ACES 2.0 is the second major release of the components that make up the ACES system. The most significant change is a new suite of rendering transforms whose design was informed by collected feedback and requests from users of ACES 1. The changes aim to improve the appearance of perceived artifacts and to complete previously unfinished components of the system, resulting in a more complete, robust, and consistent product.
Highlights of the key changes in ACES 2.0 are as follows:
New output transforms, including:
A less aggressive tone scale
More intuitive controls to create custom outputs to non-standard displays
Robust gamut mapping to improve perceptual uniformity
Improved performance of the inverse transforms
Enhanced AMF specification
An updated specification for ACES Transform IDs
OpenEXR compression recommendations
Enhanced tools for generating Input Transforms and recommended procedures for characterizing prosumer cameras
Look Transform Library
Expanded documentation
Rendering Transform
The most substantial change in ACES 2.0 is a complete redesign of the rendering transform.
ACES 2.0 was built as a unified system, rather than through piecemeal additions. Different deliverable outputs “match” better and making outputs to display setups other than the provided presets is intended to be user-driven. The rendering transforms are less likely to produce undesirable artifacts “out of the box”, which means less time can be spent fixing problematic images and more time making pictures look the way you want.
Key design goals
Improve consistency of tone scale and provide an easy to use parameter to allow for outputs between preset dynamic ranges
Minimize hue skews across exposure range in a region of same hue
Unify for structural consistency across transform type
Easy to use parameters to create outputs other than the presets
Robust gamut mapping to improve harsh clipping artifacts
Fill extents of output code value cube (where appropriate and expected)
Invertible – not necessarily reversible, but Output > ACES > Output round-trip should be possible
Accomplish all of the above while maintaining an acceptable “out-of-the box” rendering
A LUT (Lookup Table) is essentially the modifier between two images, the original image and the displayed image, based on a mathematical formula. Basically conversion matrices of different complexities. There are different types of LUTS – viewing, transform, calibration, 1D and 3D.
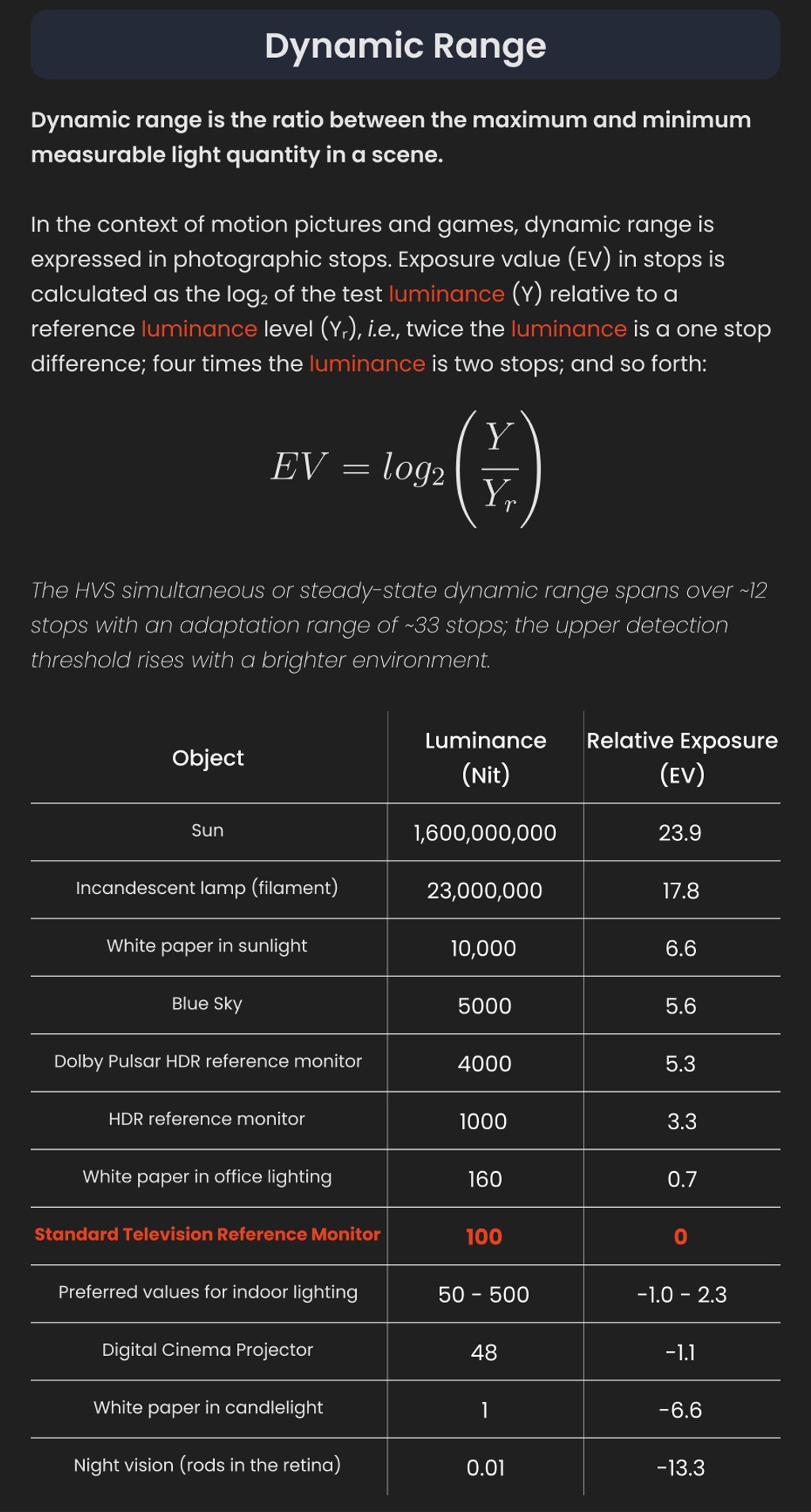
In color technology, color depth also known as bit depth, is either the number of bits used to indicate the color of a single pixel, OR the number of bits used for each color component of a single pixel.
