The intricate relationship between the eyes and the brain, often termed the eye-mind connection, reveals that vision is predominantly a cognitive process. This understanding has profound implications for fields such as design, where capturing and maintaining attention is paramount. This essay delves into the nuances of visual perception, the brain’s role in interpreting visual data, and how this knowledge can be applied to effective design strategies.
This cognitive aspect of vision is evident in phenomena such as optical illusions, where the brain interprets visual information in a way that contradicts physical reality. These illusions underscore that what we “see” is not merely a direct recording of the external world but a constructed experience shaped by cognitive processes.
Understanding the cognitive nature of vision is crucial for effective design. Designers must consider how the brain processes visual information to create compelling and engaging visuals. This involves several key principles:
To measure the contrast ratio you will need a light meter. The process starts with you measuring the main source of light, or the key light.
Get a reading from the brightest area on the face of your subject. Then, measure the area lit by the secondary light, or fill light. To make sense of what you have just measured you have to understand that the information you have just gathered is in F-stops, a measure of light. With each additional F-stop, for example going one stop from f/1.4 to f/2.0, you create a doubling of light. The reverse is also true; moving one stop from f/8.0 to f/5.6 results in a halving of the light.
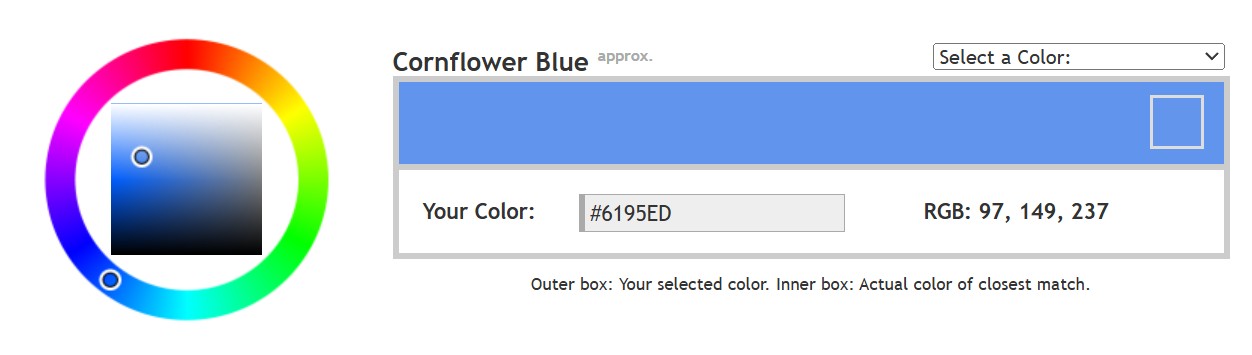
Note. The Median Cut algorithm is typically used for color quantization, which involves reducing the number of colors in an image while preserving its visual quality. It doesn’t directly provide a way to identify the brightest areas in an image. However, if you’re interested in identifying the brightest areas, you might want to look into other methods like thresholding, histogram analysis, or edge detection, through openCV for example.
In the retina, photoreceptors, bipolar cells, and horizontal cells work together to process visual information before it reaches the brain. Here’s how each cell type contributes to vision:
RASTERIZATION Rasterisation (or rasterization) is the task of taking the information described in a vector graphics format OR the vertices of triangles making 3D shapes and converting them into a raster image (a series of pixels, dots or lines, which, when displayed together, create the image which was represented via shapes), or in other words “rasterizing” vectors or 3D models onto a 2D plane for display on a computer screen.
For each triangle of a 3D shape, you project the corners of the triangle on the virtual screen with some math (projective geometry). Then you have the position of the 3 corners of the triangle on the pixel screen. Those 3 points have texture coordinates, so you know where in the texture are the 3 corners. The cost is proportional to the number of triangles, and is only a little bit affected by the screen resolution.
In computer graphics, a raster graphics orbitmap image is a dot matrix data structure that represents a generally rectangular grid of pixels (points of color), viewable via a monitor, paper, or other display medium.
With rasterization, objects on the screen are created from a mesh of virtual triangles, or polygons, that create 3D models of objects. A lot of information is associated with each vertex, including its position in space, as well as information about color, texture and its “normal,” which is used to determine the way the surface of an object is facing.
Computers then convert the triangles of the 3D models into pixels, or dots, on a 2D screen. Each pixel can be assigned an initial color value from the data stored in the triangle vertices.
Further pixel processing or “shading,” including changing pixel color based on how lights in the scene hit the pixel, and applying one or more textures to the pixel, combine to generate the final color applied to a pixel.
The main advantage of rasterization is its speed. However, rasterization is simply the process of computing the mapping from scene geometry to pixels and does not prescribe a particular way to compute the color of those pixels. So it cannot take shading, especially the physical light, into account and it cannot promise to get a photorealistic output. That’s a big limitation of rasterization.
There are also multiple problems:
If you have two triangles one is behind the other, you will draw twice all the pixels. you only keep the pixel from the triangle that is closer to you (Z-buffer), but you still do the work twice.
The borders of your triangles are jagged as it is hard to know if a pixel is in the triangle or out. You can do some smoothing on those, that is anti-aliasing.
You have to handle every triangles (including the ones behind you) and then see that they do not touch the screen at all. (we have techniques to mitigate this where we only look at triangles that are in the field of view)
Transparency is hard to handle (you can’t just do an average of the color of overlapping transparent triangles, you have to do it in the right order)
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.