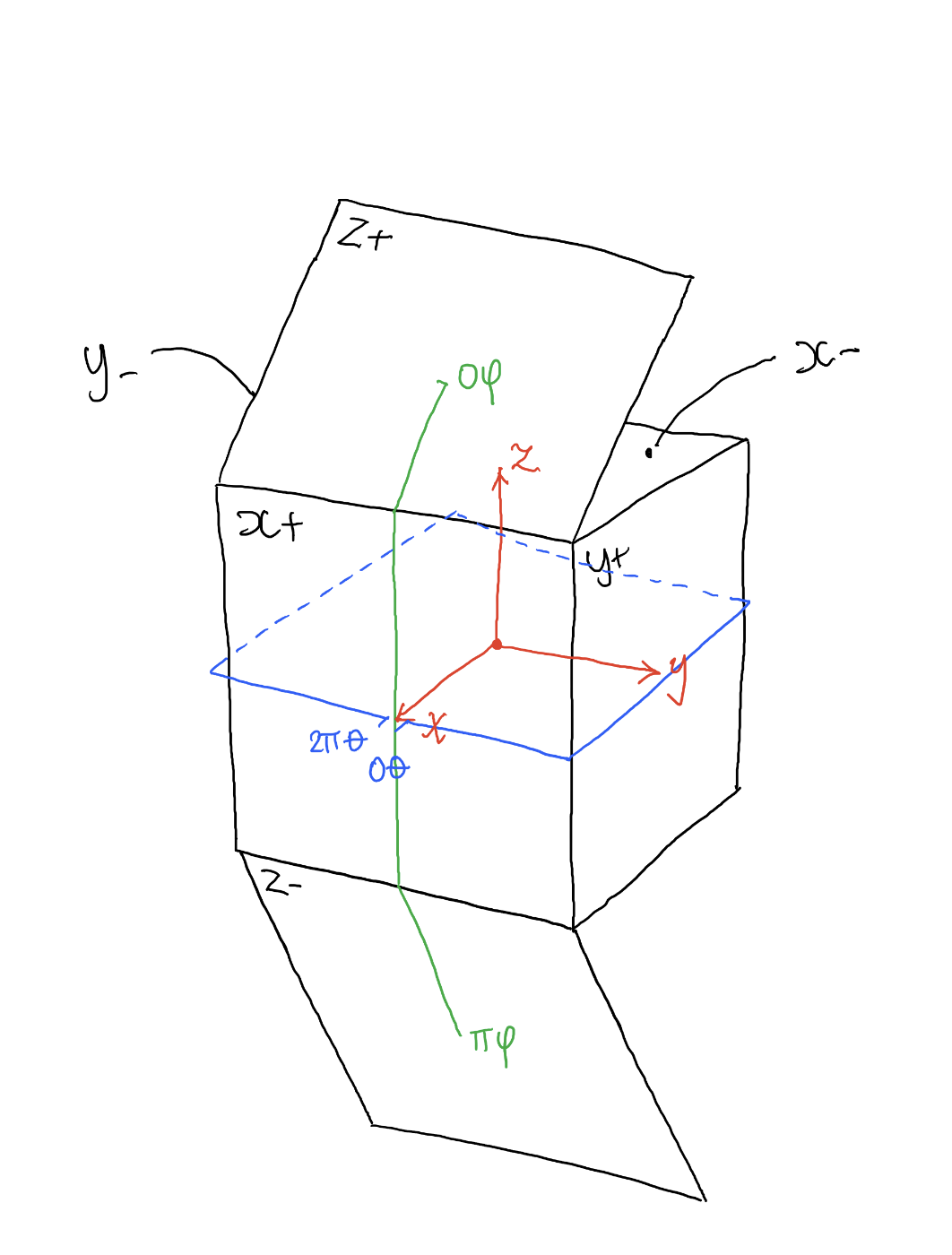
Depth of field is the range within which focusing is resolved in a photo.
Aperture has a huge affect on to the depth of field.
Changing the f-stops (f/#) of a lens will change aperture and as such the DOF.
f-stops are a just certain number which is telling you the size of the aperture. That’s how f-stop is related to aperture (and DOF).
If you increase f-stops, it will increase DOF, the area in focus (and decrease the aperture). On the other hand, decreasing the f-stop it will decrease DOF (and increase the aperture).
The red cone in the figure is an angular representation of the resolution of the system. Versus the dotted lines, which indicate the aperture coverage. Where the lines of the two cones intersect defines the total range of the depth of field.
