


COMPOSITION
-
Composition and The Expressive Nature Of Light
Read more: Composition and The Expressive Nature Of Lighthttp://www.huffingtonpost.com/bill-danskin/post_12457_b_10777222.html
George Sand once said “ The artist vocation is to send light into the human heart.”


















DESIGN
-
The Hybrids by Phil Langer – hyper-realistic AI-generated human animal portraits
Read more: The Hybrids by Phil Langer – hyper-realistic AI-generated human animal portraitshttps://www.reddit.com/r/aiArt/comments/1azepd6/hybrid_portraits_by_phil_langer/
https://www.thehybridportraits.com/
https://www.instagram.com/hybridportraits/

-
This legendary DC Comics style guide was nearly lost for years – now you can buy it
Read more: This legendary DC Comics style guide was nearly lost for years – now you can buy ithttps://www.fastcompany.com/91133306/dc-comics-style-guide-was-lost-for-years-now-you-can-buy-it
Reproduced from a rare original copy, the book features over 165 highly-detailed scans of the legendary art by José Luis García-López, with an introduction by Paul Levitz, former president of DC Comics.
https://standardsmanual.com/products/1982-dc-comics-style-guide


















































































COLOR
-
Colour – MacBeth Chart Checker Detection
Read more: Colour – MacBeth Chart Checker Detectiongithub.com/colour-science/colour-checker-detection
A Python package implementing various colour checker detection algorithms and related utilities.

-
Akiyoshi Kitaoka – Surround biased illumination perception
Read more: Akiyoshi Kitaoka – Surround biased illumination perceptionhttps://x.com/AkiyoshiKitaoka/status/1798705648001327209
The left face appears whitish and the right one blackish, but they are made up of the same luminance.

https://community.wolfram.com/groups/-/m/t/3191015
Illusory staircase Gelb effect
https://www.psy.ritsumei.ac.jp/akitaoka/illgelbe.html
-
The Maya civilization and the color blue
Read more: The Maya civilization and the color blueMaya blue is a highly unusual pigment because it is a mix of organic indigo and an inorganic clay mineral called palygorskite.
Echoing the color of an azure sky, the indelible pigment was used to accentuate everything from ceramics to human sacrifices in the Late Preclassic period (300 B.C. to A.D. 300).
A team of researchers led by Dean Arnold, an adjunct curator of anthropology at the Field Museum in Chicago, determined that the key to Maya blue was actually a sacred incense called copal.
By heating the mixture of indigo, copal and palygorskite over a fire, the Maya produced the unique pigment, he reported at the time.
-
GretagMacbeth Color Checker Numeric Values and Middle Gray
Read more: GretagMacbeth Color Checker Numeric Values and Middle GrayThe human eye perceives half scene brightness not as the linear 50% of the present energy (linear nature values) but as 18% of the overall brightness. We are biased to perceive more information in the dark and contrast areas. A Macbeth chart helps with calibrating back into a photographic capture into this “human perspective” of the world.
https://en.wikipedia.org/wiki/Middle_gray
In photography, painting, and other visual arts, middle gray or middle grey is a tone that is perceptually about halfway between black and white on a lightness scale in photography and printing, it is typically defined as 18% reflectance in visible light

