


COMPOSITION
-
Composition – These are the basic lighting techniques you need to know for photography and film
Read more: Composition – These are the basic lighting techniques you need to know for photography and film
http://www.diyphotography.net/basic-lighting-techniques-need-know-photography-film/
Amongst the basic techniques, there’s…
1- Side lighting – Literally how it sounds, lighting a subject from the side when they’re faced toward you
2- Rembrandt lighting – Here the light is at around 45 degrees over from the front of the subject, raised and pointing down at 45 degrees
3- Back lighting – Again, how it sounds, lighting a subject from behind. This can help to add drama with silouettes
4- Rim lighting – This produces a light glowing outline around your subject
5- Key light – The main light source, and it’s not necessarily always the brightest light source
6- Fill light – This is used to fill in the shadows and provide detail that would otherwise be blackness
7- Cross lighting – Using two lights placed opposite from each other to light two subjects
















DESIGN
-
Cosmic Motors book by Daniel Simon
Read more: Cosmic Motors book by Daniel Simonhttp://danielsimon.com/cosmic-motors-the-book/

Book Cover Cosmic Motors, Copyright by Cosmic Motors LLC / Daniel Simon www.danielsimon.com















COLOR
-
About color: What is a LUT
Read more: About color: What is a LUThttp://www.lightillusion.com/luts.html
https://www.shutterstock.com/blog/how-use-luts-color-grading
A LUT (Lookup Table) is essentially the modifier between two images, the original image and the displayed image, based on a mathematical formula. Basically conversion matrices of different complexities. There are different types of LUTS – viewing, transform, calibration, 1D and 3D.


-
HDR and Color
Read more: HDR and Colorhttps://www.soundandvision.com/content/nits-and-bits-hdr-and-color
In HD we often refer to the range of available colors as a color gamut. Such a color gamut is typically plotted on a two-dimensional diagram, called a CIE chart, as shown in at the top of this blog. Each color is characterized by its x/y coordinates.

Good enough for government work, perhaps. But for HDR, with its higher luminance levels and wider color, the gamut becomes three-dimensional.

For HDR the color gamut therefore becomes a characteristic we now call the color volume. It isn’t easy to show color volume on a two-dimensional medium like the printed page or a computer screen, but one method is shown below. As the luminance becomes higher, the picture eventually turns to white. As it becomes darker, it fades to black. The traditional color gamut shown on the CIE chart is simply a slice through this color volume at a selected luminance level, such as 50%.
Three different color volumes—we still refer to them as color gamuts though their third dimension is important—are currently the most significant. The first is BT.709 (sometimes referred to as Rec.709), the color gamut used for pre-UHD/HDR formats, including standard HD.
The largest is known as BT.2020; it encompasses (roughly) the range of colors visible to the human eye (though ET might find it insufficient!).
Between these two is the color gamut used in digital cinema, known as DCI-P3.

sRGB

D65

-
VES Cinematic Color – Motion-Picture Color Management
Read more: VES Cinematic Color – Motion-Picture Color ManagementThis paper presents an introduction to the color pipelines behind modern feature-film visual-effects and animation.
Authored by Jeremy Selan, and reviewed by the members of the VES Technology Committee including Rob Bredow, Dan Candela, Nick Cannon, Paul Debevec, Ray Feeney, Andy Hendrickson, Gautham Krishnamurti, Sam Richards, Jordan Soles, and Sebastian Sylwan.











