


COMPOSITION
DESIGN
COLOR
-
THOMAS MANSENCAL – The Apparent Simplicity of RGB Rendering
Read more: THOMAS MANSENCAL – The Apparent Simplicity of RGB Rendering
https://thomasmansencal.substack.com/p/the-apparent-simplicity-of-rgb-rendering
The primary goal of physically-based rendering (PBR) is to create a simulation that accurately reproduces the imaging process of electro-magnetic spectrum radiation incident to an observer. This simulation should be indistinguishable from reality for a similar observer.
Because a camera is not sensitive to incident light the same way than a human observer, the images it captures are transformed to be colorimetric. A project might require infrared imaging simulation, a portion of the electro-magnetic spectrum that is invisible to us. Radically different observers might image the same scene but the act of observing does not change the intrinsic properties of the objects being imaged. Consequently, the physical modelling of the virtual scene should be independent of the observer.
-
No one could see the colour blue until modern times
Read more: No one could see the colour blue until modern timeshttps://www.businessinsider.com/what-is-blue-and-how-do-we-see-color-2015-2

The way humans see the world… until we have a way to describe something, even something so fundamental as a colour, we may not even notice that something it’s there.
Ancient languages didn’t have a word for blue — not Greek, not Chinese, not Japanese, not Hebrew, not Icelandic cultures. And without a word for the colour, there’s evidence that they may not have seen it at all.
https://www.wnycstudios.org/story/211119-colorsEvery language first had a word for black and for white, or dark and light. The next word for a colour to come into existence — in every language studied around the world — was red, the colour of blood and wine.
After red, historically, yellow appears, and later, green (though in a couple of languages, yellow and green switch places). The last of these colours to appear in every language is blue.The only ancient culture to develop a word for blue was the Egyptians — and as it happens, they were also the only culture that had a way to produce a blue dye.
https://mymodernmet.com/shades-of-blue-color-history/True blue hues are rare in the natural world because synthesizing pigments that absorb longer-wavelength light (reds and yellows) while reflecting shorter-wavelength blue light requires exceptionally elaborate molecular structures—biochemical feats that most plants and animals simply don’t undertake.
When you gaze at a blueberry’s deep blue surface, you’re actually seeing structural coloration rather than a true blue pigment. A fine, waxy bloom on the berry’s skin contains nanostructures that preferentially scatter blue and violet light, giving the fruit its signature blue sheen even though its inherent pigment is reddish.
Similarly, many of nature’s most striking blues—like those of blue jays and morpho butterflies—arise not from blue pigments but from microscopic architectures in feathers or wing scales. These tiny ridges and air pockets manipulate incoming light so that blue wavelengths emerge most prominently, creating vivid, angle-dependent colors through scattering rather than pigment alone.
(more…) -
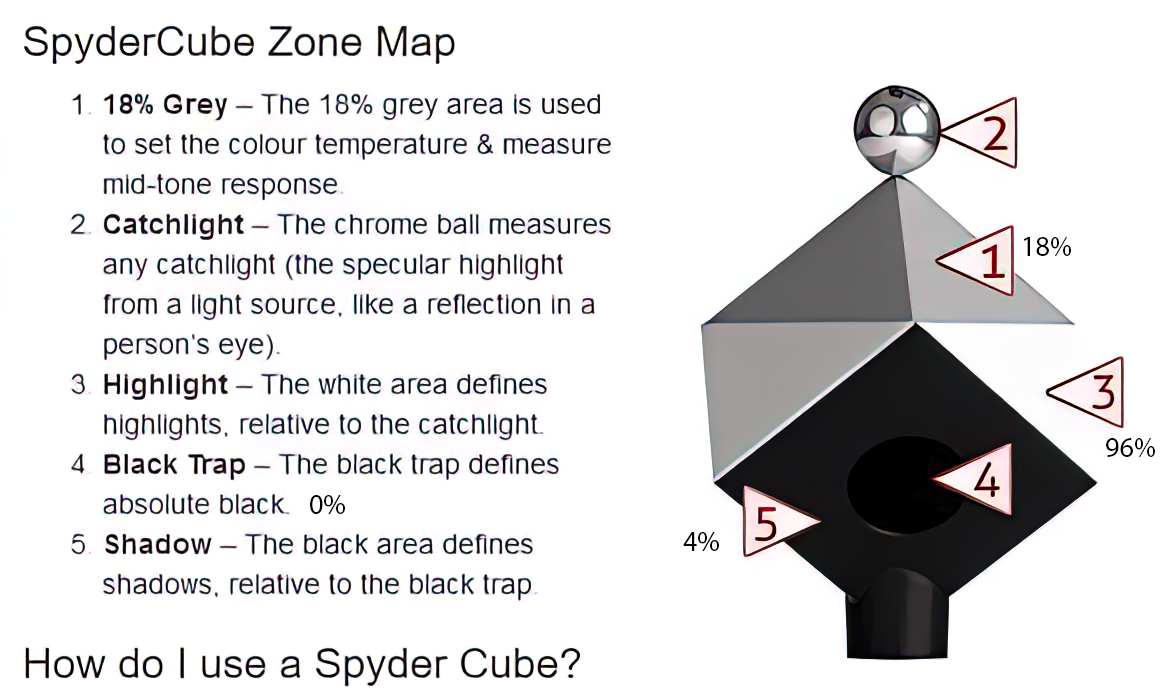
mmColorTarget – Nuke Gizmo for color matching a MacBeth chart
Read more: mmColorTarget – Nuke Gizmo for color matching a MacBeth charthttps://www.marcomeyer-vfx.de/posts/2014-04-11-mmcolortarget-nuke-gizmo/
https://www.marcomeyer-vfx.de/posts/mmcolortarget-nuke-gizmo/
https://vimeo.com/9.1652466e+07
https://www.nukepedia.com/gizmos/colour/mmcolortarget
-
Black Body color aka the Planckian Locus curve for white point eye perception
Read more: Black Body color aka the Planckian Locus curve for white point eye perceptionhttp://en.wikipedia.org/wiki/Black-body_radiation