Light meters, cameras, and pictures are often calibrated using an 18% gray card[4][5][6] or a color reference card such as a ColorChecker. On the assumption that 18% is similar to the average reflectance of a scene, a grey card can be used to estimate the required exposure of the film.
https://en.wikipedia.org/wiki/ColorChecker
(more…) -
FXGuide – ACES 2.0 with ILM’s Alex Fry
Read more: FXGuide – ACES 2.0 with ILM’s Alex Fry
https://draftdocs.acescentral.com/background/whats-new/
ACES 2.0 is the second major release of the components that make up the ACES system. The most significant change is a new suite of rendering transforms whose design was informed by collected feedback and requests from users of ACES 1. The changes aim to improve the appearance of perceived artifacts and to complete previously unfinished components of the system, resulting in a more complete, robust, and consistent product.
Highlights of the key changes in ACES 2.0 are as follows:
- New output transforms, including:
- A less aggressive tone scale
- More intuitive controls to create custom outputs to non-standard displays
- Robust gamut mapping to improve perceptual uniformity
- Improved performance of the inverse transforms
- Enhanced AMF specification
- An updated specification for ACES Transform IDs
- OpenEXR compression recommendations
- Enhanced tools for generating Input Transforms and recommended procedures for characterizing prosumer cameras
- Look Transform Library
- Expanded documentation
Rendering Transform
The most substantial change in ACES 2.0 is a complete redesign of the rendering transform.
ACES 2.0 was built as a unified system, rather than through piecemeal additions. Different deliverable outputs “match” better and making outputs to display setups other than the provided presets is intended to be user-driven. The rendering transforms are less likely to produce undesirable artifacts “out of the box”, which means less time can be spent fixing problematic images and more time making pictures look the way you want.
Key design goals
- Improve consistency of tone scale and provide an easy to use parameter to allow for outputs between preset dynamic ranges
- Minimize hue skews across exposure range in a region of same hue
- Unify for structural consistency across transform type
- Easy to use parameters to create outputs other than the presets
- Robust gamut mapping to improve harsh clipping artifacts
- Fill extents of output code value cube (where appropriate and expected)
- Invertible – not necessarily reversible, but Output > ACES > Output round-trip should be possible
- Accomplish all of the above while maintaining an acceptable “out-of-the box” rendering
- New output transforms, including:
-
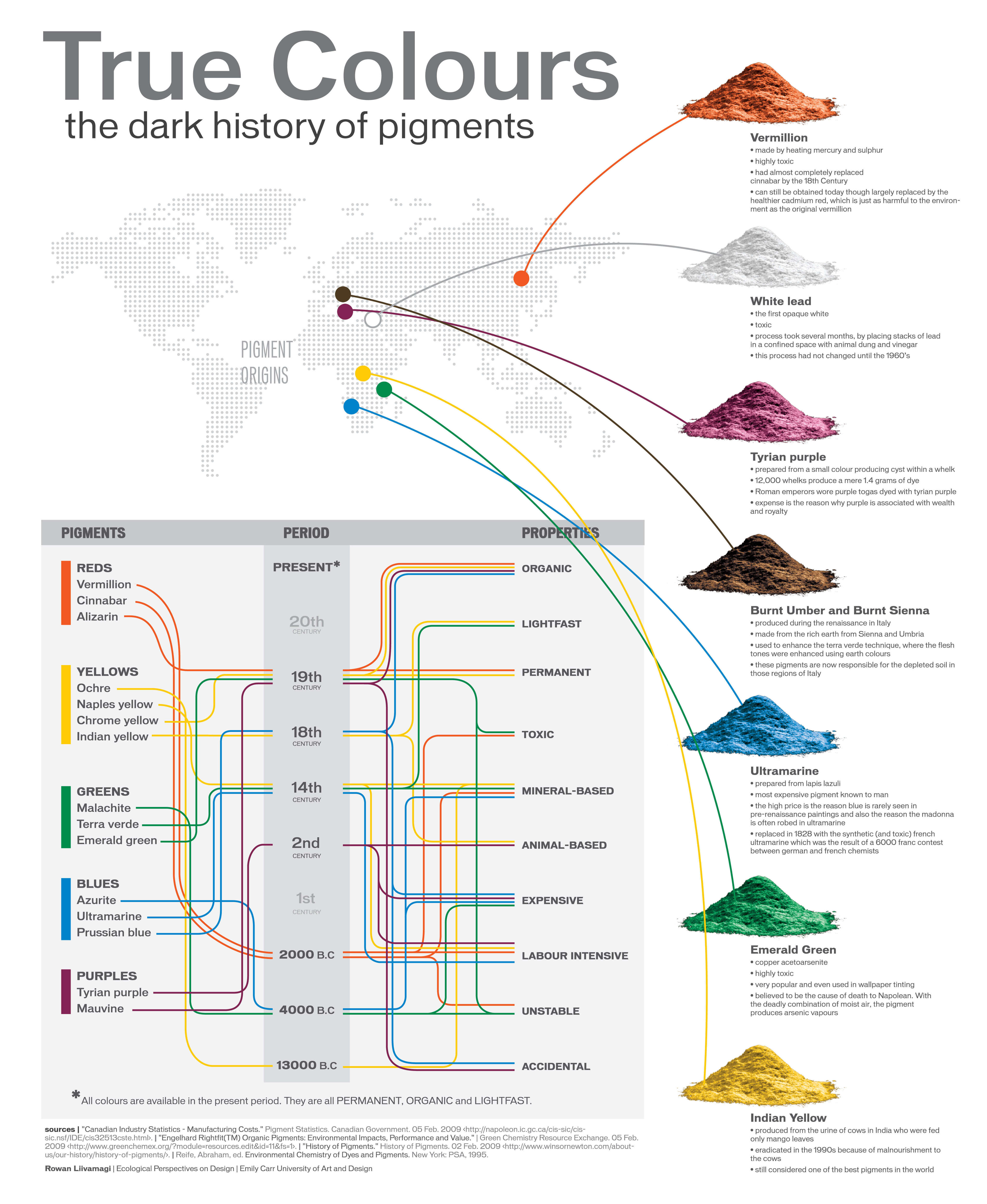
A Brief History of Color in Art
Read more: A Brief History of Color in Artwww.artsy.net/article/the-art-genome-project-a-brief-history-of-color-in-art
Of all the pigments that have been banned over the centuries, the color most missed by painters is likely Lead White.
This hue could capture and reflect a gleam of light like no other, though its production was anything but glamorous. The 17th-century Dutch method for manufacturing the pigment involved layering cow and horse manure over lead and vinegar. After three months in a sealed room, these materials would combine to create flakes of pure white. While scientists in the late 19th century identified lead as poisonous, it wasn’t until 1978 that the United States banned the production of lead white paint.
More reading:
www.canva.com/learn/color-meanings/https://www.infogrades.com/history-events-infographics/bizarre-history-of-colors/











