


COMPOSITION
DESIGN
-
Turn Yourself Into an Action Figure Using ChatGPT
Read more: Turn Yourself Into an Action Figure Using ChatGPT
ChatGPT Action Figure Prompts:
Create an action figure from the photo. It must be visualised in a realistic way. There should be accessories next to the figure like a UX designer have, Macbook Pro, a camera, drawing tablet, headset etc. Add a hole to the top of the box in the action figure. Also write the text “UX Mate” and below it “Keep Learning! Keep Designing
Use this image to create a picture of a action figure toy of a construction worker in a blister package from head to toe with accessories including a hammer, a staple gun and a ladder. The package should read “Kirk The Handy Man”
Create a realistic image of a toy action figure box. The box should be designed in a toy-equipment/action-figure style, with a cut-out window at the top like classic action figure packaging. The main color of the box and moleskine notebook should match the color of my jacket (referenced visually). Add colorful Mexican skull decorations across the box for a vibrant and artistic flair. Inside the box, include a “Your name” action figure, posed heroically. Next to the figure, arrange the following “equipment” in a stylized layout: • item 1 • item 2 … On the box, write: “Your name” (bold title font) Underneath: “Your role or anything else” The entire scene should look like a real product mockup, highly realistic, lit like a studio product photo. On the box, write: “Your name” (bold title font) Underneath: “Your role or description” The entire scene should look like a real product mockup, highly realistic, lit like a studio product photo. Prompt on Kling AI The figure steps out of its toy packaging and begins walking forward. As he continues to walk, the camera gradually zooms out in sync with his movement.
“Create image. Create a toy of the person in the photo. Let it be an action figure. Next to the figure, there should be the toy’s equipment, each in its individual blisters. 1) a book called “Tecnoforma”. 2) A 3-headed dog with a tag that says “Troika” and a bone at its feet with word “austerity” written on it. 3) a three-headed Hydra with with a tag called “Geringonça”. 4) a book titled “D. Sebastião”. Don’t repeat the equipment under any circumstance. The card holding the blister should be strong orange. Also, on top of the box, write ‘Pedro Passos Coelho’ and underneath it, ‘PSD action figure’. The figure and equipment must all be inside blisters. Visualize this in a realistic way.”


















COLOR
-
Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental process
Read more: Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental processhttps://www.chrbutler.com/understanding-the-eye-mind-connection
The intricate relationship between the eyes and the brain, often termed the eye-mind connection, reveals that vision is predominantly a cognitive process. This understanding has profound implications for fields such as design, where capturing and maintaining attention is paramount. This essay delves into the nuances of visual perception, the brain’s role in interpreting visual data, and how this knowledge can be applied to effective design strategies.
This cognitive aspect of vision is evident in phenomena such as optical illusions, where the brain interprets visual information in a way that contradicts physical reality. These illusions underscore that what we “see” is not merely a direct recording of the external world but a constructed experience shaped by cognitive processes.
Understanding the cognitive nature of vision is crucial for effective design. Designers must consider how the brain processes visual information to create compelling and engaging visuals. This involves several key principles:
- Attention and Engagement
- Visual Hierarchy
- Cognitive Load Management
- Context and Meaning

-
Willem Zwarthoed – Aces gamut in VFX production pdf
Read more: Willem Zwarthoed – Aces gamut in VFX production pdfhttps://www.provideocoalition.com/color-management-part-12-introducing-aces/
Local copy:
https://www.slideshare.net/hpduiker/acescg-a-common-color-encoding-for-visual-effects-applications
-
Scientists claim to have discovered ‘new colour’ no one has seen before: Olo
Read more: Scientists claim to have discovered ‘new colour’ no one has seen before: Olohttps://www.bbc.com/news/articles/clyq0n3em41o
By stimulating specific cells in the retina, the participants claim to have witnessed a blue-green colour that scientists have called “olo”, but some experts have said the existence of a new colour is “open to argument”.
The findings, published in the journal Science Advances on Friday, have been described by the study’s co-author, Prof Ren Ng from the University of California, as “remarkable”.

