


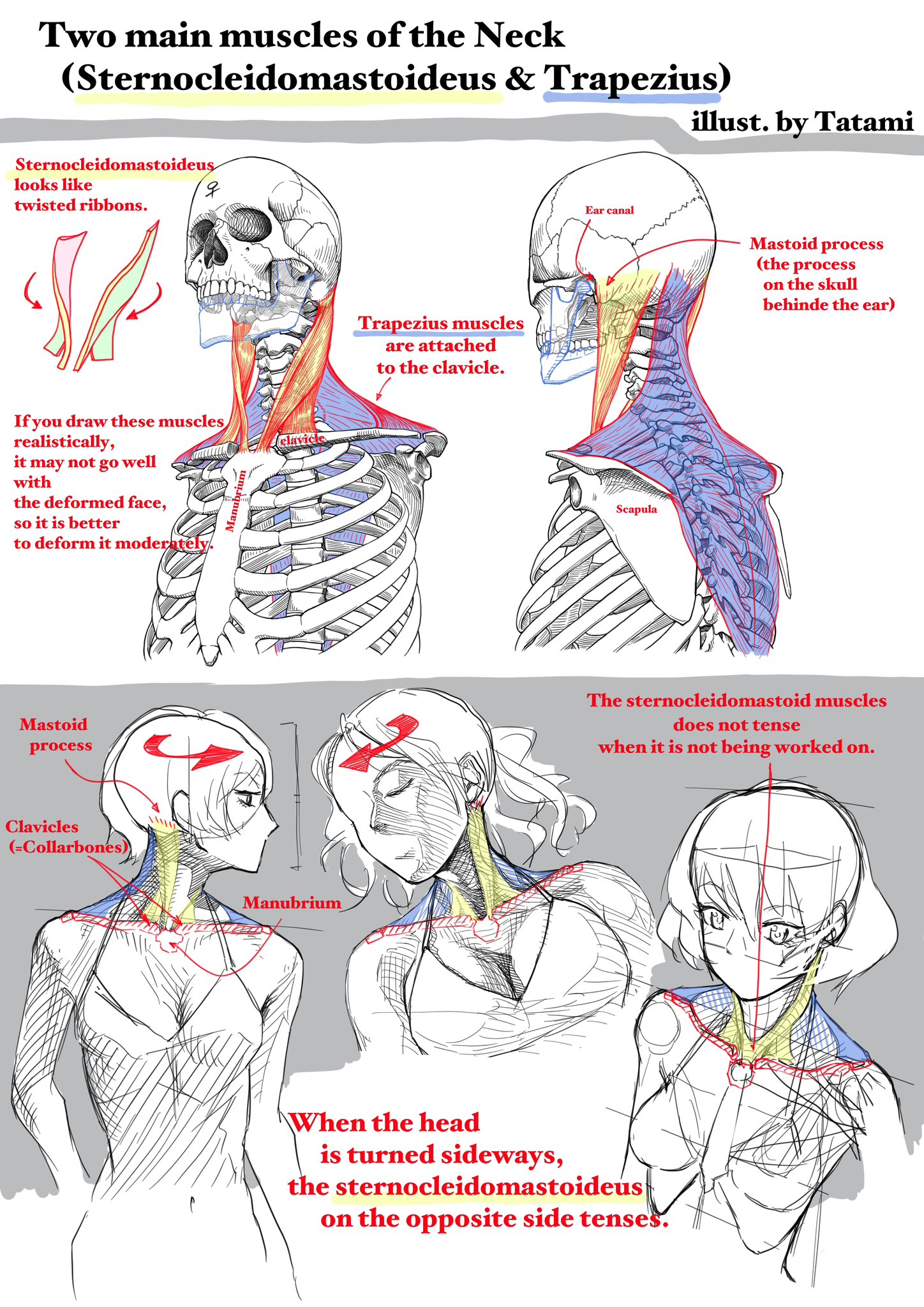
COMPOSITION
























DESIGN
-
James Gerde – The way the leaves dance in the rain
Read more: James Gerde – The way the leaves dance in the rainhttps://www.instagram.com/gerdegotit/reel/C6s-2r2RgSu/
Since spending a lot of time recently with SDXL I’ve since made my way back to SD 1.5
While the models overall have less fidelity. There is just no comparing to the current motion models we have available for animatediff with 1.5 models.
To date this is one of my favorite pieces. Not because I think it’s even the best it can be. But because the workflow adjustments unlocked some very important ideas I can’t wait to try out.
Performance by @silkenkelly and @itxtheballerina on IG


