LIGHTING
-
HDRI Median Cut plugin
Read more: HDRI Median Cut pluginwww.hdrlabs.com/picturenaut/plugins.html

Note. The Median Cut algorithm is typically used for color quantization, which involves reducing the number of colors in an image while preserving its visual quality. It doesn’t directly provide a way to identify the brightest areas in an image. However, if you’re interested in identifying the brightest areas, you might want to look into other methods like thresholding, histogram analysis, or edge detection, through openCV for example.
Here is an openCV example:
(more…) -
domeble – Hi-Resolution CGI Backplates and 360° HDRI
Read more: domeble – Hi-Resolution CGI Backplates and 360° HDRIWhen collecting hdri make sure the data supports basic metadata, such as:
- Iso
- Aperture
- Exposure time or shutter time
- Color temperature
- Color space Exposure value (what the sensor receives of the sun intensity in lux)
- 7+ brackets (with 5 or 6 being the perceived balanced exposure)
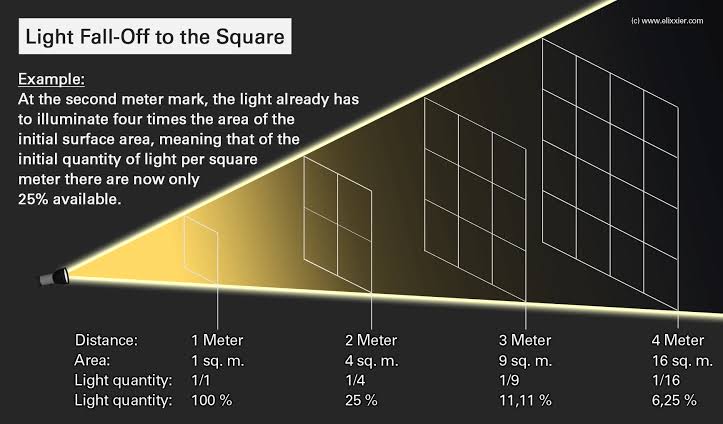
In image processing, computer graphics, and photography, high dynamic range imaging (HDRI or just HDR) is a set of techniques that allow a greater dynamic range of luminances (a Photometry measure of the luminous intensity per unit area of light travelling in a given direction. It describes the amount of light that passes through or is emitted from a particular area, and falls within a given solid angle) between the lightest and darkest areas of an image than standard digital imaging techniques or photographic methods. This wider dynamic range allows HDR images to represent more accurately the wide range of intensity levels found in real scenes ranging from direct sunlight to faint starlight and to the deepest shadows.
The two main sources of HDR imagery are computer renderings and merging of multiple photographs, which in turn are known as low dynamic range (LDR) or standard dynamic range (SDR) images. Tone Mapping (Look-up) techniques, which reduce overall contrast to facilitate display of HDR images on devices with lower dynamic range, can be applied to produce images with preserved or exaggerated local contrast for artistic effect. Photography
In photography, dynamic range is measured in Exposure Values (in photography, exposure value denotes all combinations of camera shutter speed and relative aperture that give the same exposure. The concept was developed in Germany in the 1950s) differences or stops, between the brightest and darkest parts of the image that show detail. An increase of one EV or one stop is a doubling of the amount of light.
The human response to brightness is well approximated by a Steven’s power law, which over a reasonable range is close to logarithmic, as described by the Weber�Fechner law, which is one reason that logarithmic measures of light intensity are often used as well.
HDR is short for High Dynamic Range. It’s a term used to describe an image which contains a greater exposure range than the “black” to “white” that 8 or 16-bit integer formats (JPEG, TIFF, PNG) can describe. Whereas these Low Dynamic Range images (LDR) can hold perhaps 8 to 10 f-stops of image information, HDR images can describe beyond 30 stops and stored in 32 bit images.

