To measure the contrast ratio you will need a light meter. The process starts with you measuring the main source of light, or the key light.
Get a reading from the brightest area on the face of your subject. Then, measure the area lit by the secondary light, or fill light. To make sense of what you have just measured you have to understand that the information you have just gathered is in F-stops, a measure of light. With each additional F-stop, for example going one stop from f/1.4 to f/2.0, you create a doubling of light. The reverse is also true; moving one stop from f/8.0 to f/5.6 results in a halving of the light.
“Not every light performs the same way. Lights and lighting are tricky to handle. You have to plan for every circumstance. But the good news is, lighting can be adjusted. Let’s look at different factors that affect lighting in every scene you shoot. “
Use CRI, Luminous Efficacy and color temperature controls to match your needs.
Color Temperature Color temperature describes the “color” of white light by a light source radiated by a perfect black body at a given temperature measured in degrees Kelvin
CRI “The Color Rendering Index is a measurement of how faithfully a light source reveals the colors of whatever it illuminates, it describes the ability of a light source to reveal the color of an object, as compared to the color a natural light source would provide. The highest possible CRI is 100. A CRI of 100 generally refers to a perfect black body, like a tungsten light source or the sun. “
Depth of field is the range within which focusing is resolved in a photo.
Aperture has a huge affect on to the depth of field.
Changing the f-stops (f/#) of a lens will change aperture and as such the DOF.
f-stops are a just certain number which is telling you the size of the aperture. That’s how f-stop is related to aperture (and DOF).
If you increase f-stops, it will increase DOF, the area in focus (and decrease the aperture). On the other hand, decreasing the f-stop it will decrease DOF (and increase the aperture).
The red cone in the figure is an angular representation of the resolution of the system. Versus the dotted lines, which indicate the aperture coverage. Where the lines of the two cones intersect defines the total range of the depth of field.
This image explains why the longer the depth of field, the greater the range of clarity.
Disco Diffusion (DD) is a Google Colab Notebook which leverages an AI Image generating technique called CLIP-Guided Diffusion to allow you to create compelling and beautiful images from just text inputs. Created by Somnai, augmented by Gandamu, and building on the work of RiversHaveWings, nshepperd, and many others.
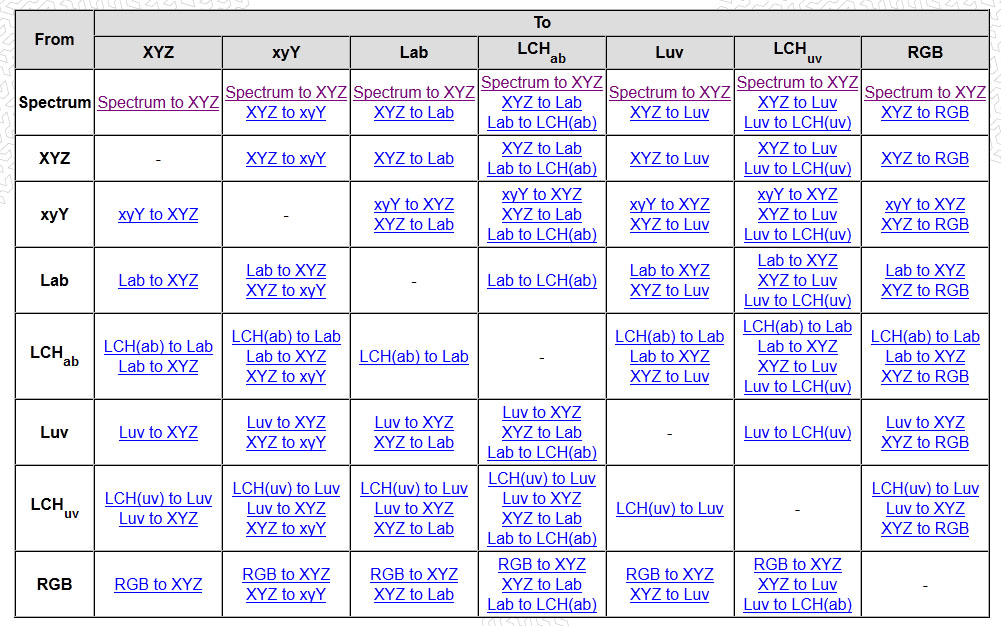
In HD we often refer to the range of available colors as a color gamut. Such a color gamut is typically plotted on a two-dimensional diagram, called a CIE chart, as shown in at the top of this blog. Each color is characterized by its x/y coordinates.
Good enough for government work, perhaps. But for HDR, with its higher luminance levels and wider color, the gamut becomes three-dimensional.
For HDR the color gamut therefore becomes a characteristic we now call the color volume. It isn’t easy to show color volume on a two-dimensional medium like the printed page or a computer screen, but one method is shown below. As the luminance becomes higher, the picture eventually turns to white. As it becomes darker, it fades to black. The traditional color gamut shown on the CIE chart is simply a slice through this color volume at a selected luminance level, such as 50%.