COLOR
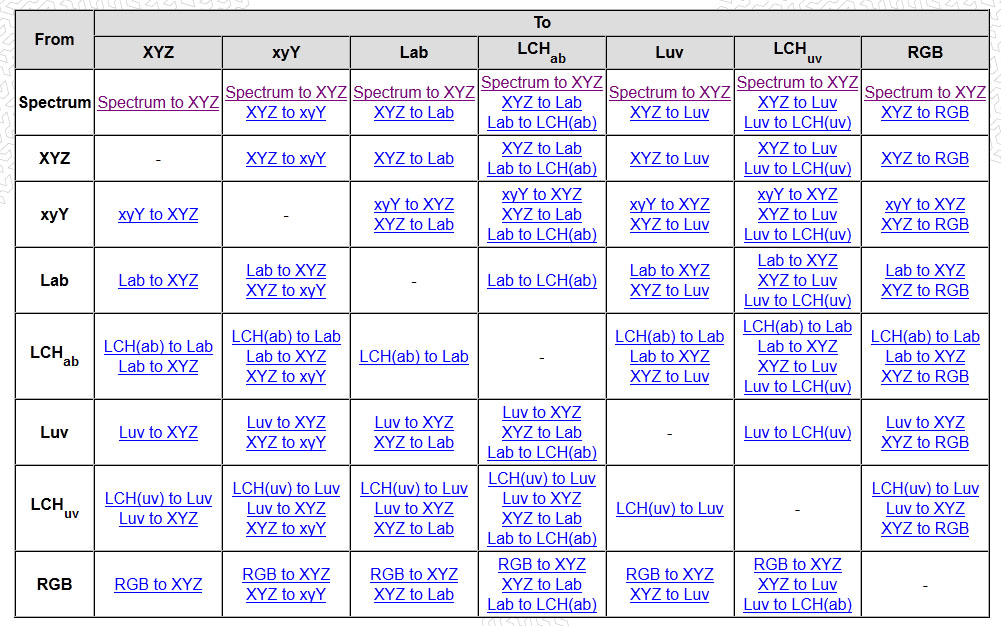
-
Victor Perez – The Color Management Handbook for Visual Effects Artists
Read more: Victor Perez – The Color Management Handbook for Visual Effects ArtistsDigital Color Principles, Color Management Fundamentals & ACES Workflows

-
mmColorTarget – Nuke Gizmo for color matching a MacBeth chart
Read more: mmColorTarget – Nuke Gizmo for color matching a MacBeth charthttps://www.marcomeyer-vfx.de/posts/2014-04-11-mmcolortarget-nuke-gizmo/
https://www.marcomeyer-vfx.de/posts/mmcolortarget-nuke-gizmo/
https://vimeo.com/9.1652466e+07
https://www.nukepedia.com/gizmos/colour/mmcolortarget
-
PTGui 13 beta adds control through a Patch Editor
Read more: PTGui 13 beta adds control through a Patch EditorAdditions:
- Patch Editor (PTGui Pro)
- DNG output
- Improved RAW / DNG handling
- JPEG 2000 support
- Performance improvements

-
colorhunt.co
Read more: colorhunt.coColor Hunt is a free and open platform for color inspiration with thousands of trendy hand-picked color palettes.

-
Paul Debevec, Chloe LeGendre, Lukas Lepicovsky – Jointly Optimizing Color Rendition and In-Camera Backgrounds in an RGB Virtual Production Stage
Read more: Paul Debevec, Chloe LeGendre, Lukas Lepicovsky – Jointly Optimizing Color Rendition and In-Camera Backgrounds in an RGB Virtual Production Stagehttps://arxiv.org/pdf/2205.12403.pdf
RGB LEDs vs RGBWP (RGB + lime + phospor converted amber) LEDs
Local copy:
-
About green screens
Read more: About green screenshackaday.com/2015/02/07/how-green-screen-worked-before-computers/
www.newtek.com/blog/tips/best-green-screen-materials/
www.chromawall.com/blog//chroma-key-green

Chroma Key Green, the color of green screens is also known as Chroma Green and is valued at approximately 354C in the Pantone color matching system (PMS).
Chroma Green can be broken down in many different ways. Here is green screen green as other values useful for both physical and digital production:
Green Screen as RGB Color Value: 0, 177, 64
Green Screen as CMYK Color Value: 81, 0, 92, 0
Green Screen as Hex Color Value: #00b140
Green Screen as Websafe Color Value: #009933Chroma Key Green is reasonably close to an 18% gray reflectance.
Illuminate your green screen with an uniform source with less than 2/3 EV variation.
The level of brightness at any given f-stop should be equivalent to a 90% white card under the same lighting. -
THOMAS MANSENCAL – The Apparent Simplicity of RGB Rendering
Read more: THOMAS MANSENCAL – The Apparent Simplicity of RGB Rendering
https://thomasmansencal.substack.com/p/the-apparent-simplicity-of-rgb-rendering
The primary goal of physically-based rendering (PBR) is to create a simulation that accurately reproduces the imaging process of electro-magnetic spectrum radiation incident to an observer. This simulation should be indistinguishable from reality for a similar observer.
Because a camera is not sensitive to incident light the same way than a human observer, the images it captures are transformed to be colorimetric. A project might require infrared imaging simulation, a portion of the electro-magnetic spectrum that is invisible to us. Radically different observers might image the same scene but the act of observing does not change the intrinsic properties of the objects being imaged. Consequently, the physical modelling of the virtual scene should be independent of the observer.










