


COMPOSITION
-
SlowMoVideo – How to make a slow motion shot with the open source program
Read more: SlowMoVideo – How to make a slow motion shot with the open source programhttp://slowmovideo.granjow.net/
slowmoVideo is an OpenSource program that creates slow-motion videos from your footage.
Slow motion cinematography is the result of playing back frames for a longer duration than they were exposed. For example, if you expose 240 frames of film in one second, then play them back at 24 fps, the resulting movie is 10 times longer (slower) than the original filmed event….
Film cameras are relatively simple mechanical devices that allow you to crank up the speed to whatever rate the shutter and pull-down mechanism allow. Some film cameras can operate at 2,500 fps or higher (although film shot in these cameras often needs some readjustment in postproduction). Video, on the other hand, is always captured, recorded, and played back at a fixed rate, with a current limit around 60fps. This makes extreme slow motion effects harder to achieve (and less elegant) on video, because slowing down the video results in each frame held still on the screen for a long time, whereas with high-frame-rate film there are plenty of frames to fill the longer durations of time. On video, the slow motion effect is more like a slide show than smooth, continuous motion.
One obvious solution is to shoot film at high speed, then transfer it to video (a case where film still has a clear advantage, sorry George). Another possibility is to cross dissolve or blur from one frame to the next. This adds a smooth transition from one still frame to the next. The blur reduces the sharpness of the image, and compared to slowing down images shot at a high frame rate, this is somewhat of a cheat. However, there isn’t much you can do about it until video can be recorded at much higher rates. Of course, many film cameras can’t shoot at high frame rates either, so the whole super-slow-motion endeavor is somewhat specialized no matter what medium you are using. (There are some high speed digital cameras available now that allow you to capture lots of digital frames directly to your computer, so technology is starting to catch up with film. However, this feature isn’t going to appear in consumer camcorders any time soon.)
-
9 Best Hacks to Make a Cinematic Video with Any Camera
Read more: 9 Best Hacks to Make a Cinematic Video with Any Camerahttps://www.flexclip.com/learn/cinematic-video.html
- Frame Your Shots to Create Depth
- Create Shallow Depth of Field
- Avoid Shaky Footage and Use Flexible Camera Movements
- Properly Use Slow Motion
- Use Cinematic Lighting Techniques
- Apply Color Grading
- Use Cinematic Music and SFX
- Add Cinematic Fonts and Text Effects
- Create the Cinematic Bar at the Top and the Bottom














DESIGN
-
Mike Mitchell x Marvel x Mondo – Iconic portraits of Marvel’s huge stable of heroes and villains
Read more: Mike Mitchell x Marvel x Mondo – Iconic portraits of Marvel’s huge stable of heroes and villainshttps://mondoshop.com/blogs/gallery/16910155-mike-mitchell-x-marvel-x-mondo
https://time.com/69659/marvel-comics-mike-mitchell-artist-portraits/





















COLOR
-
Victor Perez – The Color Management Handbook for Visual Effects Artists
Read more: Victor Perez – The Color Management Handbook for Visual Effects ArtistsDigital Color Principles, Color Management Fundamentals & ACES Workflows

-
GretagMacbeth Color Checker Numeric Values and Middle Gray
Read more: GretagMacbeth Color Checker Numeric Values and Middle GrayThe human eye perceives half scene brightness not as the linear 50% of the present energy (linear nature values) but as 18% of the overall brightness. We are biased to perceive more information in the dark and contrast areas. A Macbeth chart helps with calibrating back into a photographic capture into this “human perspective” of the world.
https://en.wikipedia.org/wiki/Middle_gray
In photography, painting, and other visual arts, middle gray or middle grey is a tone that is perceptually about halfway between black and white on a lightness scale in photography and printing, it is typically defined as 18% reflectance in visible light

