Size. Mr. White (Harvey Keitel) on the right. Focus. He’s one of the two objects in focus. Lighting. Mr. White is large and in focus and Mr. Pink (Steve Buscemi) is highlighted by a shaft of light. Color. Both are black and white but the read on Mr. White’s shirt now really stands out.
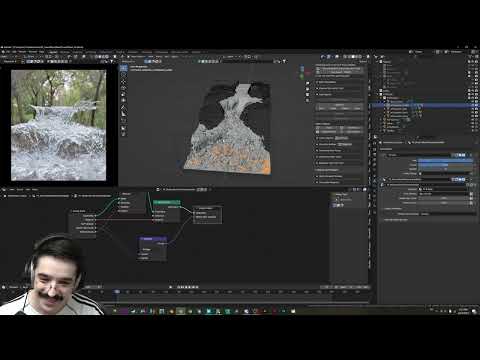
1. Watch every frame of raw footage twice. On the second time, take notes. If you don’t do this and try to start developing a scene premature, then it’s a big disservice to yourself and to the director, actors and production crew.
2. Nurture the relationships with the director. You are the secondary person in the relationship. Be calm and continually offer solutions. Get the main intention of the film as soon as possible from the director.
3. Organize your media so that you can find any shot instantly.
4. Factor in extra time for renders, exports, errors and crashes.
5. Attempt edits and ideas that shouldn’t work. It just might work. Until you do it and watch it, you won’t know. Don’t rule out ideas just because they don’t make sense in your mind.
6. Spend more time on your audio. It’s the glue of your edit. AUDIO SAVES EVERYTHING. Create fluid and seamless audio under your video.
7. Make cuts for the scene, but always in context for the whole film. Have a macro and a micro view at all times.
slowmoVideo is an OpenSource program that creates slow-motion videos from your footage.
Slow motion cinematography is the result of playing back frames for a longer duration than they were exposed. For example, if you expose 240 frames of film in one second, then play them back at 24 fps, the resulting movie is 10 times longer (slower) than the original filmed event….
Film cameras are relatively simple mechanical devices that allow you to crank up the speed to whatever rate the shutter and pull-down mechanism allow. Some film cameras can operate at 2,500 fps or higher (although film shot in these cameras often needs some readjustment in postproduction). Video, on the other hand, is always captured, recorded, and played back at a fixed rate, with a current limit around 60fps. This makes extreme slow motion effects harder to achieve (and less elegant) on video, because slowing down the video results in each frame held still on the screen for a long time, whereas with high-frame-rate film there are plenty of frames to fill the longer durations of time. On video, the slow motion effect is more like a slide show than smooth, continuous motion.
One obvious solution is to shoot film at high speed, then transfer it to video (a case where film still has a clear advantage, sorry George). Another possibility is to cross dissolve or blur from one frame to the next. This adds a smooth transition from one still frame to the next. The blur reduces the sharpness of the image, and compared to slowing down images shot at a high frame rate, this is somewhat of a cheat. However, there isn’t much you can do about it until video can be recorded at much higher rates. Of course, many film cameras can’t shoot at high frame rates either, so the whole super-slow-motion endeavor is somewhat specialized no matter what medium you are using. (There are some high speed digital cameras available now that allow you to capture lots of digital frames directly to your computer, so technology is starting to catch up with film. However, this feature isn’t going to appear in consumer camcorders any time soon.)
In the Illusion of Sex, two faces are perceived as male and female.
However, both faces are actually versions of the same androgynous face.
One face was created by increasing the contrast of the androgynous face, while the other face was created by decreasing the contrast. The face with more contrast is perceived as female, while the face with less contrast is perceived as male. The Illusion of Sex demonstrates that contrast is an important cue for perceiving the sex of a face, with greater contrast appearing feminine, and lesser contrast appearing masculine.
Russell, R. (2009) A sex difference in facial pigmentation and its exaggeration by cosmetics. Perception, (38)1211-1219.
In the retina, photoreceptors, bipolar cells, and horizontal cells work together to process visual information before it reaches the brain. Here’s how each cell type contributes to vision:
“Memory colors are colors that are universally associated with specific objects, elements or scenes in our environment. They are the colors that we expect to see in specific situations: these colors are based on our expectation of how certain objects should look based on our past experiences and memories.
For instance, we associate specific hues, saturation and brightness values with human skintones and a slight variation can significantly affect the way we perceive a scene.
Similarly, we expect blue skies to have a particular hue, green trees to be a specific shade and so on.
Memory colors live inside of our brains and we often impose them onto what we see. By considering them during the grading process, the resulting image will be more visually appealing and won’t distract the viewer from the intended message of the story. Even a slight deviation from memory colors in a movie can create a sense of discordance, ultimately detracting from the viewer’s experience.”
The goals of lighting in 3D computer graphics are more or less the same as those of real world lighting.
Lighting serves a basic function of bringing out, or pushing back the shapes of objects visible from the camera’s view.
It gives a two-dimensional image on the monitor an illusion of the third dimension-depth.
But it does not just stop there. It gives an image its personality, its character. A scene lit in different ways can give a feeling of happiness, of sorrow, of fear etc., and it can do so in dramatic or subtle ways. Along with personality and character, lighting fills a scene with emotion that is directly transmitted to the viewer.
Trying to simulate a real environment in an artificial one can be a daunting task. But even if you make your 3D rendering look absolutely photo-realistic, it doesn’t guarantee that the image carries enough emotion to elicit a “wow” from the people viewing it.
