


COMPOSITION
-
Photography basics: Depth of Field and composition
Read more: Photography basics: Depth of Field and compositionDepth of field is the range within which focusing is resolved in a photo.
Aperture has a huge affect on to the depth of field.
Changing the f-stops (f/#) of a lens will change aperture and as such the DOF.
f-stops are a just certain number which is telling you the size of the aperture. That’s how f-stop is related to aperture (and DOF).
If you increase f-stops, it will increase DOF, the area in focus (and decrease the aperture). On the other hand, decreasing the f-stop it will decrease DOF (and increase the aperture).
The red cone in the figure is an angular representation of the resolution of the system. Versus the dotted lines, which indicate the aperture coverage. Where the lines of the two cones intersect defines the total range of the depth of field.
This image explains why the longer the depth of field, the greater the range of clarity.

-
Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental process
Read more: Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental processhttps://www.chrbutler.com/understanding-the-eye-mind-connection
The intricate relationship between the eyes and the brain, often termed the eye-mind connection, reveals that vision is predominantly a cognitive process. This understanding has profound implications for fields such as design, where capturing and maintaining attention is paramount. This essay delves into the nuances of visual perception, the brain’s role in interpreting visual data, and how this knowledge can be applied to effective design strategies.
This cognitive aspect of vision is evident in phenomena such as optical illusions, where the brain interprets visual information in a way that contradicts physical reality. These illusions underscore that what we “see” is not merely a direct recording of the external world but a constructed experience shaped by cognitive processes.
Understanding the cognitive nature of vision is crucial for effective design. Designers must consider how the brain processes visual information to create compelling and engaging visuals. This involves several key principles:
- Attention and Engagement
- Visual Hierarchy
- Cognitive Load Management
- Context and Meaning














DESIGN












COLOR
-
HDR and Color
Read more: HDR and Colorhttps://www.soundandvision.com/content/nits-and-bits-hdr-and-color
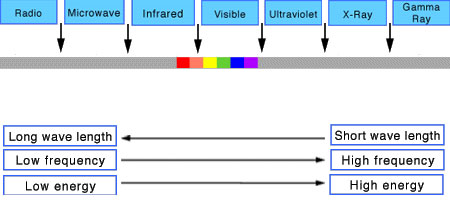
In HD we often refer to the range of available colors as a color gamut. Such a color gamut is typically plotted on a two-dimensional diagram, called a CIE chart, as shown in at the top of this blog. Each color is characterized by its x/y coordinates.

Good enough for government work, perhaps. But for HDR, with its higher luminance levels and wider color, the gamut becomes three-dimensional.

For HDR the color gamut therefore becomes a characteristic we now call the color volume. It isn’t easy to show color volume on a two-dimensional medium like the printed page or a computer screen, but one method is shown below. As the luminance becomes higher, the picture eventually turns to white. As it becomes darker, it fades to black. The traditional color gamut shown on the CIE chart is simply a slice through this color volume at a selected luminance level, such as 50%.
Three different color volumes—we still refer to them as color gamuts though their third dimension is important—are currently the most significant. The first is BT.709 (sometimes referred to as Rec.709), the color gamut used for pre-UHD/HDR formats, including standard HD.
The largest is known as BT.2020; it encompasses (roughly) the range of colors visible to the human eye (though ET might find it insufficient!).
Between these two is the color gamut used in digital cinema, known as DCI-P3.

sRGB

D65

-
PTGui 13 beta adds control through a Patch Editor
Read more: PTGui 13 beta adds control through a Patch EditorAdditions:
- Patch Editor (PTGui Pro)
- DNG output
- Improved RAW / DNG handling
- JPEG 2000 support
- Performance improvements

-
What is a Gamut or Color Space and why do I need to know about CIE
Read more: What is a Gamut or Color Space and why do I need to know about CIE

http://www.xdcam-user.com/2014/05/what-is-a-gamut-or-color-space-and-why-do-i-need-to-know-about-it/
In video terms gamut is normally related to as the full range of colours and brightness that can be either captured or displayed.
(more…)