(A) System inputs. (i) Retina map of 103 cone cells preclassified by spectral type (7). (ii) Target visual percept (here, a video of a child, see movie S1 at 1:04). (iii) Infrared cellular-scale imaging of the retina with 60-frames-per-second rolling shutter. Fixational eye movement is visible over the three frames shown.
(B) System outputs. (iv) Real-time per-cone target activation levels to reproduce the target percept, computed by: extracting eye motion from the input video relative to the retina map; identifying the spectral type of every cone in the field of view; computing the per-cone activation the target percept would have produced. (v) Intensities of visible-wavelength 488-nm laser microdoses at each cone required to achieve its target activation level.
(C) Infrared imaging and visible-wavelength stimulation are physically accomplished in a raster scan across the retinal region using AOSLO. By modulating the visible-wavelength beam’s intensity, the laser microdoses shown in (v) are delivered. Drawing adapted with permission [Harmening and Sincich (54)].
(D) Examples of target percepts with corresponding cone activations and laser microdoses, ranging from colored squares to complex imagery. Teal-striped regions represent the color “olo” of stimulating only M cones.











LIGHTING
-
Arto T. – A workflow for creating photorealistic, equirectangular 360° panoramas in ComfyUI using Flux
Read more: Arto T. – A workflow for creating photorealistic, equirectangular 360° panoramas in ComfyUI using Fluxhttps://civitai.com/models/735980/flux-equirectangular-360-panorama
https://civitai.com/models/745010?modelVersionId=833115
The trigger phrase is “equirectangular 360 degree panorama”. I would avoid saying “spherical projection” since that tends to result in non-equirectangular spherical images.
Image resolution should always be a 2:1 aspect ratio. 1024 x 512 or 1408 x 704 work quite well and were used in the training data. 2048 x 1024 also works.
I suggest using a weight of 0.5 – 1.5. If you are having issues with the image generating too flat instead of having the necessary spherical distortion, try increasing the weight above 1, though this could negatively impact small details of the image. For Flux guidance, I recommend a value of about 2.5 for realistic scenes.
8-bit output at the moment


-
Practical Aspects of Spectral Data and LEDs in Digital Content Production and Virtual Production – SIGGRAPH 2022
Read more: Practical Aspects of Spectral Data and LEDs in Digital Content Production and Virtual Production – SIGGRAPH 2022
Comparison to the commercial side

https://www.ecolorled.com/blog/detail/what-is-rgb-rgbw-rgbic-strip-lights
RGBW (RGB + White) LED strip uses a 4-in-1 LED chip made up of red, green, blue, and white.
RGBWW (RGB + White + Warm White) LED strip uses either a 5-in-1 LED chip with red, green, blue, white, and warm white for color mixing. The only difference between RGBW and RGBWW is the intensity of the white color. The term RGBCCT consists of RGB and CCT. CCT (Correlated Color Temperature) means that the color temperature of the led strip light can be adjusted to change between warm white and white. Thus, RGBWW strip light is another name of RGBCCT strip.
RGBCW is the acronym for Red, Green, Blue, Cold, and Warm. These 5-in-1 chips are used in supper bright smart LED lighting products
-
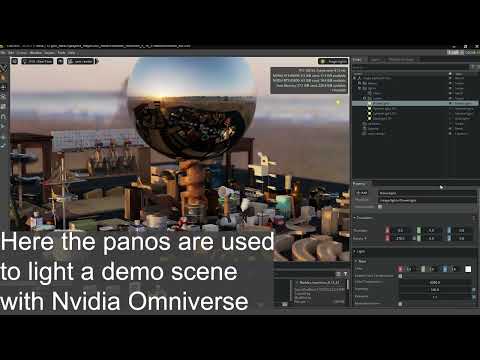
DiffusionLight: HDRI Light Probes for Free by Painting a Chrome Ball
Read more: DiffusionLight: HDRI Light Probes for Free by Painting a Chrome Ballhttps://diffusionlight.github.io/
https://github.com/DiffusionLight/DiffusionLight
https://github.com/DiffusionLight/DiffusionLight?tab=MIT-1-ov-file#readme
https://colab.research.google.com/drive/15pC4qb9mEtRYsW3utXkk-jnaeVxUy-0S
“a simple yet effective technique to estimate lighting in a single input image. Current techniques rely heavily on HDR panorama datasets to train neural networks to regress an input with limited field-of-view to a full environment map. However, these approaches often struggle with real-world, uncontrolled settings due to the limited diversity and size of their datasets. To address this problem, we leverage diffusion models trained on billions of standard images to render a chrome ball into the input image. Despite its simplicity, this task remains challenging: the diffusion models often insert incorrect or inconsistent objects and cannot readily generate images in HDR format. Our research uncovers a surprising relationship between the appearance of chrome balls and the initial diffusion noise map, which we utilize to consistently generate high-quality chrome balls. We further fine-tune an LDR difusion model (Stable Diffusion XL) with LoRA, enabling it to perform exposure bracketing for HDR light estimation. Our method produces convincing light estimates across diverse settings and demonstrates superior generalization to in-the-wild scenarios.”












COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
