By stimulating specific cells in the retina, the participants claim to have witnessed a blue-green colour that scientists have called “olo”, but some experts have said the existence of a new colour is “open to argument”.
The findings, published in the journal Science Advances on Friday, have been described by the study’s co-author, Prof Ren Ng from the University of California, as “remarkable”.
(A) System inputs. (i) Retina map of 103 cone cells preclassified by spectral type (7). (ii) Target visual percept (here, a video of a child, see movie S1 at 1:04). (iii) Infrared cellular-scale imaging of the retina with 60-frames-per-second rolling shutter. Fixational eye movement is visible over the three frames shown.
(B) System outputs. (iv) Real-time per-cone target activation levels to reproduce the target percept, computed by: extracting eye motion from the input video relative to the retina map; identifying the spectral type of every cone in the field of view; computing the per-cone activation the target percept would have produced. (v) Intensities of visible-wavelength 488-nm laser microdoses at each cone required to achieve its target activation level.
(C) Infrared imaging and visible-wavelength stimulation are physically accomplished in a raster scan across the retinal region using AOSLO. By modulating the visible-wavelength beam’s intensity, the laser microdoses shown in (v) are delivered. Drawing adapted with permission [Harmening and Sincich (54)].
(D) Examples of target percepts with corresponding cone activations and laser microdoses, ranging from colored squares to complex imagery. Teal-striped regions represent the color “olo” of stimulating only M cones.
The goals of lighting in 3D computer graphics are more or less the same as those of real world lighting.
Lighting serves a basic function of bringing out, or pushing back the shapes of objects visible from the camera’s view.
It gives a two-dimensional image on the monitor an illusion of the third dimension-depth.
But it does not just stop there. It gives an image its personality, its character. A scene lit in different ways can give a feeling of happiness, of sorrow, of fear etc., and it can do so in dramatic or subtle ways. Along with personality and character, lighting fills a scene with emotion that is directly transmitted to the viewer.
Trying to simulate a real environment in an artificial one can be a daunting task. But even if you make your 3D rendering look absolutely photo-realistic, it doesn’t guarantee that the image carries enough emotion to elicit a “wow” from the people viewing it.
Making 3D renderings photo-realistic can be hard. Putting deep emotions in them can be even harder. However, if you plan out your lighting strategy for the mood and emotion that you want your rendering to express, you make the process easier for yourself.
Each light source can be broken down in to 4 distinct components and analyzed accordingly.
· Intensity
· Direction
· Color
· Size
The overall thrust of this writing is to produce photo-realistic images by applying good lighting techniques.
Supported by LG, Philips, Panasonic and Sony sell the OLED system TVs. OLED stands for “organic light emitting diode.” It is a fundamentally different technology from LCD, the major type of TV today. OLED is “emissive,” meaning the pixels emit their own light.
Samsung is branding its best TVs with a new acronym: “QLED” QLED (according to Samsung) stands for “quantum dot LED TV.” It is a variation of the common LED LCD, adding a quantum dot film to the LCD “sandwich.” QLED, like LCD, is, in its current form, “transmissive” and relies on an LED backlight.
OLED is the only technology capable of absolute blacks and extremely bright whites on a per-pixel basis. LCD definitely can’t do that, and even the vaunted, beloved, dearly departed plasma couldn’t do absolute blacks.
QLED, as an improvement over OLED, significantly improves the picture quality. QLED can produce an even wider range of colors than OLED, which says something about this new tech. QLED is also known to produce up to 40% higher luminance efficiency than OLED technology. Further, many tests conclude that QLED is far more efficient in terms of power consumption than its predecessor, OLED.
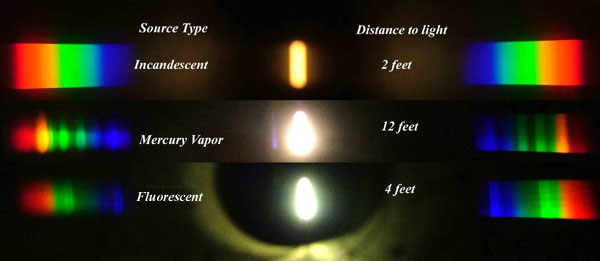
This help’s us understand the composition of components in/on solar system bodies.
