


COMPOSITION
-
Photography basics: Depth of Field and composition
Read more: Photography basics: Depth of Field and compositionDepth of field is the range within which focusing is resolved in a photo.
Aperture has a huge affect on to the depth of field.
Changing the f-stops (f/#) of a lens will change aperture and as such the DOF.
f-stops are a just certain number which is telling you the size of the aperture. That’s how f-stop is related to aperture (and DOF).
If you increase f-stops, it will increase DOF, the area in focus (and decrease the aperture). On the other hand, decreasing the f-stop it will decrease DOF (and increase the aperture).
The red cone in the figure is an angular representation of the resolution of the system. Versus the dotted lines, which indicate the aperture coverage. Where the lines of the two cones intersect defines the total range of the depth of field.
This image explains why the longer the depth of field, the greater the range of clarity.




















DESIGN
-
boldtron – 𝗗𝗘𝗣𝗜𝗖𝗧𝗜𝗡𝗚 𝗪𝗔𝗧𝗘𝗥𝗚𝗨𝗡𝗦
Read more: boldtron – 𝗗𝗘𝗣𝗜𝗖𝗧𝗜𝗡𝗚 𝗪𝗔𝗧𝗘𝗥𝗚𝗨𝗡𝗦See this Instagram post by @boldtron using ComfyUI + Krea
https://www.instagram.com/p/C5v-H0PNYYg/?utm_source=ig_web_button_share_sheet















COLOR
-
Composition – cinematography Cheat Sheet
Read more: Composition – cinematography Cheat Sheet
Where is our eye attracted first? Why?
Size. Focus. Lighting. Color.
Size. Mr. White (Harvey Keitel) on the right.
Focus. He’s one of the two objects in focus.
Lighting. Mr. White is large and in focus and Mr. Pink (Steve Buscemi) is highlighted by
a shaft of light.
Color. Both are black and white but the read on Mr. White’s shirt now really stands out.
(more…)
What type of lighting? -
Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacy
Read more: Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacynofilmschool.com/types-of-film-lights
“Not every light performs the same way. Lights and lighting are tricky to handle. You have to plan for every circumstance. But the good news is, lighting can be adjusted. Let’s look at different factors that affect lighting in every scene you shoot. “
Use CRI, Luminous Efficacy and color temperature controls to match your needs.
Color Temperature
Color temperature describes the “color” of white light by a light source radiated by a perfect black body at a given temperature measured in degrees Kelvinhttps://www.pixelsham.com/2019/10/18/color-temperature/
CRI
“The Color Rendering Index is a measurement of how faithfully a light source reveals the colors of whatever it illuminates, it describes the ability of a light source to reveal the color of an object, as compared to the color a natural light source would provide. The highest possible CRI is 100. A CRI of 100 generally refers to a perfect black body, like a tungsten light source or the sun. “https://www.studiobinder.com/blog/what-is-color-rendering-index
(more…) -
Virtual Production volumes study
Read more: Virtual Production volumes studyColor Fidelity in LED Volumes
https://theasc.com/articles/color-fidelity-in-led-volumes
Virtual Production Glossary
https://vpglossary.com/What is Virtual Production – In depth analysis
https://www.leadingledtech.com/what-is-a-led-virtual-production-studio-in-depth-technical-analysis/
A comparison of LED panels for use in Virtual Production:
Findings and recommendations
https://eprints.bournemouth.ac.uk/36826/1/LED_Comparison_White_Paper%281%29.pdf -
Polarised vs unpolarized filtering
Read more: Polarised vs unpolarized filteringA light wave that is vibrating in more than one plane is referred to as unpolarized light. …
Polarized light waves are light waves in which the vibrations occur in a single plane. The process of transforming unpolarized light into polarized light is known as polarization.

en.wikipedia.org/wiki/Polarizing_filter_(photography)
The most common use of polarized technology is to reduce lighting complexity on the subject.
(more…)
Details such as glare and hard edges are not removed, but greatly reduced.












LIGHTING
-
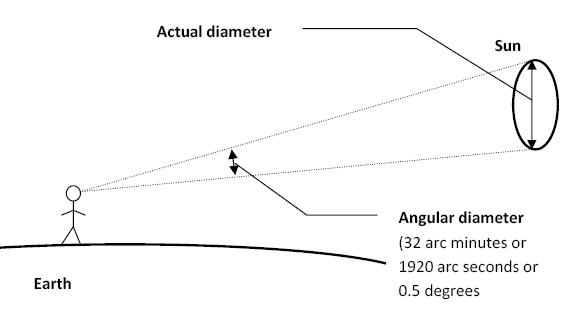
Sun cone angle (angular diameter) as perceived by earth viewers
Read more: Sun cone angle (angular diameter) as perceived by earth viewersAlso see:
https://www.pixelsham.com/2020/08/01/solid-angle-measures/
The cone angle of the sun refers to the angular diameter of the sun as observed from Earth, which is related to the apparent size of the sun in the sky.
The angular diameter of the sun, or the cone angle of the sunlight as perceived from Earth, is approximately 0.53 degrees on average. This value can vary slightly due to the elliptical nature of Earth’s orbit around the sun, but it generally stays within a narrow range.
Here’s a more precise breakdown:
-
- Average Angular Diameter: About 0.53 degrees (31 arcminutes)
- Minimum Angular Diameter: Approximately 0.52 degrees (when Earth is at aphelion, the farthest point from the sun)
- Maximum Angular Diameter: Approximately 0.54 degrees (when Earth is at perihelion, the closest point to the sun)
This angular diameter remains relatively constant throughout the day because the sun’s distance from Earth does not change significantly over a single day.
To summarize, the cone angle of the sun’s light, or its angular diameter, is typically around 0.53 degrees, regardless of the time of day.
https://en.wikipedia.org/wiki/Angular_diameter
-
-
Free HDRI libraries
Read more: Free HDRI librariesnoahwitchell.com
http://www.noahwitchell.com/freebieslocationtextures.com
https://locationtextures.com/panoramas/maxroz.com
https://www.maxroz.com/hdri/listHDRI Haven
https://hdrihaven.com/Poly Haven
https://polyhaven.com/hdrisDomeble
https://www.domeble.com/IHDRI
https://www.ihdri.com/HDRMaps
https://hdrmaps.com/NoEmotionHdrs.net
http://noemotionhdrs.net/hdrday.htmlOpenFootage.net
https://www.openfootage.net/hdri-panorama/HDRI-hub
https://www.hdri-hub.com/hdrishop/hdri.zwischendrin
https://www.zwischendrin.com/en/browse/hdriLonger list here:
https://cgtricks.com/list-sites-free-hdri/





















COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
N8N.io – From Zero to Your First AI Agent in 25 Minutes
-
What Is The Resolution and view coverage Of The human Eye. And what distance is TV at best?
-
Decart AI Mirage – The first ever World Transformation Model – turning any video, game, or camera feed into a new digital world, in real time
-
Generative AI Glossary / AI Dictionary / AI Terminology
-
Eddie Yoon – There’s a big misconception about AI creative
-
Top 3D Printing Website Resources
-
ComfyUI FLOAT – A container for FLOAT Generative Motion Latent Flow Matching for Audio-driven Talking Portrait – lip sync
-
Free fonts
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