Three different color volumes—we still refer to them as color gamuts though their third dimension is important—are currently the most significant. The first is BT.709 (sometimes referred to as Rec.709), the color gamut used for pre-UHD/HDR formats, including standard HD.
The largest is known as BT.2020; it encompasses (roughly) the range of colors visible to the human eye (though ET might find it insufficient!).
Between these two is the color gamut used in digital cinema, known as DCI-P3.
About 576 megapixels for the entire field of view.
Consider a view in front of you that is 90 degrees by 90 degrees, like looking through an open window at a scene. The number of pixels would be:
90 degrees * 60 arc-minutes/degree * 1/0.3 * 90 * 60 * 1/0.3 = 324,000,000 pixels (324 megapixels).
At any one moment, you actually do not perceive that many pixels, but your eye moves around the scene to see all the detail you want. But the human eye really sees a larger field of view, close to 180 degrees. Let’s be conservative and use 120 degrees for the field of view. Then we would see:
One problem with sRGB is that in a gradient between blue and white, it becomes a bit purple in the middle of the transition. That’s because sRGB really isn’t created to mimic how the eye sees colors; rather, it is based on how CRT monitors work. That means it works with certain frequencies of red, green, and blue, and also the non-linear coding called gamma. It’s a miracle it works as well as it does, but it’s not connected to color perception. When using those tools, you sometimes get surprising results, like purple in the gradient.
There were also attempts to create simple models matching human perception based on XYZ, but as it turned out, it’s not possible to model all color vision that way. Perception of color is incredibly complex and depends, among other things, on whether it is dark or light in the room and the background color it is against. When you look at a photograph, it also depends on what you think the color of the light source is. The dress is a typical example of color vision being very context-dependent. It is almost impossible to model this perfectly.
I based Oklab on two other color spaces, CIECAM16 and IPT. I used the lightness and saturation prediction from CIECAM16, which is a color appearance model, as a target. I actually wanted to use the datasets used to create CIECAM16, but I couldn’t find them.
IPT was designed to have better hue uniformity. In experiments, they asked people to match light and dark colors, saturated and unsaturated colors, which resulted in a dataset for which colors, subjectively, have the same hue. IPT has a few other issues but is the basis for hue in Oklab.
In the Munsell color system, colors are described with three parameters, designed to match the perceived appearance of colors: Hue, Chroma and Value. The parameters are designed to be independent and each have a uniform scale. This results in a color solid with an irregular shape. The parameters are designed to be independent and each have a uniform scale. This results in a color solid with an irregular shape. Modern color spaces and models, such as CIELAB, Cam16 and Björn Ottosson own Oklab, are very similar in their construction.
By far the most used color spaces today for color picking are HSL and HSV, two representations introduced in the classic 1978 paper “Color Spaces for Computer Graphics”. HSL and HSV designed to roughly correlate with perceptual color properties while being very simple and cheap to compute.
Today HSL and HSV are most commonly used together with the sRGB color space.
One of the main advantages of HSL and HSV over the different Lab color spaces is that they map the sRGB gamut to a cylinder. This makes them easy to use since all parameters can be changed independently, without the risk of creating colors outside of the target gamut.
The main drawback on the other hand is that their properties don’t match human perception particularly well.
Reconciling these conflicting goals perfectly isn’t possible, but given that HSV and HSL don’t use anything derived from experiments relating to human perception, creating something that makes a better tradeoff does not seem unreasonable.
With this new lightness estimate, we are ready to look into the construction of Okhsv and Okhsl.
Most software around us today are decent at accurately displaying colors. Processing of colors is another story unfortunately, and is often done badly.
To understand what the problem is, let’s start with an example of three ways of blending green and magenta:
Perceptual blend – A smooth transition using a model designed to mimic human perception of color. The blending is done so that the perceived brightness and color varies smoothly and evenly.
Linear blend – A model for blending color based on how light behaves physically. This type of blending can occur in many ways naturally, for example when colors are blended together by focus blur in a camera or when viewing a pattern of two colors at a distance.
sRGB blend – This is how colors would normally be blended in computer software, using sRGB to represent the colors.
Let’s look at some more examples of blending of colors, to see how these problems surface more practically. The examples use strong colors since then the differences are more pronounced. This is using the same three ways of blending colors as the first example.
Instead of making it as easy as possible to work with color, most software make it unnecessarily hard, by doing image processing with representations not designed for it. Approximating the physical behavior of light with linear RGB models is one easy thing to do, but more work is needed to create image representations tailored for image processing and human perception.
Black-body radiation is the type of electromagnetic radiation within or surrounding a body in thermodynamic equilibrium with its environment, or emitted by a black body (an opaque and non-reflective body) held at constant, uniform temperature. The radiation has a specific spectrum and intensity that depends only on the temperature of the body.
A black-body at room temperature appears black, as most of the energy it radiates is infra-red and cannot be perceived by the human eye. At higher temperatures, black bodies glow with increasing intensity and colors that range from dull red to blindingly brilliant blue-white as the temperature increases.