Dips in the observed light spectrum, also known as, lines of absorption occur as gasses absorb energy from light at specific points along the light spectrum.
These dips or darkened zones (lines of absorption) leave a finger print which identify elements and compounds.
In this image the dark absorption bands appear as lines of emission which occur as the result of emitted not reflected (absorbed) light.
“Not every light performs the same way. Lights and lighting are tricky to handle. You have to plan for every circumstance. But the good news is, lighting can be adjusted. Let’s look at different factors that affect lighting in every scene you shoot. “
Use CRI, Luminous Efficacy and color temperature controls to match your needs.
Color Temperature Color temperature describes the “color” of white light by a light source radiated by a perfect black body at a given temperature measured in degrees Kelvin
CRI “The Color Rendering Index is a measurement of how faithfully a light source reveals the colors of whatever it illuminates, it describes the ability of a light source to reveal the color of an object, as compared to the color a natural light source would provide. The highest possible CRI is 100. A CRI of 100 generally refers to a perfect black body, like a tungsten light source or the sun. “
An exposure stop is a unit measurement of Exposure as such it provides a universal linear scale to measure the increase and decrease in light, exposed to the image sensor, due to changes in shutter speed, iso and f-stop.
+-1 stop is a doubling or halving of the amount of light let in when taking a photo
1 EV (exposure value) is just another way to say one stop of exposure change.
Same applies to shutter speed, iso and aperture.
Doubling or halving your shutter speed produces an increase or decrease of 1 stop of exposure.
Doubling or halving your iso speed produces an increase or decrease of 1 stop of exposure.
LightIt is a script for Maya and Arnold that will help you and improve your lighting workflow.
Thanks to preset studio lighting components (lights, backdrop…), high quality studio scenes and HDRI library manager.
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.


























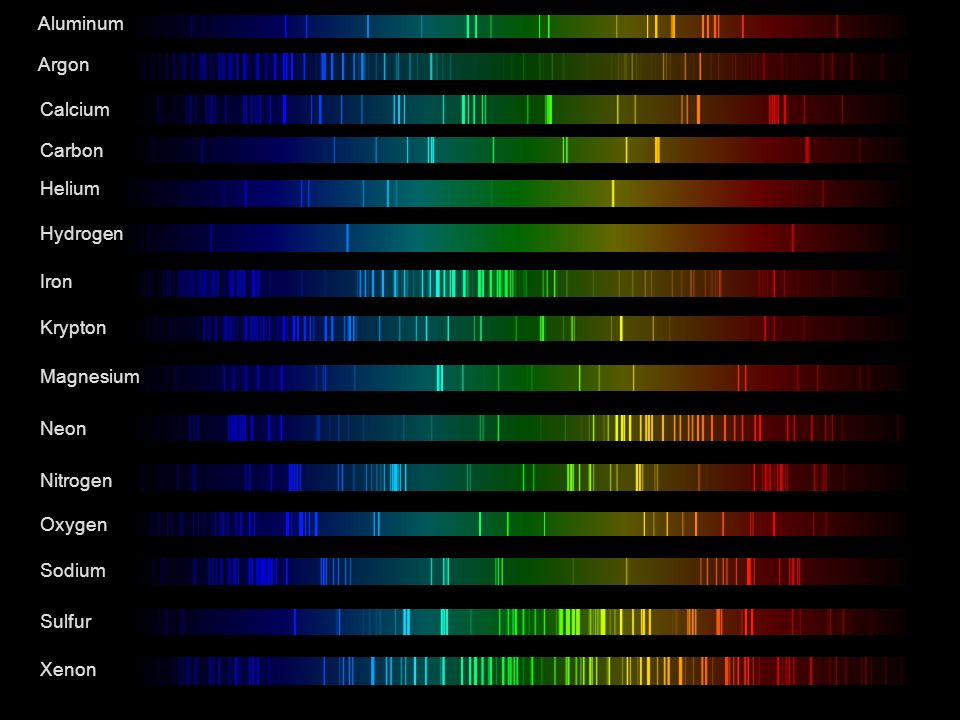 Lines of emission
Lines of emission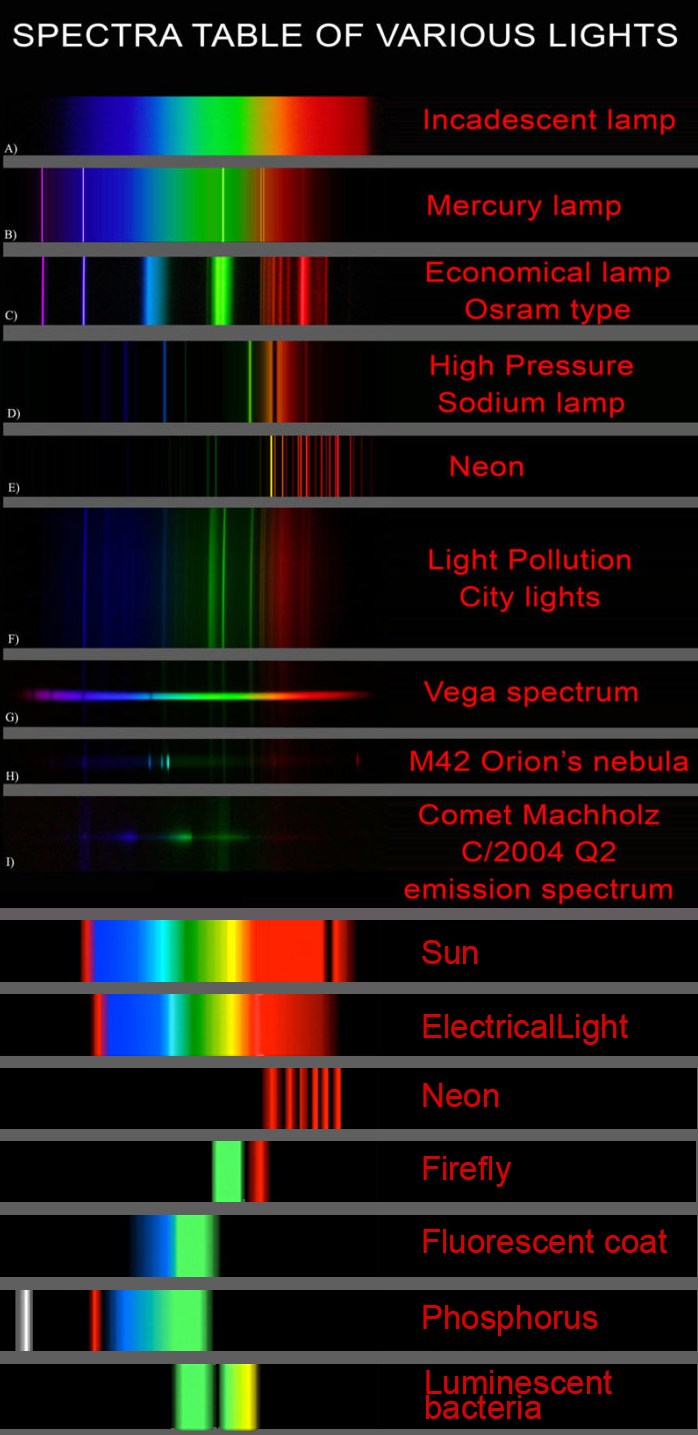




















![[gamma correction test]](http://www.madore.org/~david/misc/color/gammatest.png "sRGB gamma correction test")








