper, or other display medium.
With rasterization, objects on the screen are created from a mesh of virtual triangles, or polygons, that create 3D models of objects. A lot of information is associated with each vertex, including its position in space, as well as information about color, texture and its “normal,” which is used to determine the way the surface of an object is facing.
Computers then convert the triangles of the 3D models into pixels, or dots, on a 2D screen. Each pixel can be assigned an initial color value from the data stored in the triangle vertices.
Further pixel processing or “shading,” including changing pixel color based on how lights in the scene hit the pixel, and applying one or more textures to the pixel, combine to generate the final color applied to a pixel.
The main advantage of rasterization is its speed. However, rasterization is simply the process of computing the mapping from scene geometry to pixels and does not prescribe a particular way to compute the color of those pixels. So it cannot take shading, especially the physical light, into account and it cannot promise to get a photorealistic output. That’s a big limitation of rasterization.
There are also multiple problems:
If you have two triangles one is behind the other, you will draw twice all the pixels. you only keep the pixel from the triangle that is closer to you (Z-buffer), but you still do the work twice.
The borders of your triangles are jagged as it is hard to know if a pixel is in the triangle or out. You can do some smoothing on those, that is anti-aliasing.
You have to handle every triangles (including the ones behind you) and then see that they do not touch the screen at all. (we have techniques to mitigate this where we only look at triangles that are in the field of view)
Transparency is hard to handle (you can’t just do an average of the color of overlapping transparent triangles, you have to do it in the right order)











COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
3D Gaussian Splatting step by step beginner course
-
MiniTunes V1 – Free MP3 library app
-
Black Forest Labs released FLUX.1 Kontext
-
Emmanuel Tsekleves – Writing Research Papers
-
SourceTree vs Github Desktop – Which one to use
-
Python and TCL: Tips and Tricks for Foundry Nuke
-
N8N.io – From Zero to Your First AI Agent in 25 Minutes
-
Sensitivity of human eye
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