OLED stands for Organic Light Emitting Diode. Each pixel in an OLED display is made of a material that glows when you jab it with electricity. Kind of like the heating elements in a toaster, but with less heat and better resolution. This effect is called electroluminescence, which is one of those delightful words that is big, but actually makes sense: “electro” for electricity, “lumin” for light and “escence” for, well, basically “essence.”
OLED TV marketing often claims “infinite” contrast ratios, and while that might sound like typical hyperbole, it’s one of the extremely rare instances where such claims are actually true. Since OLED can produce a perfect black, emitting no light whatsoever, its contrast ratio (expressed as the brightest white divided by the darkest black) is technically infinite.
OLED is the only technology capable of absolute blacks and extremely bright whites on a per-pixel basis. LCD definitely can’t do that, and even the vaunted, beloved, dearly departed plasma couldn’t do absolute blacks.
Chroma Key Green, the color of green screens is also known as Chroma Green and is valued at approximately 354C in the Pantone color matching system (PMS).
Chroma Green can be broken down in many different ways. Here is green screen green as other values useful for both physical and digital production:
Green Screen as RGB Color Value: 0, 177, 64
Green Screen as CMYK Color Value: 81, 0, 92, 0
Green Screen as Hex Color Value: #00b140
Green Screen as Websafe Color Value: #009933
Chroma Key Green is reasonably close to an 18% gray reflectance.
Illuminate your green screen with an uniform source with less than 2/3 EV variation.
The level of brightness at any given f-stop should be equivalent to a 90% white card under the same lighting.
Artificial light sources, not unlike the diverse phases of natural light, vary considerably in their properties. As a result, some lamps render an object’s color better than others do.
The most important criterion for assessing the color-rendering ability of any lamp is its spectral power distribution curve.
Natural daylight varies too much in strength and spectral composition to be taken seriously as a lighting standard for grading and dealing colored stones. For anything to be a standard, it must be constant in its properties, which natural light is not.
For dealers in particular to make the transition from natural light to an artificial light source, that source must offer:
1- A degree of illuminance at least as strong as the common phases of natural daylight.
2- Spectral properties identical or comparable to a phase of natural daylight.
A source combining these two things makes gems appear much the same as when viewed under a given phase of natural light. From the viewpoint of many dealers, this corresponds to a naturalappearance.
The 6000° Kelvin xenon short-arc lamp appears closest to meeting the criteria for a standard light source. Besides the strong illuminance this lamp affords, its spectrum is very similar to CIE standard illuminants of similar color temperature.
In photography, exposure value (EV) is a number that represents a combination of a camera’s shutter speed and f-number, such that all combinations that yield the same exposure have the same EV (for any fixed scene luminance).
The EV concept was developed in an attempt to simplify choosing among combinations of equivalent camera settings. Although all camera settings with the same EV nominally give the same exposure, they do not necessarily give the same picture. EV is also used to indicate an interval on the photographic exposure scale. 1 EV corresponding to a standard power-of-2 exposure step, commonly referred to as a stop
EV 0 corresponds to an exposure time of 1 sec and a relative aperture of f/1.0. If the EV is known, it can be used to select combinations of exposure time and f-number.
Note EV does not equal to photographic exposure. Photographic Exposureis defined as how much light hits the camera’s sensor. It depends on the camera settings mainly aperture and shutter speed. Exposure value (known as EV) is a number that represents theexposure setting of the camera.
Thus, strictly, EV is not a measure of luminance (indirect or reflected exposure) or illuminance (incidentl exposure); rather, an EV corresponds to a luminance (or illuminance) for which a camera with a given ISO speed would use the indicated EV to obtain the nominally correct exposure. Nonetheless, it is common practice among photographic equipment manufacturers to express luminance in EV for ISO 100 speed, as when specifying metering range or autofocus sensitivity.
The exposure depends on two things: how much light gets through the lenses to the camera’s sensor and for how long the sensor is exposed. The former is a function of the aperture value while the latter is a function of the shutter speed. Exposure value is a number that represents this potential amount of light that could hit the sensor. It is important to understand that exposure value is a measure of how exposed the sensor is to light and not a measure of how much light actually hits the sensor. The exposure value is independent of how lit the scene is. For example a pair of aperture value and shutter speed represents the same exposure value both if the camera is used during a very bright day or during a dark night.
Each exposure value number represents all the possible shutter and aperture settings that result in the same exposure. Although the exposure value is the same for different combinations of aperture values and shutter speeds the resulting photo can be very different (the aperture controls the depth of field while shutter speed controls how much motion is captured).
EV 0.0 is defined as the exposure when setting the aperture to f-number 1.0 and the shutter speed to 1 second. All other exposure values are relative to that number. Exposure values are on a base two logarithmic scale. This means that every single step of EV – plus or minus 1 – represents the exposure (actual light that hits the sensor) being halved or doubled.
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.



















































































 Local copy:
Local copy:

















{kind=link}