This image explains why the longer the depth of field, the greater the range of clarity.
To measure the contrast ratio you will need a light meter. The process starts with you measuring the main source of light, or the key light.
Get a reading from the brightest area on the face of your subject. Then, measure the area lit by the secondary light, or fill light. To make sense of what you have just measured you have to understand that the information you have just gathered is in F-stops, a measure of light. With each additional F-stop, for example going one stop from f/1.4 to f/2.0, you create a doubling of light. The reverse is also true; moving one stop from f/8.0 to f/5.6 results in a halving of the light.
The intricate relationship between the eyes and the brain, often termed the eye-mind connection, reveals that vision is predominantly a cognitive process. This understanding has profound implications for fields such as design, where capturing and maintaining attention is paramount. This essay delves into the nuances of visual perception, the brain’s role in interpreting visual data, and how this knowledge can be applied to effective design strategies.
This cognitive aspect of vision is evident in phenomena such as optical illusions, where the brain interprets visual information in a way that contradicts physical reality. These illusions underscore that what we “see” is not merely a direct recording of the external world but a constructed experience shaped by cognitive processes.
Understanding the cognitive nature of vision is crucial for effective design. Designers must consider how the brain processes visual information to create compelling and engaging visuals. This involves several key principles:
slowmoVideo is an OpenSource program that creates slow-motion videos from your footage.
Slow motion cinematography is the result of playing back frames for a longer duration than they were exposed. For example, if you expose 240 frames of film in one second, then play them back at 24 fps, the resulting movie is 10 times longer (slower) than the original filmed event….
Film cameras are relatively simple mechanical devices that allow you to crank up the speed to whatever rate the shutter and pull-down mechanism allow. Some film cameras can operate at 2,500 fps or higher (although film shot in these cameras often needs some readjustment in postproduction). Video, on the other hand, is always captured, recorded, and played back at a fixed rate, with a current limit around 60fps. This makes extreme slow motion effects harder to achieve (and less elegant) on video, because slowing down the video results in each frame held still on the screen for a long time, whereas with high-frame-rate film there are plenty of frames to fill the longer durations of time. On video, the slow motion effect is more like a slide show than smooth, continuous motion.
One obvious solution is to shoot film at high speed, then transfer it to video (a case where film still has a clear advantage, sorry George). Another possibility is to cross dissolve or blur from one frame to the next. This adds a smooth transition from one still frame to the next. The blur reduces the sharpness of the image, and compared to slowing down images shot at a high frame rate, this is somewhat of a cheat. However, there isn’t much you can do about it until video can be recorded at much higher rates. Of course, many film cameras can’t shoot at high frame rates either, so the whole super-slow-motion endeavor is somewhat specialized no matter what medium you are using. (There are some high speed digital cameras available now that allow you to capture lots of digital frames directly to your computer, so technology is starting to catch up with film. However, this feature isn’t going to appear in consumer camcorders any time soon.)
ACES 2.0 is the second major release of the components that make up the ACES system. The most significant change is a new suite of rendering transforms whose design was informed by collected feedback and requests from users of ACES 1. The changes aim to improve the appearance of perceived artifacts and to complete previously unfinished components of the system, resulting in a more complete, robust, and consistent product.
Highlights of the key changes in ACES 2.0 are as follows:
New output transforms, including:
A less aggressive tone scale
More intuitive controls to create custom outputs to non-standard displays
Robust gamut mapping to improve perceptual uniformity
Improved performance of the inverse transforms
Enhanced AMF specification
An updated specification for ACES Transform IDs
OpenEXR compression recommendations
Enhanced tools for generating Input Transforms and recommended procedures for characterizing prosumer cameras
Look Transform Library
Expanded documentation
Rendering Transform
The most substantial change in ACES 2.0 is a complete redesign of the rendering transform.
ACES 2.0 was built as a unified system, rather than through piecemeal additions. Different deliverable outputs “match” better and making outputs to display setups other than the provided presets is intended to be user-driven. The rendering transforms are less likely to produce undesirable artifacts “out of the box”, which means less time can be spent fixing problematic images and more time making pictures look the way you want.