LIGHTING
-
Vahan Sosoyan MakeHDR – an OpenFX open source plug-in for merging multiple LDR images into a single HDRI
Read more: Vahan Sosoyan MakeHDR – an OpenFX open source plug-in for merging multiple LDR images into a single HDRIhttps://github.com/Sosoyan/make-hdr
Feature notes
- Merge up to 16 inputs with 8, 10 or 12 bit depth processing
- User friendly logarithmic Tone Mapping controls within the tool
- Advanced controls such as Sampling rate and Smoothness
Available at cross platform on Linux, MacOS and Windows Works consistent in compositing applications like Nuke, Fusion, Natron.
NOTE: The goal is to clean the initial individual brackets before or at merging time as much as possible.
This means:- keeping original shooting metadata
- de-fringing
- removing aberration (through camera lens data or automatically)
- at 32 bit
- in ACEScg (or ACES) wherever possible

-
Unity 3D resources
Read more: Unity 3D resources
http://answers.unity3d.com/questions/12321/how-can-i-start-learning-unity-fast-list-of-tutori.html
If you have no previous experience with Unity, start with these six video tutorials which give a quick overview of the Unity interface and some important features http://unity3d.com/support/documentation/video/
-
What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…
Read more: What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…RASTERIZATION
Rasterisation (or rasterization) is the task of taking the information described in a vector graphics format OR the vertices of triangles making 3D shapes and converting them into a raster image (a series of pixels, dots or lines, which, when displayed together, create the image which was represented via shapes), or in other words “rasterizing” vectors or 3D models onto a 2D plane for display on a computer screen.For each triangle of a 3D shape, you project the corners of the triangle on the virtual screen with some math (projective geometry). Then you have the position of the 3 corners of the triangle on the pixel screen. Those 3 points have texture coordinates, so you know where in the texture are the 3 corners. The cost is proportional to the number of triangles, and is only a little bit affected by the screen resolution.
In computer graphics, a raster graphics or bitmap image is a dot matrix data structure that represents a generally rectangular grid of pixels (points of color), viewable via a monitor, paper, or other display medium.
With rasterization, objects on the screen are created from a mesh of virtual triangles, or polygons, that create 3D models of objects. A lot of information is associated with each vertex, including its position in space, as well as information about color, texture and its “normal,” which is used to determine the way the surface of an object is facing.
Computers then convert the triangles of the 3D models into pixels, or dots, on a 2D screen. Each pixel can be assigned an initial color value from the data stored in the triangle vertices.
Further pixel processing or “shading,” including changing pixel color based on how lights in the scene hit the pixel, and applying one or more textures to the pixel, combine to generate the final color applied to a pixel.
The main advantage of rasterization is its speed. However, rasterization is simply the process of computing the mapping from scene geometry to pixels and does not prescribe a particular way to compute the color of those pixels. So it cannot take shading, especially the physical light, into account and it cannot promise to get a photorealistic output. That’s a big limitation of rasterization.
There are also multiple problems:
If you have two triangles one is behind the other, you will draw twice all the pixels. you only keep the pixel from the triangle that is closer to you (Z-buffer), but you still do the work twice.
The borders of your triangles are jagged as it is hard to know if a pixel is in the triangle or out. You can do some smoothing on those, that is anti-aliasing.
You have to handle every triangles (including the ones behind you) and then see that they do not touch the screen at all. (we have techniques to mitigate this where we only look at triangles that are in the field of view)
Transparency is hard to handle (you can’t just do an average of the color of overlapping transparent triangles, you have to do it in the right order)
-
Cinematographers Blueprint 300dpi poster
Read more: Cinematographers Blueprint 300dpi posterThe 300dpi digital poster is now available to all PixelSham.com subscribers.

If you have already subscribed and wish a copy, please send me a note through the contact page.








COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
What the Boeing 737 MAX’s crashes can teach us about production business – the effects of commoditisation
-
Kling 1.6 and competitors – advanced tests and comparisons
-
Black Body color aka the Planckian Locus curve for white point eye perception
-
The Perils of Technical Debt – Understanding Its Impact on Security, Usability, and Stability
-
59 AI Filmmaking Tools For Your Workflow
-
Ross Pettit on The Agile Manager – How tech firms went for prioritizing cash flow instead of talent (and artists)
-
Free fonts
-
Photography basics: Solid Angle measures
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