LIGHTING
-
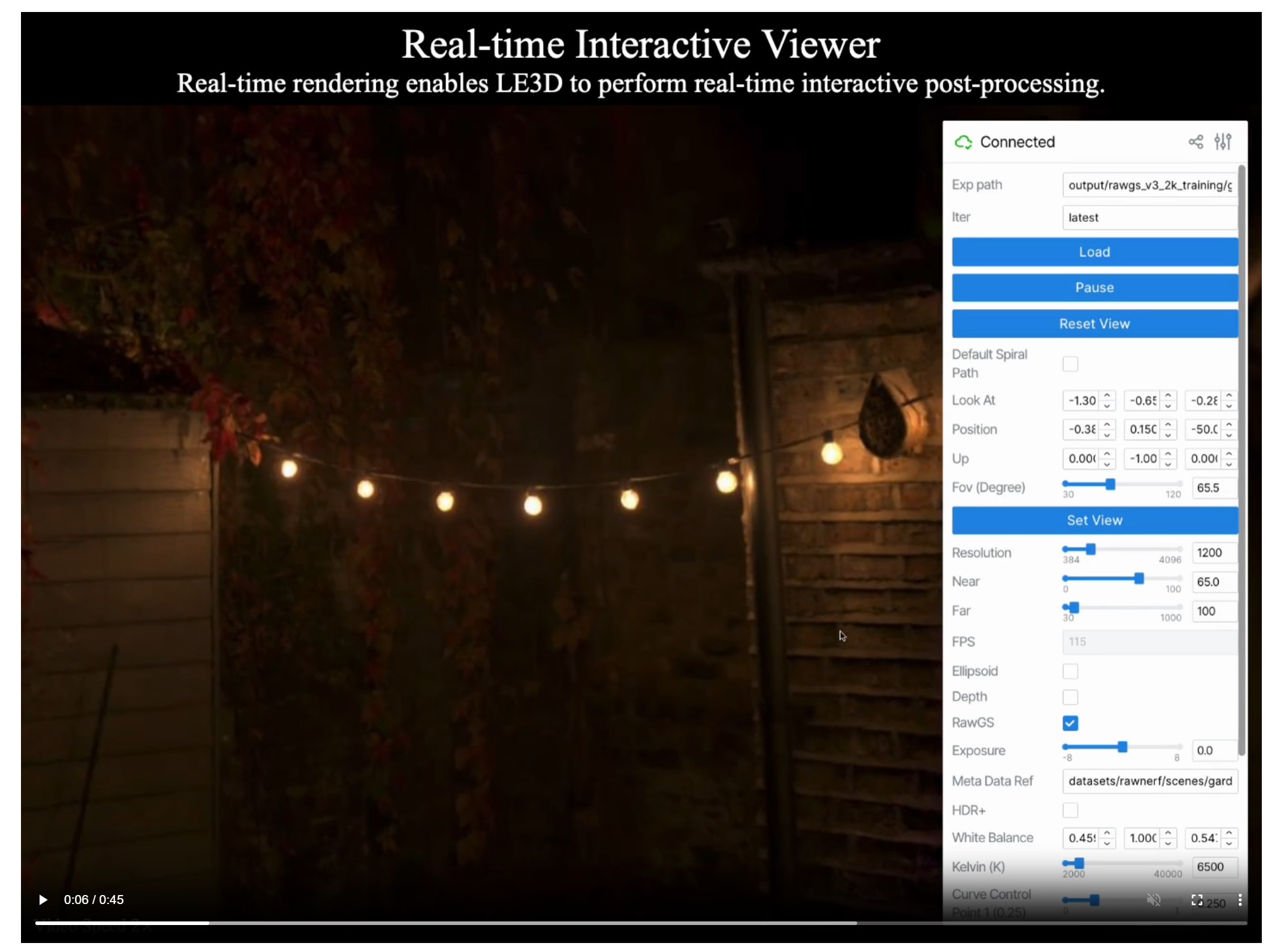
Lighting Every Darkness with 3DGS: Fast Training and Real-Time Rendering and Denoising for HDR View Synthesis
Read more: Lighting Every Darkness with 3DGS: Fast Training and Real-Time Rendering and Denoising for HDR View Synthesishttps://srameo.github.io/projects/le3d/
LE3D is a method for real-time HDR view synthesis from RAW images. It is particularly effective for nighttime scenes.
https://github.com/Srameo/LE3D

-
HDRI shooting and editing by Xuan Prada and Greg Zaal
Read more: HDRI shooting and editing by Xuan Prada and Greg Zaalwww.xuanprada.com/blog/2014/11/3/hdri-shooting
http://blog.gregzaal.com/2016/03/16/make-your-own-hdri/
http://blog.hdrihaven.com/how-to-create-high-quality-hdri/