When referring to a pixel, the concept can be defined as bits per pixel (bpp).
When referring to a color component, the concept can be defined as bits per component, bits per channel, bits per color (all three abbreviated bpc), and also bits per pixel component, bits per color channel or bits per sample (bps). Modern standards tend to use bits per component, but historical lower-depth systems used bits per pixel more often.
Color depth is only one aspect of color representation, expressing the precision with which the amount of each primary can be expressed; the other aspect is how broad a range of colors can be expressed (the gamut). The definition of both color precision and gamut is accomplished with a color encoding specification which assigns a digital code value to a location in a color space.
Most software around us today are decent at accurately displaying colors. Processing of colors is another story unfortunately, and is often done badly.
To understand what the problem is, let’s start with an example of three ways of blending green and magenta:
Perceptual blend – A smooth transition using a model designed to mimic human perception of color. The blending is done so that the perceived brightness and color varies smoothly and evenly.
Linear blend – A model for blending color based on how light behaves physically. This type of blending can occur in many ways naturally, for example when colors are blended together by focus blur in a camera or when viewing a pattern of two colors at a distance.
sRGB blend – This is how colors would normally be blended in computer software, using sRGB to represent the colors.
Let’s look at some more examples of blending of colors, to see how these problems surface more practically. The examples use strong colors since then the differences are more pronounced. This is using the same three ways of blending colors as the first example.
Instead of making it as easy as possible to work with color, most software make it unnecessarily hard, by doing image processing with representations not designed for it. Approximating the physical behavior of light with linear RGB models is one easy thing to do, but more work is needed to create image representations tailored for image processing and human perception.
A number of problems in computer vision and related fields would be mitigated if camera spectral sensitivities were known. As consumer cameras are not designed for high-precision visual tasks, manufacturers do not disclose spectral sensitivities. Their estimation requires a costly optical setup, which triggered researchers to come up with numerous indirect methods that aim to lower cost and complexity by using color targets. However, the use of color targets gives rise to new complications that make the estimation more difficult, and consequently, there currently exists no simple, low-cost, robust go-to method for spectral sensitivity estimation that non-specialized research labs can adopt. Furthermore, even if not limited by hardware or cost, researchers frequently work with imagery from multiple cameras that they do not have in their possession.
To provide a practical solution to this problem, we propose a framework for spectral sensitivity estimation that not only does not require any hardware (including a color target), but also does not require physical access to the camera itself. Similar to other work, we formulate an optimization problem that minimizes a two-term objective function: a camera-specific term from a system of equations, and a universal term that bounds the solution space.
Different than other work, we utilize publicly available high-quality calibration data to construct both terms. We use the colorimetric mapping matrices provided by the Adobe DNG Converter to formulate the camera-specific system of equations, and constrain the solutions using an autoencoder trained on a database of ground-truth curves. On average, we achieve reconstruction errors as low as those that can arise due to manufacturing imperfections between two copies of the same camera. We provide predicted sensitivities for more than 1,000 cameras that the Adobe DNG Converter currently supports, and discuss which tasks can become trivial when camera responses are available.
The 2011 Best Illusion of the Year uses motion to render color changes invisible, and so reveals a quirk in our visual systems that is new to scientists.
“It is a really beautiful effect, revealing something about how our visual system works that we didn’t know before,” said Daniel Simons, a professor at the University of Illinois, Champaign-Urbana. Simons studies visual cognition, and did not work on this illusion. Before its creation, scientists didn’t know that motion had this effect on perception, Simons said.
A viewer stares at a speck at the center of a ring of colored dots, which continuously change color. When the ring begins to rotate around the speck, the color changes appear to stop. But this is an illusion. For some reason, the motion causes our visual system to ignore the color changes. (You can, however, see the color changes if you follow the rotating circles with your eyes.)
An open, Interactive 3D Design Collaboration Platform for Multi-Tool Workflows to simplify studio workflows for real-time graphics.
It supports Pixar’s Universal Scene Description technology for exchanging information about modeling, shading, animation, lighting, visual effects and rendering across multiple applications.
It also supports NVIDIA’s Material Definition Language, which allows artists to exchange information about surface materials across multiple tools.
With Omniverse, artists can see live updates made by other artists working in different applications. They can also see changes reflected in multiple tools at the same time.
For example an artist using Maya with a portal to Omniverse can collaborate with another artist using UE4 and both will see live updates of each others’ changes in their application.
The intricate relationship between the eyes and the brain, often termed the eye-mind connection, reveals that vision is predominantly a cognitive process. This understanding has profound implications for fields such as design, where capturing and maintaining attention is paramount. This essay delves into the nuances of visual perception, the brain’s role in interpreting visual data, and how this knowledge can be applied to effective design strategies.
This cognitive aspect of vision is evident in phenomena such as optical illusions, where the brain interprets visual information in a way that contradicts physical reality. These illusions underscore that what we “see” is not merely a direct recording of the external world but a constructed experience shaped by cognitive processes.
Understanding the cognitive nature of vision is crucial for effective design. Designers must consider how the brain processes visual information to create compelling and engaging visuals. This involves several key principles:
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.