About 576 megapixels for the entire field of view.
Consider a view in front of you that is 90 degrees by 90 degrees, like looking through an open window at a scene. The number of pixels would be:
90 degrees * 60 arc-minutes/degree * 1/0.3 * 90 * 60 * 1/0.3 = 324,000,000 pixels (324 megapixels).
At any one moment, you actually do not perceive that many pixels, but your eye moves around the scene to see all the detail you want. But the human eye really sees a larger field of view, close to 180 degrees. Let’s be conservative and use 120 degrees for the field of view. Then we would see:
Spectral sensitivity of eye is influenced by light intensity. And the light intensity determines the level of activity of cones cell and rod cell. This is the main characteristic of human vision. Sensitivity to individual colors, in other words, wavelengths of the light spectrum, is explained by the RGB (red-green-blue) theory. This theory assumed that there are three kinds of cones. It’s selectively sensitive to red (700-630 nm), green (560-500 nm), and blue (490-450 nm) light. And their mutual interaction allow to perceive all colors of the spectrum.
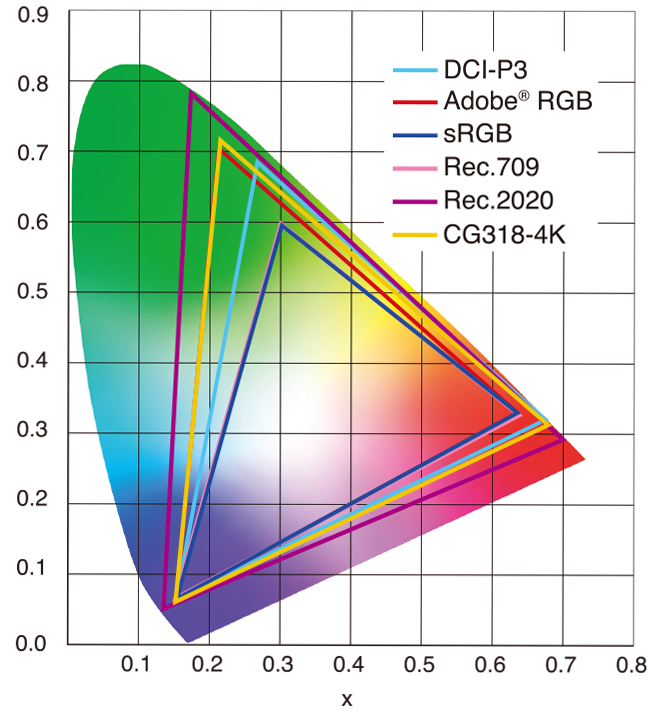
sRGB: A standard “web”/computer-display RGB color space defined by IEC 61966-2-1. It’s used for most monitors, cameras, printers, and the vast majority of images on the Internet.
Rec. 709: An HD-video color space defined by ITU-R BT.709. It’s the go-to standard for HDTV broadcasts, Blu-ray discs, and professional video pipelines.
Why they exist
sRGB: Ensures consistent colors across different consumer devices (PCs, phones, webcams).
Rec. 709: Ensures consistent colors across video production and playback chains (cameras → editing → broadcast → TV).
What you’ll see
On your desktop or phone, images tagged sRGB will look “right” without extra tweaking.
On an HDTV or video-editing timeline, footage tagged Rec. 709 will display accurate contrast and hue on broadcast-grade monitors.
A number of problems in computer vision and related fields would be mitigated if camera spectral sensitivities were known. As consumer cameras are not designed for high-precision visual tasks, manufacturers do not disclose spectral sensitivities. Their estimation requires a costly optical setup, which triggered researchers to come up with numerous indirect methods that aim to lower cost and complexity by using color targets. However, the use of color targets gives rise to new complications that make the estimation more difficult, and consequently, there currently exists no simple, low-cost, robust go-to method for spectral sensitivity estimation that non-specialized research labs can adopt. Furthermore, even if not limited by hardware or cost, researchers frequently work with imagery from multiple cameras that they do not have in their possession.
To provide a practical solution to this problem, we propose a framework for spectral sensitivity estimation that not only does not require any hardware (including a color target), but also does not require physical access to the camera itself. Similar to other work, we formulate an optimization problem that minimizes a two-term objective function: a camera-specific term from a system of equations, and a universal term that bounds the solution space.
Different than other work, we utilize publicly available high-quality calibration data to construct both terms. We use the colorimetric mapping matrices provided by the Adobe DNG Converter to formulate the camera-specific system of equations, and constrain the solutions using an autoencoder trained on a database of ground-truth curves. On average, we achieve reconstruction errors as low as those that can arise due to manufacturing imperfections between two copies of the same camera. We provide predicted sensitivities for more than 1,000 cameras that the Adobe DNG Converter currently supports, and discuss which tasks can become trivial when camera responses are available.
The human eye perceives half scene brightness not as the linear 50% of the present energy (linear nature values) but as 18% of the overall brightness. We are biased to perceive more information in the dark and contrast areas. A Macbeth chart helps with calibrating back into a photographic capture into this “human perspective” of the world.
In photography, painting, and other visual arts, middle gray or middle grey is a tone that is perceptually about halfway between black and white on a lightness scale in photography and printing, it is typically defined as 18% reflectance in visible light
Light meters, cameras, and pictures are often calibrated using an 18% gray card[4][5][6] or a color reference card such as a ColorChecker. On the assumption that 18% is similar to the average reflectance of a scene, a grey card can be used to estimate the required exposure of the film.