Key design goals
Improve consistency of tone scale and provide an easy to use parameter to allow for outputs between preset dynamic ranges
Minimize hue skews across exposure range in a region of same hue
Unify for structural consistency across transform type
Easy to use parameters to create outputs other than the presets
Robust gamut mapping to improve harsh clipping artifacts
Fill extents of output code value cube (where appropriate and expected)
Invertible – not necessarily reversible, but Output > ACES > Output round-trip should be possible
Accomplish all of the above while maintaining an acceptable “out-of-the box” rendering
A light wave that is vibrating in more than one plane is referred to as unpolarized light. …
Polarized light waves are light waves in which the vibrations occur in a single plane. The process of transforming unpolarized light into polarized light is known as polarization.
The most common use of polarized technology is to reduce lighting complexity on the subject. Details such as glare and hard edges are not removed, but greatly reduced.
Physically-based shading means leaving behind phenomenological models, like the Phong shading model, which are simply built to “look good” subjectively without being based on physics in any real way, and moving to lighting and shading models that are derived from the laws of physics and/or from actual measurements of the real world, and rigorously obey physical constraints such as energy conservation.
For example, in many older rendering systems, shading models included separate controls for specular highlights from point lights and reflection of the environment via a cubemap. You could create a shader with the specular and the reflection set to wildly different values, even though those are both instances of the same physical process. In addition, you could set the specular to any arbitrary brightness, even if it would cause the surface to reflect more energy than it actually received.
In a physically-based system, both the point light specular and the environment reflection would be controlled by the same parameter, and the system would be set up to automatically adjust the brightness of both the specular and diffuse components to maintain overall energy conservation. Moreover you would want to set the specular brightness to a realistic value for the material you’re trying to simulate, based on measurements.
Physically-based lighting or shading includes physically-based BRDFs, which are usually based on microfacet theory, and physically correct light transport, which is based on the rendering equation (although heavily approximated in the case of real-time games).
It also includes the necessary changes in the art process to make use of these features. Switching to a physically-based system can cause some upsets for artists. First of all it requires full HDR lighting with a realistic level of brightness for light sources, the sky, etc. and this can take some getting used to for the lighting artists. It also requires texture/material artists to do some things differently (particularly for specular), and they can be frustrated by the apparent loss of control (e.g. locking together the specular highlight and environment reflection as mentioned above; artists will complain about this). They will need some time and guidance to adapt to the physically-based system.
On the plus side, once artists have adapted and gained trust in the physically-based system, they usually end up liking it better, because there are fewer parameters overall (less work for them to tweak). Also, materials created in one lighting environment generally look fine in other lighting environments too. This is unlike more ad-hoc models, where a set of material parameters might look good during daytime, but it comes out ridiculously glowy at night, or something like that.
Here are some resources to look at for physically-based lighting in games:
SIGGRAPH 2013 Physically Based Shading Course, particularly the background talk by Naty Hoffman at the beginning. You can also check out the previous incarnations of this course for more resources.
And of course, I would be remiss if I didn’t mention Physically-Based Rendering by Pharr and Humphreys, an amazing reference on this whole subject and well worth your time, although it focuses on offline rather than real-time rendering.
The only required dependency is oiiotool. However other “debayer engines” are also supported.
OpenImageIO – oiiotool is used for converting debayered tif images to exr.
Debayer Engines
RawTherapee – Powerful raw development software used to decode raw images. High quality, good selection of debayer algorithms, and more advanced raw processing like chromatic aberration removal.
LibRaw – dcraw_emu commandline utility included with LibRaw. Optional alternative for debayer. Simple, fast and effective.
Darktable – Uses darktable-cli plus an xmp config to process.
vkdt – uses vkdt-cli to debayer. Pretty experimental still. Uses Vulkan for image processing. Stupidly fast. Pretty limited.
The human eye perceives half scene brightness not as the linear 50% of the present energy (linear nature values) but as 18% of the overall brightness. We are biased to perceive more information in the dark and contrast areas. A Macbeth chart helps with calibrating back into a photographic capture into this “human perspective” of the world.
In photography, painting, and other visual arts, middle gray or middle grey is a tone that is perceptually about halfway between black and white on a lightness scale in photography and printing, it is typically defined as 18% reflectance in visible light
Light meters, cameras, and pictures are often calibrated using an 18% gray card[4][5][6] or a color reference card such as a ColorChecker. On the assumption that 18% is similar to the average reflectance of a scene, a grey card can be used to estimate the required exposure of the film.
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.















































![[gamma correction test]](http://www.madore.org/~david/misc/color/gammatest.png "sRGB gamma correction test")