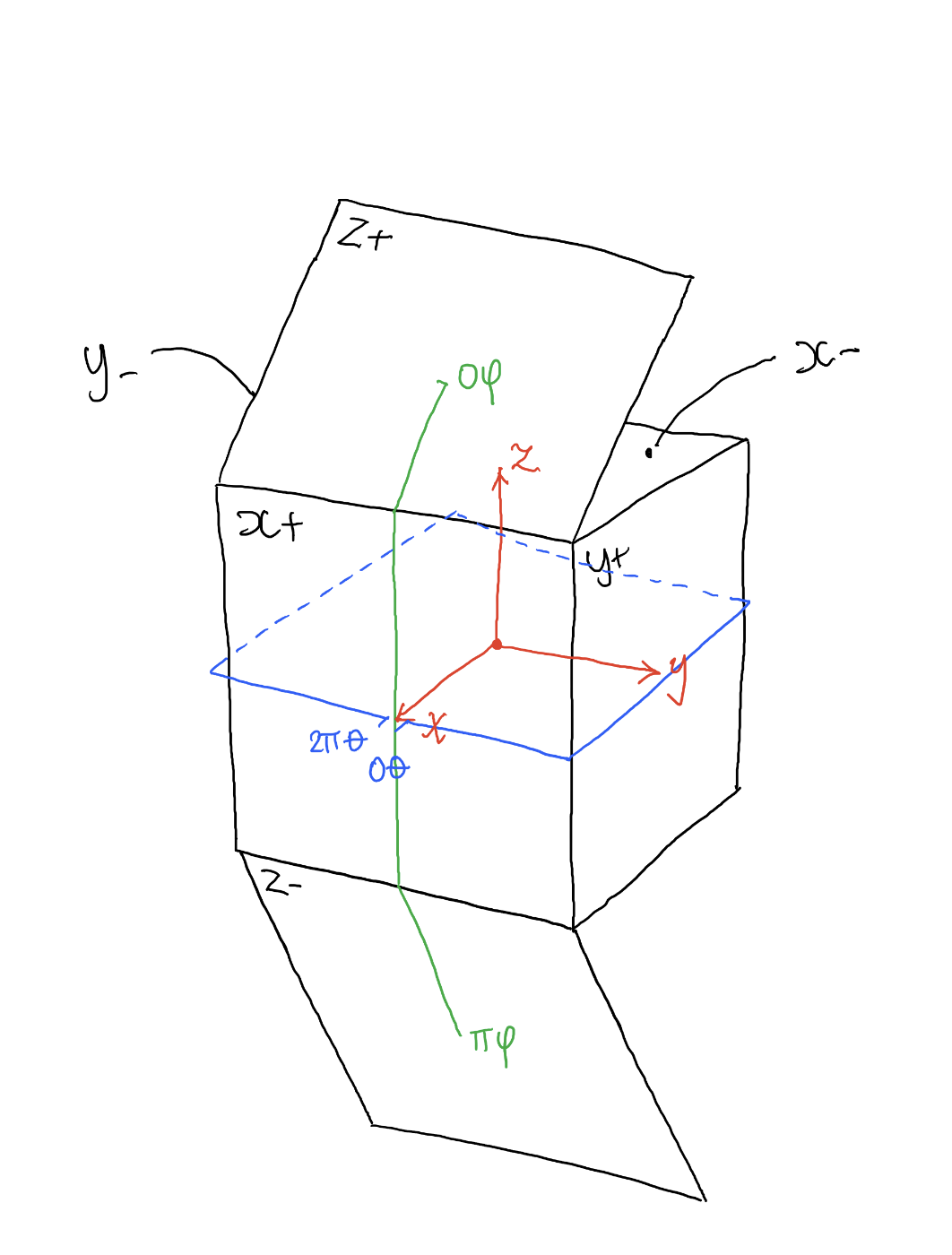
Shooting checklist
- Full coverage of the scene (fish-eye shots)
- Backplates for look-development (including ground or floor)
- Macbeth chart for white balance
- Grey ball for lighting calibration
- Chrome ball for lighting orientation
- Basic scene measurements
- Material samples
- Individual HDR artificial lighting sources if required
Methodology
(more…)












COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Embedding frame ranges into Quicktime movies with FFmpeg
-
Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminance
-
Sensitivity of human eye
-
White Balance is Broken!
-
Survivorship Bias: The error resulting from systematically focusing on successes and ignoring failures. How a young statistician saved his planes during WW2.
-
Photography basics: Solid Angle measures
-
Principles of Animation with Alan Becker, Dermot OConnor and Shaun Keenan
-
Methods for creating motion blur in Stop motion
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
