


COMPOSITION
-
Photography basics: Camera Aspect Ratio, Sensor Size and Depth of Field – resolutions
Read more: Photography basics: Camera Aspect Ratio, Sensor Size and Depth of Field – resolutionshttp://www.shutterangle.com/2012/cinematic-look-aspect-ratio-sensor-size-depth-of-field/
http://www.shutterangle.com/2012/film-video-aspect-ratio-artistic-choice/

























DESIGN
-
-
Mike Mitchell x Marvel x Mondo – Iconic portraits of Marvel’s huge stable of heroes and villains
Read more: Mike Mitchell x Marvel x Mondo – Iconic portraits of Marvel’s huge stable of heroes and villainshttps://mondoshop.com/blogs/gallery/16910155-mike-mitchell-x-marvel-x-mondo
https://time.com/69659/marvel-comics-mike-mitchell-artist-portraits/











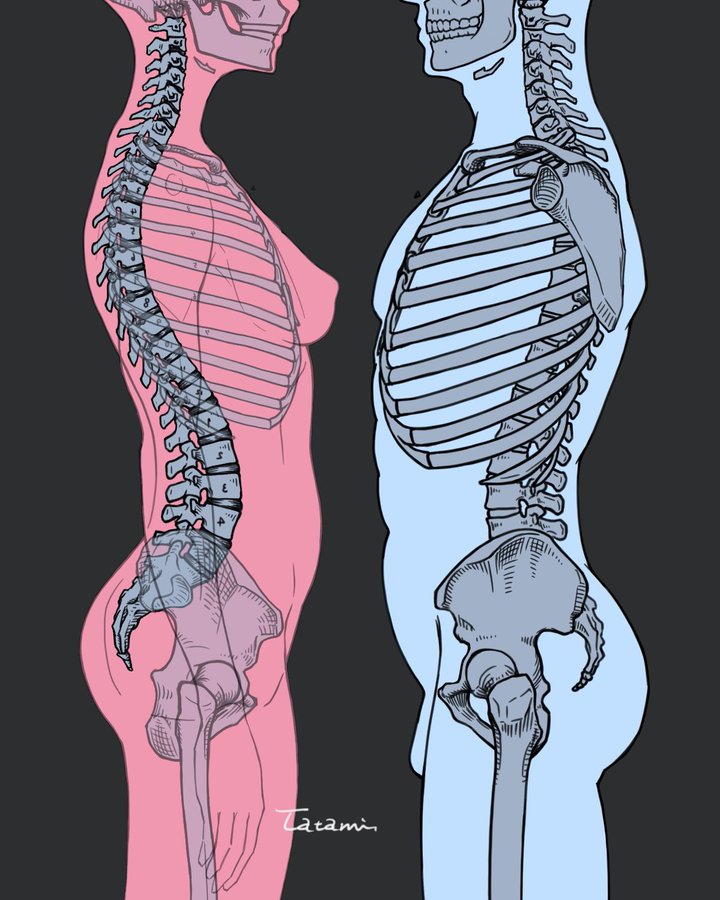

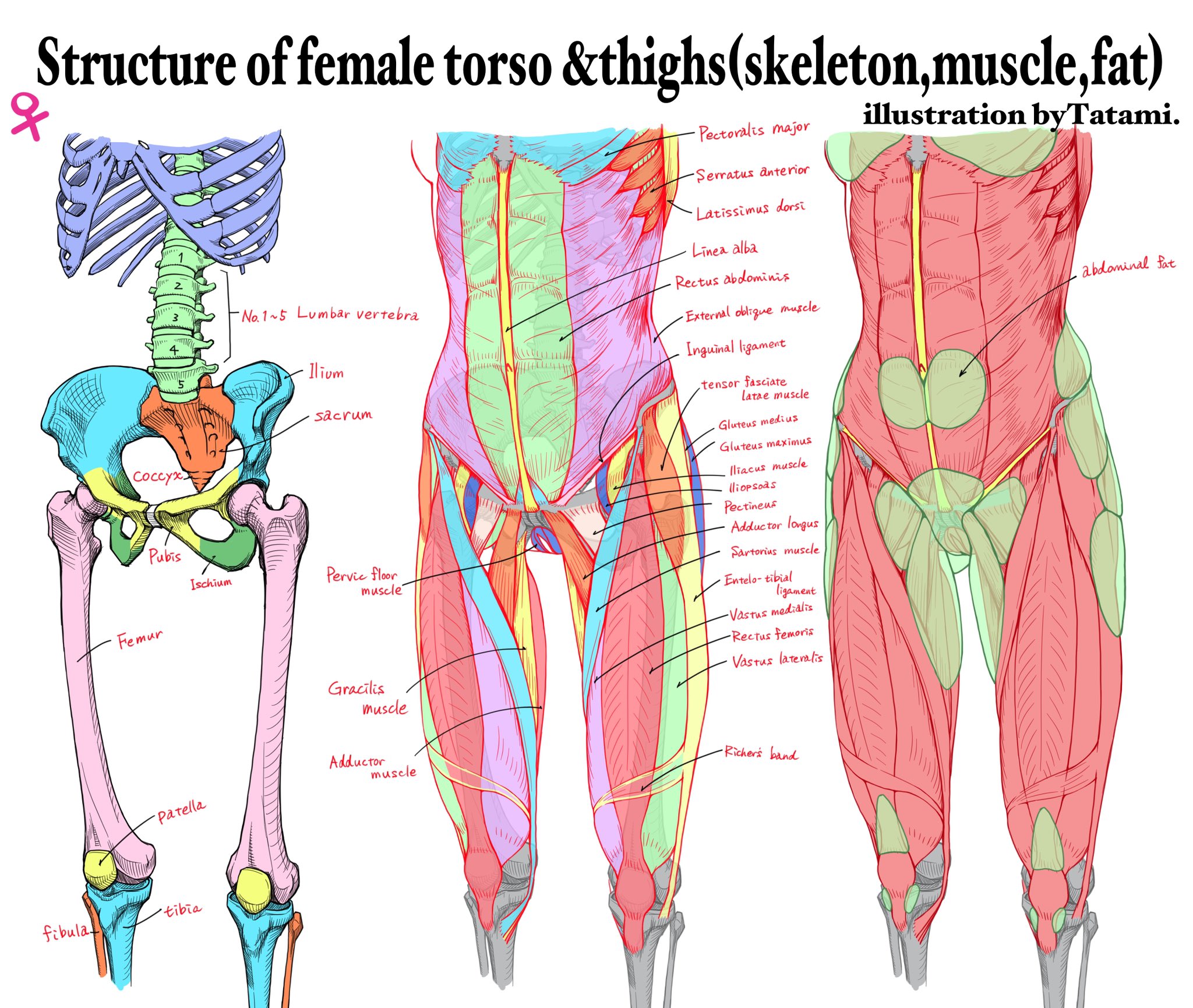
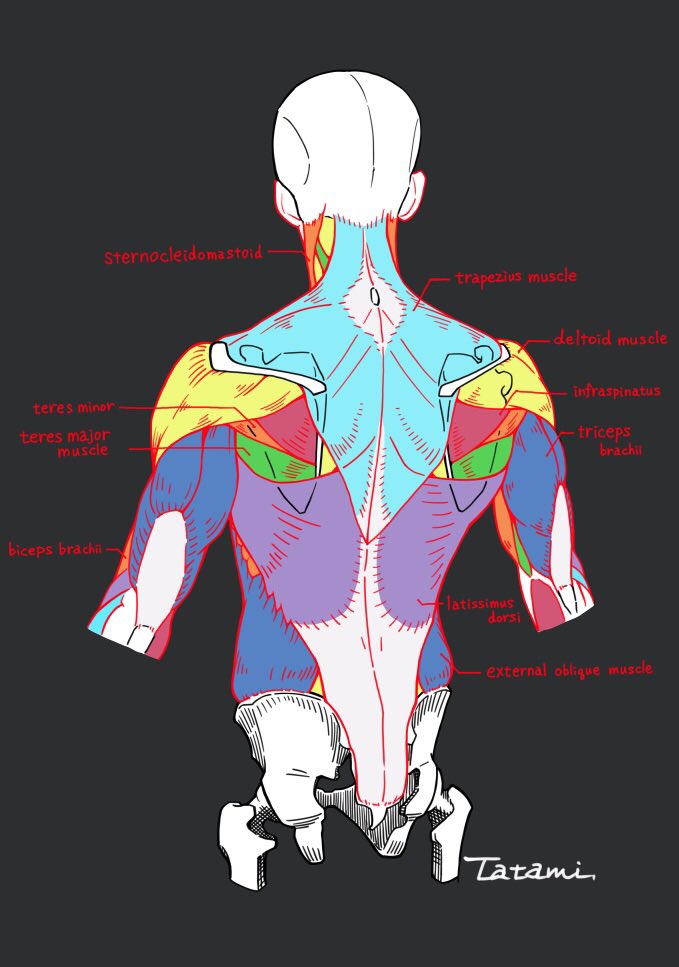
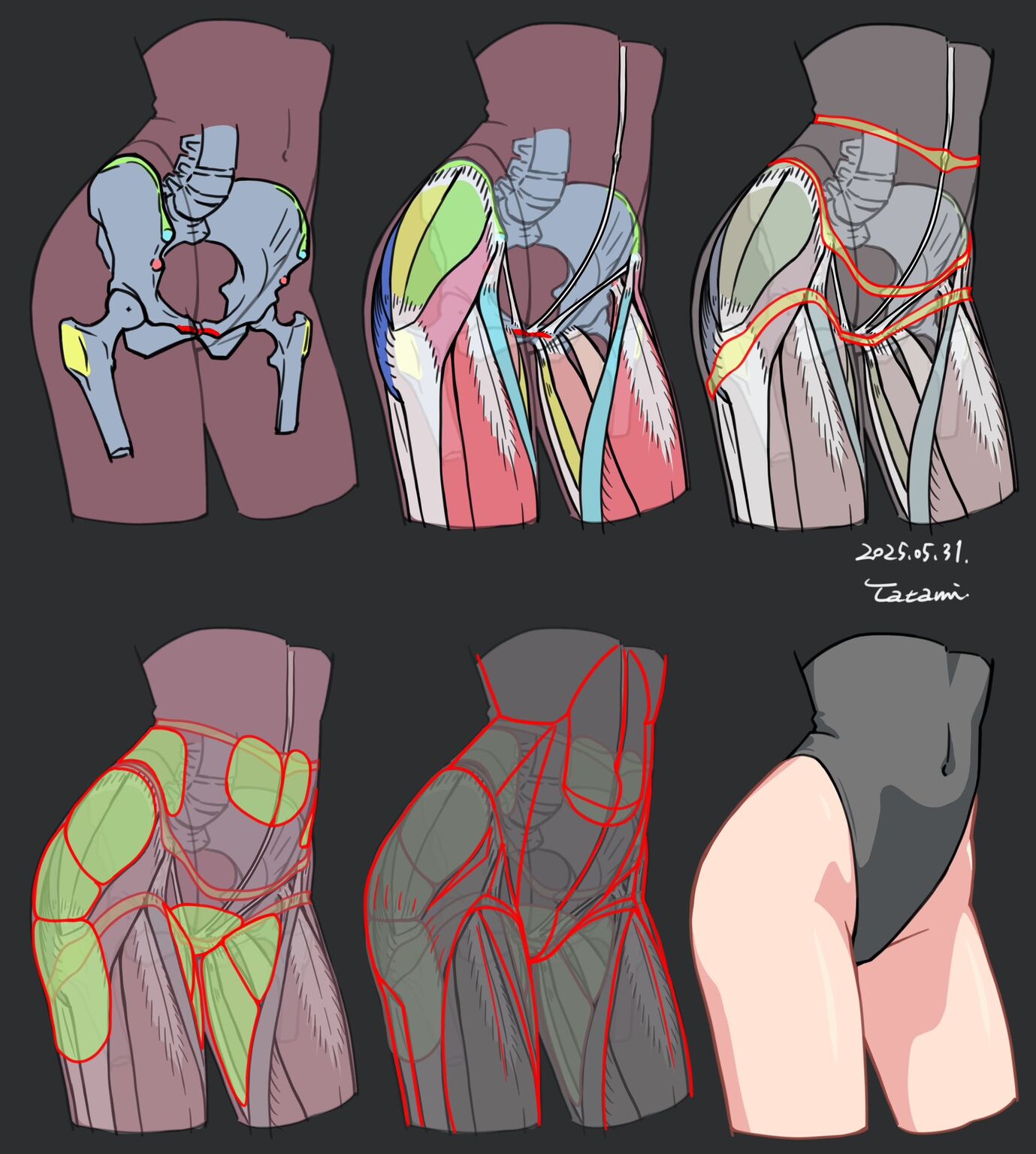