The primary goal of physically-based rendering (PBR) is to create a simulation that accurately reproduces the imaging process of electro-magnetic spectrum radiation incident to an observer. This simulation should be indistinguishable from reality for a similar observer.
Because a camera is not sensitive to incident light the same way than a human observer, the images it captures are transformed to be colorimetric. A project might require infrared imaging simulation, a portion of the electro-magnetic spectrum that is invisible to us. Radically different observers might image the same scene but the act of observing does not change the intrinsic properties of the objects being imaged. Consequently, the physical modelling of the virtual scene should be independent of the observer.
The dynamic range is a ratio between the maximum and minimum values of a physical measurement. Its definition depends on what the dynamic range refers to.
For a scene: Dynamic range is the ratio between the brightest and darkest parts of the scene.
For a camera: Dynamic range is the ratio of saturation to noise. More specifically, the ratio of the intensity that just saturates the camera to the intensity that just lifts the camera response one standard deviation above camera noise.
For a display: Dynamic range is the ratio between the maximum and minimum intensities emitted from the screen.
The Dynamic Range of real-world scenes can be quite high — ratios of 100,000:1 are common in the natural world. An HDR (High Dynamic Range) image stores pixel values that span the whole tonal range of real-world scenes. Therefore, an HDR image is encoded in a format that allows the largest range of values, e.g. floating-point values stored with 32 bits per color channel. Another characteristics of an HDR image is that it stores linear values. This means that the value of a pixel from an HDR image is proportional to the amount of light measured by the camera.
For TVs HDR is great, but it’s not the only new TV feature worth discussing.
To measure the contrast ratio you will need a light meter. The process starts with you measuring the main source of light, or the key light.
Get a reading from the brightest area on the face of your subject. Then, measure the area lit by the secondary light, or fill light. To make sense of what you have just measured you have to understand that the information you have just gathered is in F-stops, a measure of light. With each additional F-stop, for example going one stop from f/1.4 to f/2.0, you create a doubling of light. The reverse is also true; moving one stop from f/8.0 to f/5.6 results in a halving of the light.
import math,sys
def Exposure2Intensity(exposure):
exp = float(exposure)
result = math.pow(2,exp)
print(result)
Exposure2Intensity(0)
def Intensity2Exposure(intensity):
inarg = float(intensity)
if inarg == 0:
print("Exposure of zero intensity is undefined.")
return
if inarg < 1e-323:
inarg = max(inarg, 1e-323)
print("Exposure of negative intensities is undefined. Clamping to a very small value instead (1e-323)")
result = math.log(inarg, 2)
print(result)
Intensity2Exposure(0.1)
Why Exposure?
Exposure is a stop value that multiplies the intensity by 2 to the power of the stop. Increasing exposure by 1 results in double the amount of light.
Artists think in “stops.” Doubling or halving brightness is easy math and common in grading and look-dev. Exposure counts doublings in whole stops:
+1 stop = ×2 brightness
−1 stop = ×0.5 brightness
This gives perceptually even controls across both bright and dark values.
Why Intensity?
Intensity is linear. It’s what render engines and compositors expect when:
Summing values
Averaging pixels
Multiplying or filtering pixel data
Use intensity when you need the actual math on pixel/light data.
Formulas (from your Python)
Intensity from exposure: intensity = 2**exposure
Exposure from intensity: exposure = log₂(intensity)
Guardrails:
Intensity must be > 0 to compute exposure.
If intensity = 0 → exposure is undefined.
Clamp tiny values (e.g. 1e−323) before using log₂.
Use Exposure (stops) when…
You want artist-friendly sliders (−5…+5 stops)
Adjusting look-dev or grading in even stops
Matching plates with quick ±1 stop tweaks
Tweening brightness changes smoothly across ranges
Use Intensity (linear) when…
Storing raw pixel/light values
Multiplying textures or lights by a gain
Performing sums, averages, and filters
Feeding values to render engines expecting linear data
Examples
+2 stops → 2**2 = 4.0 (×4)
+1 stop → 2**1 = 2.0 (×2)
0 stop → 2**0 = 1.0 (×1)
−1 stop → 2**(−1) = 0.5 (×0.5)
−2 stops → 2**(−2) = 0.25 (×0.25)
Intensity 0.1 → exposure = log₂(0.1) ≈ −3.32
Rule of thumb
Think in stops (exposure) for controls and matching. Compute in linear (intensity) for rendering and math.
Note. The Median Cut algorithm is typically used for color quantization, which involves reducing the number of colors in an image while preserving its visual quality. It doesn’t directly provide a way to identify the brightest areas in an image. However, if you’re interested in identifying the brightest areas, you might want to look into other methods like thresholding, histogram analysis, or edge detection, through openCV for example.
The trigger phrase is “equirectangular 360 degree panorama”. I would avoid saying “spherical projection” since that tends to result in non-equirectangular spherical images.
Image resolution should always be a 2:1 aspect ratio. 1024 x 512 or 1408 x 704 work quite well and were used in the training data. 2048 x 1024 also works.
I suggest using a weight of 0.5 – 1.5. If you are having issues with the image generating too flat instead of having the necessary spherical distortion, try increasing the weight above 1, though this could negatively impact small details of the image. For Flux guidance, I recommend a value of about 2.5 for realistic scenes.
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.

















































{kind=link}