Making 3D renderings photo-realistic can be hard. Putting deep emotions in them can be even harder. However, if you plan out your lighting strategy for the mood and emotion that you want your rendering to express, you make the process easier for yourself.
Each light source can be broken down in to 4 distinct components and analyzed accordingly.
· Intensity
· Direction
· Color
· Size
The overall thrust of this writing is to produce photo-realistic images by applying good lighting techniques.
ACES 2.0 is the second major release of the components that make up the ACES system. The most significant change is a new suite of rendering transforms whose design was informed by collected feedback and requests from users of ACES 1. The changes aim to improve the appearance of perceived artifacts and to complete previously unfinished components of the system, resulting in a more complete, robust, and consistent product.
Highlights of the key changes in ACES 2.0 are as follows:
New output transforms, including:
A less aggressive tone scale
More intuitive controls to create custom outputs to non-standard displays
Robust gamut mapping to improve perceptual uniformity
Improved performance of the inverse transforms
Enhanced AMF specification
An updated specification for ACES Transform IDs
OpenEXR compression recommendations
Enhanced tools for generating Input Transforms and recommended procedures for characterizing prosumer cameras
Look Transform Library
Expanded documentation
Rendering Transform
The most substantial change in ACES 2.0 is a complete redesign of the rendering transform.
ACES 2.0 was built as a unified system, rather than through piecemeal additions. Different deliverable outputs “match” better and making outputs to display setups other than the provided presets is intended to be user-driven. The rendering transforms are less likely to produce undesirable artifacts “out of the box”, which means less time can be spent fixing problematic images and more time making pictures look the way you want.
Key design goals
Improve consistency of tone scale and provide an easy to use parameter to allow for outputs between preset dynamic ranges
Minimize hue skews across exposure range in a region of same hue
Unify for structural consistency across transform type
Easy to use parameters to create outputs other than the presets
Robust gamut mapping to improve harsh clipping artifacts
Fill extents of output code value cube (where appropriate and expected)
Invertible – not necessarily reversible, but Output > ACES > Output round-trip should be possible
Accomplish all of the above while maintaining an acceptable “out-of-the box” rendering
One problem with sRGB is that in a gradient between blue and white, it becomes a bit purple in the middle of the transition. That’s because sRGB really isn’t created to mimic how the eye sees colors; rather, it is based on how CRT monitors work. That means it works with certain frequencies of red, green, and blue, and also the non-linear coding called gamma. It’s a miracle it works as well as it does, but it’s not connected to color perception. When using those tools, you sometimes get surprising results, like purple in the gradient.
There were also attempts to create simple models matching human perception based on XYZ, but as it turned out, it’s not possible to model all color vision that way. Perception of color is incredibly complex and depends, among other things, on whether it is dark or light in the room and the background color it is against. When you look at a photograph, it also depends on what you think the color of the light source is. The dress is a typical example of color vision being very context-dependent. It is almost impossible to model this perfectly.
I based Oklab on two other color spaces, CIECAM16 and IPT. I used the lightness and saturation prediction from CIECAM16, which is a color appearance model, as a target. I actually wanted to use the datasets used to create CIECAM16, but I couldn’t find them.
IPT was designed to have better hue uniformity. In experiments, they asked people to match light and dark colors, saturated and unsaturated colors, which resulted in a dataset for which colors, subjectively, have the same hue. IPT has a few other issues but is the basis for hue in Oklab.
In the Munsell color system, colors are described with three parameters, designed to match the perceived appearance of colors: Hue, Chroma and Value. The parameters are designed to be independent and each have a uniform scale. This results in a color solid with an irregular shape. The parameters are designed to be independent and each have a uniform scale. This results in a color solid with an irregular shape. Modern color spaces and models, such as CIELAB, Cam16 and Björn Ottosson own Oklab, are very similar in their construction.
By far the most used color spaces today for color picking are HSL and HSV, two representations introduced in the classic 1978 paper “Color Spaces for Computer Graphics”. HSL and HSV designed to roughly correlate with perceptual color properties while being very simple and cheap to compute.
Today HSL and HSV are most commonly used together with the sRGB color space.
One of the main advantages of HSL and HSV over the different Lab color spaces is that they map the sRGB gamut to a cylinder. This makes them easy to use since all parameters can be changed independently, without the risk of creating colors outside of the target gamut.
The main drawback on the other hand is that their properties don’t match human perception particularly well.
Reconciling these conflicting goals perfectly isn’t possible, but given that HSV and HSL don’t use anything derived from experiments relating to human perception, creating something that makes a better tradeoff does not seem unreasonable.
With this new lightness estimate, we are ready to look into the construction of Okhsv and Okhsl.
The dynamic range is a ratio between the maximum and minimum values of a physical measurement. Its definition depends on what the dynamic range refers to.
For a scene: Dynamic range is the ratio between the brightest and darkest parts of the scene.
For a camera: Dynamic range is the ratio of saturation to noise. More specifically, the ratio of the intensity that just saturates the camera to the intensity that just lifts the camera response one standard deviation above camera noise.
For a display: Dynamic range is the ratio between the maximum and minimum intensities emitted from the screen.
The Dynamic Range of real-world scenes can be quite high — ratios of 100,000:1 are common in the natural world. An HDR (High Dynamic Range) image stores pixel values that span the whole tonal range of real-world scenes. Therefore, an HDR image is encoded in a format that allows the largest range of values, e.g. floating-point values stored with 32 bits per color channel. Another characteristics of an HDR image is that it stores linear values. This means that the value of a pixel from an HDR image is proportional to the amount of light measured by the camera.
For TVs HDR is great, but it’s not the only new TV feature worth discussing.
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.