Light meters, cameras, and pictures are often calibrated using an 18% gray card[4][5][6] or a color reference card such as a ColorChecker. On the assumption that 18% is similar to the average reflectance of a scene, a grey card can be used to estimate the required exposure of the film.
https://en.wikipedia.org/wiki/ColorChecker
(more…) -
sRGB vs REC709 – An introduction and FFmpeg implementations
Read more: sRGB vs REC709 – An introduction and FFmpeg implementations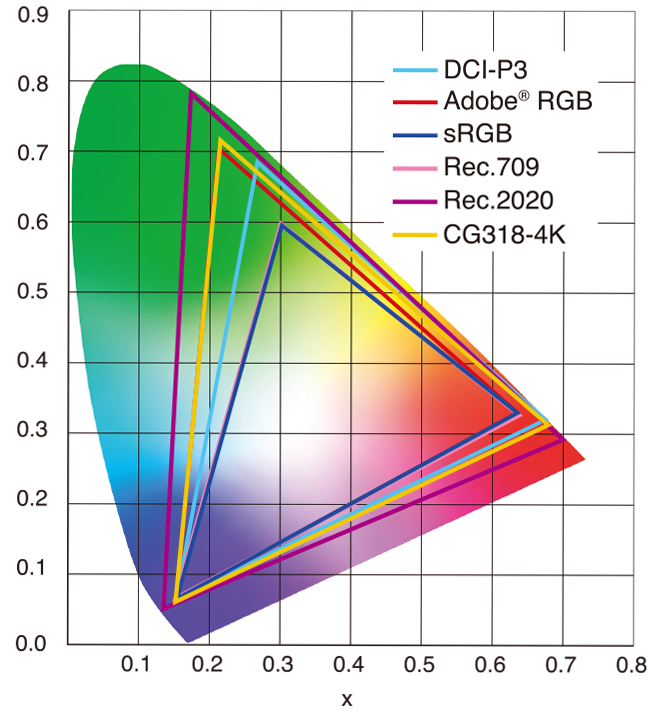
1. Basic Comparison
- What they are
- sRGB: A standard “web”/computer-display RGB color space defined by IEC 61966-2-1. It’s used for most monitors, cameras, printers, and the vast majority of images on the Internet.
- Rec. 709: An HD-video color space defined by ITU-R BT.709. It’s the go-to standard for HDTV broadcasts, Blu-ray discs, and professional video pipelines.
- Why they exist
- sRGB: Ensures consistent colors across different consumer devices (PCs, phones, webcams).
- Rec. 709: Ensures consistent colors across video production and playback chains (cameras → editing → broadcast → TV).
- What you’ll see
- On your desktop or phone, images tagged sRGB will look “right” without extra tweaking.
- On an HDTV or video-editing timeline, footage tagged Rec. 709 will display accurate contrast and hue on broadcast-grade monitors.
2. Digging Deeper
Feature sRGB Rec. 709 White point D65 (6504 K), same for both D65 (6504 K) Primaries (x,y) R: (0.640, 0.330) G: (0.300, 0.600) B: (0.150, 0.060) R: (0.640, 0.330) G: (0.300, 0.600) B: (0.150, 0.060) Gamut size Identical triangle on CIE 1931 chart Identical to sRGB Gamma / transfer Piecewise curve: approximate 2.2 with linear toe Pure power-law γ≈2.4 (often approximated as 2.2 in practice) Matrix coefficients N/A (pure RGB usage) Y = 0.2126 R + 0.7152 G + 0.0722 B (Rec. 709 matrix) Typical bit-depth 8-bit/channel (with 16-bit variants) 8-bit/channel (10-bit for professional video) Usage metadata Tagged as “sRGB” in image files (PNG, JPEG, etc.) Tagged as “bt709” in video containers (MP4, MOV) Color range Full-range RGB (0–255) Studio-range Y′CbCr (Y′ [16–235], Cb/Cr [16–240])
Why the Small Differences Matter
(more…) - What they are
-
Scene Referred vs Display Referred color workflows
Read more: Scene Referred vs Display Referred color workflowsDisplay Referred it is tied to the target hardware, as such it bakes color requirements into every type of media output request.
Scene Referred uses a common unified wide gamut and targeting audience through CDL and DI libraries instead.
So that color information stays untouched and only “transformed” as/when needed.