COLOR
-
Björn Ottosson – OKlch color space
Read more: Björn Ottosson – OKlch color spaceBjörn Ottosson proposed OKlch in 2020 to create a color space that can closely mimic how color is perceived by the human eye, predicting perceived lightness, chroma, and hue.
The OK in OKLCH stands for Optimal Color.
- L: Lightness (the perceived brightness of the color)
- C: Chroma (the intensity or saturation of the color)
- H: Hue (the actual color, such as red, blue, green, etc.)

Also read:














LIGHTING
-
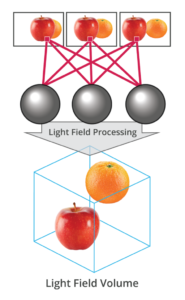
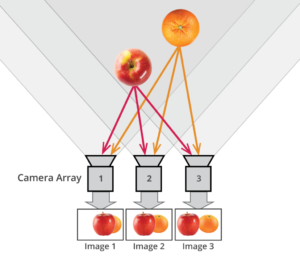
What is the Light Field?
Read more: What is the Light Field?http://lightfield-forum.com/what-is-the-lightfield/
The light field consists of the total of all light rays in 3D space, flowing through every point and in every direction.
How to Record a Light Field
- a single, robotically controlled camera
- a rotating arc of cameras
- an array of cameras or camera modules
- a single camera or camera lens fitted with a microlens array
-
Narcis Calin’s Galaxy Engine – A free, open source simulation software
Read more: Narcis Calin’s Galaxy Engine – A free, open source simulation softwareThis 2025 I decided to start learning how to code, so I installed Visual Studio and I started looking into C++. After days of watching tutorials and guides about the basics of C++ and programming, I decided to make something physics-related. I started with a dot that fell to the ground and then I wanted to simulate gravitational attraction, so I made 2 circles attracting each other. I thought it was really cool to see something I made with code actually work, so I kept building on top of that small, basic program. And here we are after roughly 8 months of learning programming. This is Galaxy Engine, and it is a simulation software I have been making ever since I started my learning journey. It currently can simulate gravity, dark matter, galaxies, the Big Bang, temperature, fluid dynamics, breakable solids, planetary interactions, etc. The program can run many tens of thousands of particles in real time on the CPU thanks to the Barnes-Hut algorithm, mixed with Morton curves. It also includes its own PBR 2D path tracer with BVH optimizations. The path tracer can simulate a bunch of stuff like diffuse lighting, specular reflections, refraction, internal reflection, fresnel, emission, dispersion, roughness, IOR, nested IOR and more! I tried to make the path tracer closer to traditional 3D render engines like V-Ray. I honestly never imagined I would go this far with programming, and it has been an amazing learning experience so far. I think that mixing this knowledge with my 3D knowledge can unlock countless new possibilities. In case you are curious about Galaxy Engine, I made it completely free and Open-Source so that anyone can build and compile it locally! You can find the source code in GitHub
https://github.com/NarcisCalin/Galaxy-Engine
-
Composition – 5 tips for creating perfect cinematic lighting and making your work look stunning
Read more: Composition – 5 tips for creating perfect cinematic lighting and making your work look stunning
http://www.diyphotography.net/5-tips-creating-perfect-cinematic-lighting-making-work-look-stunning/
1. Learn the rules of lighting
2. Learn when to break the rules
3. Make your key light larger
4. Reverse keying
5. Always be backlighting

![[gamma correction test]](http://www.madore.org/~david/misc/color/gammatest.png "sRGB gamma correction test")












{kind=link}
COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
RawTherapee – a free, open source, cross-platform raw image and HDRi processing program
-
Godot Cheat Sheets
-
AI and the Law – studiobinder.com – What is Fair Use: Definition, Policies, Examples and More
-
Want to build a start up company that lasts? Think three-layer cake
-
Top 3D Printing Website Resources
-
WhatDreamsCost Spline-Path-Control – Create motion controls for ComfyUI
-
AI Data Laundering: How Academic and Nonprofit Researchers Shield Tech Companies from Accountability
-
QR code logos
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