-
HDRI Resources
Read more: HDRI ResourcesText2Light
- https://www.cgtrader.com/free-3d-models/exterior/other/10-free-hdr-panoramas-created-with-text2light-zero-shot
- https://frozenburning.github.io/projects/text2light/
- https://github.com/FrozenBurning/Text2Light
Royalty free links
- https://locationtextures.com/panoramas/
- http://www.noahwitchell.com/freebies
- https://polyhaven.com/hdris
- https://hdrmaps.com/
- https://www.ihdri.com/
- https://hdrihaven.com/
- https://www.domeble.com/
- http://www.hdrlabs.com/sibl/archive.html
- https://www.hdri-hub.com/hdrishop/hdri
- http://noemotionhdrs.net/hdrevening.html
- https://www.openfootage.net/hdri-panorama/
- https://www.zwischendrin.com/en/browse/hdri
Nvidia GauGAN360
-
Open Source Nvidia Omniverse
Read more: Open Source Nvidia Omniverseblogs.nvidia.com/blog/2019/03/18/omniverse-collaboration-platform/

developer.nvidia.com/nvidia-omniverse
An open, Interactive 3D Design Collaboration Platform for Multi-Tool Workflows to simplify studio workflows for real-time graphics.
It supports Pixar’s Universal Scene Description technology for exchanging information about modeling, shading, animation, lighting, visual effects and rendering across multiple applications.
It also supports NVIDIA’s Material Definition Language, which allows artists to exchange information about surface materials across multiple tools.
With Omniverse, artists can see live updates made by other artists working in different applications. They can also see changes reflected in multiple tools at the same time.
For example an artist using Maya with a portal to Omniverse can collaborate with another artist using UE4 and both will see live updates of each others’ changes in their application.
-
Aputure AL-F7 – dimmable Led Video Light, CRI95+, 3200-9500K
Read more: Aputure AL-F7 – dimmable Led Video Light, CRI95+, 3200-9500KHigh CRI of ≥95
256 LEDs with 45° beam angle
3200 to 9500K variable color temperature
1 to 100% Stepless Dimming, 1500 Lux Brightness at 3.3′
LCD Info Screen. Powered by an L-series battery, D-Tap, or USB-C
Because the light has a variable color range of 3200 to 9500K, when the light is set to 5500K (daylight balanced) both sets of LEDs are on at full, providing the maximum brightness from this fixture when compared to using the light at 3200 or 9500K.
The LCD screen provides information on the fixture’s output as well as the charge state of the battery. The screen also indicates whether the adjustment knob is controlling brightness or color temperature. To switch from brightness to CCT or CCT to brightness, just apply a short press to the adjustment knob.
The included cold shoe ball joint adapter enables mounting the light to your camera’s accessory shoe via the 1/4″-20 threaded hole on the fixture. In addition, the bottom of the cold shoe foot features a 3/8″-16 threaded hole, and includes a 3/8″-16 to 1/4″-20 reducing bushing.


-
Unity 3D resources
Read more: Unity 3D resources
http://answers.unity3d.com/questions/12321/how-can-i-start-learning-unity-fast-list-of-tutori.html
If you have no previous experience with Unity, start with these six video tutorials which give a quick overview of the Unity interface and some important features http://unity3d.com/support/documentation/video/









COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
RawTherapee – a free, open source, cross-platform raw image and HDRi processing program
-
VFX pipeline – Render Wall Farm management topics
-
Methods for creating motion blur in Stop motion
-
Eyeline Labs VChain – Chain-of-Visual-Thought for Reasoning in Video Generation for better AI physics
-
Rec-2020 – TVs new color gamut standard used by Dolby Vision?
-
Black Body color aka the Planckian Locus curve for white point eye perception
-
AnimationXpress.com interviews Daniele Tosti for TheCgCareer.com channel
-
The Public Domain Is Working Again — No Thanks To Disney
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