LIGHTING
-
Composition – 5 tips for creating perfect cinematic lighting and making your work look stunning
Read more: Composition – 5 tips for creating perfect cinematic lighting and making your work look stunning
http://www.diyphotography.net/5-tips-creating-perfect-cinematic-lighting-making-work-look-stunning/
1. Learn the rules of lighting
2. Learn when to break the rules
3. Make your key light larger
4. Reverse keying
5. Always be backlighting
-
Practical Aspects of Spectral Data and LEDs in Digital Content Production and Virtual Production – SIGGRAPH 2022
Read more: Practical Aspects of Spectral Data and LEDs in Digital Content Production and Virtual Production – SIGGRAPH 2022
Comparison to the commercial side

https://www.ecolorled.com/blog/detail/what-is-rgb-rgbw-rgbic-strip-lights
RGBW (RGB + White) LED strip uses a 4-in-1 LED chip made up of red, green, blue, and white.
RGBWW (RGB + White + Warm White) LED strip uses either a 5-in-1 LED chip with red, green, blue, white, and warm white for color mixing. The only difference between RGBW and RGBWW is the intensity of the white color. The term RGBCCT consists of RGB and CCT. CCT (Correlated Color Temperature) means that the color temperature of the led strip light can be adjusted to change between warm white and white. Thus, RGBWW strip light is another name of RGBCCT strip.
RGBCW is the acronym for Red, Green, Blue, Cold, and Warm. These 5-in-1 chips are used in supper bright smart LED lighting products
-
Custom bokeh in a raytraced DOF render
Read more: Custom bokeh in a raytraced DOF render

To achieve a custom pinhole camera effect with a custom bokeh in Arnold Raytracer, you can follow these steps:
- Set the render camera with a focal length around 50 (or as needed)
- Set the F-Stop to a high value (e.g., 22).
- Set the focus distance as you require
- Turn on DOF
- Place a plane a few cm in front of the camera.
- Texture the plane with a transparent shape at the center of it. (Transmission with no specular roughness)
-
Tracing Spherical harmonics and how Weta used them in production
Read more: Tracing Spherical harmonics and how Weta used them in productionA way to approximate complex lighting in ultra realistic renders.
All SH lighting techniques involve replacing parts of standard lighting equations with spherical functions that have been projected into frequency space using the spherical harmonics as a basis.
http://www.cs.columbia.edu/~cs4162/slides/spherical-harmonic-lighting.pdf
Spherical harmonics as used at Weta Digital
-
Willem Zwarthoed – Aces gamut in VFX production pdf
Read more: Willem Zwarthoed – Aces gamut in VFX production pdfhttps://www.provideocoalition.com/color-management-part-12-introducing-aces/
Local copy:
https://www.slideshare.net/hpduiker/acescg-a-common-color-encoding-for-visual-effects-applications
-
Aputure AL-F7 – dimmable Led Video Light, CRI95+, 3200-9500K
Read more: Aputure AL-F7 – dimmable Led Video Light, CRI95+, 3200-9500KHigh CRI of ≥95
256 LEDs with 45° beam angle
3200 to 9500K variable color temperature
1 to 100% Stepless Dimming, 1500 Lux Brightness at 3.3′
LCD Info Screen. Powered by an L-series battery, D-Tap, or USB-C
Because the light has a variable color range of 3200 to 9500K, when the light is set to 5500K (daylight balanced) both sets of LEDs are on at full, providing the maximum brightness from this fixture when compared to using the light at 3200 or 9500K.
The LCD screen provides information on the fixture’s output as well as the charge state of the battery. The screen also indicates whether the adjustment knob is controlling brightness or color temperature. To switch from brightness to CCT or CCT to brightness, just apply a short press to the adjustment knob.
The included cold shoe ball joint adapter enables mounting the light to your camera’s accessory shoe via the 1/4″-20 threaded hole on the fixture. In addition, the bottom of the cold shoe foot features a 3/8″-16 threaded hole, and includes a 3/8″-16 to 1/4″-20 reducing bushing.










{kind=link}
COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…
-
Photography basics: Production Rendering Resolution Charts
-
Kling 1.6 and competitors – advanced tests and comparisons
-
VFX pipeline – Render Wall Farm management topics
-
Emmanuel Tsekleves – Writing Research Papers
-
Photography basics: Shutter angle and shutter speed and motion blur
-
Rec-2020 – TVs new color gamut standard used by Dolby Vision?
-
Free fonts
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