Sources:
– Victor Perez – Color Management Fundamentals & ACES Workflows in Nuke
– https://z-fx.nl/ColorspACES.pdf
– Wicus











LIGHTING
-
domeble – Hi-Resolution CGI Backplates and 360° HDRI
Read more: domeble – Hi-Resolution CGI Backplates and 360° HDRIWhen collecting hdri make sure the data supports basic metadata, such as:
- Iso
- Aperture
- Exposure time or shutter time
- Color temperature
- Color space Exposure value (what the sensor receives of the sun intensity in lux)
- 7+ brackets (with 5 or 6 being the perceived balanced exposure)
In image processing, computer graphics, and photography, high dynamic range imaging (HDRI or just HDR) is a set of techniques that allow a greater dynamic range of luminances (a Photometry measure of the luminous intensity per unit area of light travelling in a given direction. It describes the amount of light that passes through or is emitted from a particular area, and falls within a given solid angle) between the lightest and darkest areas of an image than standard digital imaging techniques or photographic methods. This wider dynamic range allows HDR images to represent more accurately the wide range of intensity levels found in real scenes ranging from direct sunlight to faint starlight and to the deepest shadows.
The two main sources of HDR imagery are computer renderings and merging of multiple photographs, which in turn are known as low dynamic range (LDR) or standard dynamic range (SDR) images. Tone Mapping (Look-up) techniques, which reduce overall contrast to facilitate display of HDR images on devices with lower dynamic range, can be applied to produce images with preserved or exaggerated local contrast for artistic effect. Photography
In photography, dynamic range is measured in Exposure Values (in photography, exposure value denotes all combinations of camera shutter speed and relative aperture that give the same exposure. The concept was developed in Germany in the 1950s) differences or stops, between the brightest and darkest parts of the image that show detail. An increase of one EV or one stop is a doubling of the amount of light.
The human response to brightness is well approximated by a Steven’s power law, which over a reasonable range is close to logarithmic, as described by the Weber�Fechner law, which is one reason that logarithmic measures of light intensity are often used as well.
HDR is short for High Dynamic Range. It’s a term used to describe an image which contains a greater exposure range than the “black” to “white” that 8 or 16-bit integer formats (JPEG, TIFF, PNG) can describe. Whereas these Low Dynamic Range images (LDR) can hold perhaps 8 to 10 f-stops of image information, HDR images can describe beyond 30 stops and stored in 32 bit images.

-
Neural Microfacet Fields for Inverse Rendering
Read more: Neural Microfacet Fields for Inverse Renderinghttps://half-potato.gitlab.io/posts/nmf/

-
Vahan Sosoyan MakeHDR – an OpenFX open source plug-in for merging multiple LDR images into a single HDRI
Read more: Vahan Sosoyan MakeHDR – an OpenFX open source plug-in for merging multiple LDR images into a single HDRIhttps://github.com/Sosoyan/make-hdr
Feature notes
- Merge up to 16 inputs with 8, 10 or 12 bit depth processing
- User friendly logarithmic Tone Mapping controls within the tool
- Advanced controls such as Sampling rate and Smoothness
Available at cross platform on Linux, MacOS and Windows Works consistent in compositing applications like Nuke, Fusion, Natron.
NOTE: The goal is to clean the initial individual brackets before or at merging time as much as possible.
This means:- keeping original shooting metadata
- de-fringing
- removing aberration (through camera lens data or automatically)
- at 32 bit
- in ACEScg (or ACES) wherever possible













COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
How to paint a boardgame miniatures
-
Web vs Printing or digital RGB vs CMYK
-
Gamma correction
-
FFmpeg – examples and convenience lines
-
Guide to Prompt Engineering
-
Steven Stahlberg – Perception and Composition
-
Black Body color aka the Planckian Locus curve for white point eye perception
-
Photography basics: Production Rendering Resolution Charts
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