Black-body radiation is the type of electromagnetic radiation within or surrounding a body in thermodynamic equilibrium with its environment, or emitted by a black body (an opaque and non-reflective body) held at constant, uniform temperature. The radiation has a specific spectrum and intensity that depends only on the temperature of the body.
A black-body at room temperature appears black, as most of the energy it radiates is infra-red and cannot be perceived by the human eye. At higher temperatures, black bodies glow with increasing intensity and colors that range from dull red to blindingly brilliant blue-white as the temperature increases.
The Black Body Ultraviolet Catastrophe Experiment

In photography, color temperature describes the spectrum of light which is radiated from a “blackbody” with that surface temperature. A blackbody is an object which absorbs all incident light — neither reflecting it nor allowing it to pass through.
The Sun closely approximates a black-body radiator. Another rough analogue of blackbody radiation in our day to day experience might be in heating a metal or stone: these are said to become “red hot” when they attain one temperature, and then “white hot” for even higher temperatures. Similarly, black bodies at different temperatures also have varying color temperatures of “white light.”
Despite its name, light which may appear white does not necessarily contain an even distribution of colors across the visible spectrum.
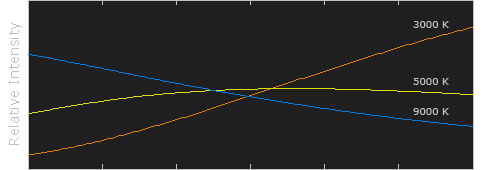
Although planets and stars are neither in thermal equilibrium with their surroundings nor perfect black bodies, black-body radiation is used as a first approximation for the energy they emit. Black holes are near-perfect black bodies, and it is believed that they emit black-body radiation (called Hawking radiation), with a temperature that depends on the mass of the hole.
-
RawTherapee – a free, open source, cross-platform raw image and HDRi processing program
Read more: RawTherapee – a free, open source, cross-platform raw image and HDRi processing program5.10 of this tool includes excellent tools to clean up cr2 and cr3 used on set to support HDRI processing.
Converting raw to AcesCG 32 bit tiffs with metadata.


-
Yasuharu YOSHIZAWA – Comparison of sRGB vs ACREScg in Nuke
Read more: Yasuharu YOSHIZAWA – Comparison of sRGB vs ACREScg in NukeAnswering the question that is often asked, “Do I need to use ACEScg to display an sRGB monitor in the end?” (Demonstration shown at an in-house seminar)
Comparison of scanlineRender output with extreme color lights on color charts with sRGB/ACREScg in color – OCIO -working space in NukeDownload the Nuke script:
-
About color: What is a LUT
Read more: About color: What is a LUThttp://www.lightillusion.com/luts.html
https://www.shutterstock.com/blog/how-use-luts-color-grading
A LUT (Lookup Table) is essentially the modifier between two images, the original image and the displayed image, based on a mathematical formula. Basically conversion matrices of different complexities. There are different types of LUTS – viewing, transform, calibration, 1D and 3D.













LIGHTING
-
LUX vs LUMEN vs NITS vs CANDELA – What is the difference
Read more: LUX vs LUMEN vs NITS vs CANDELA – What is the differenceMore details here: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminance
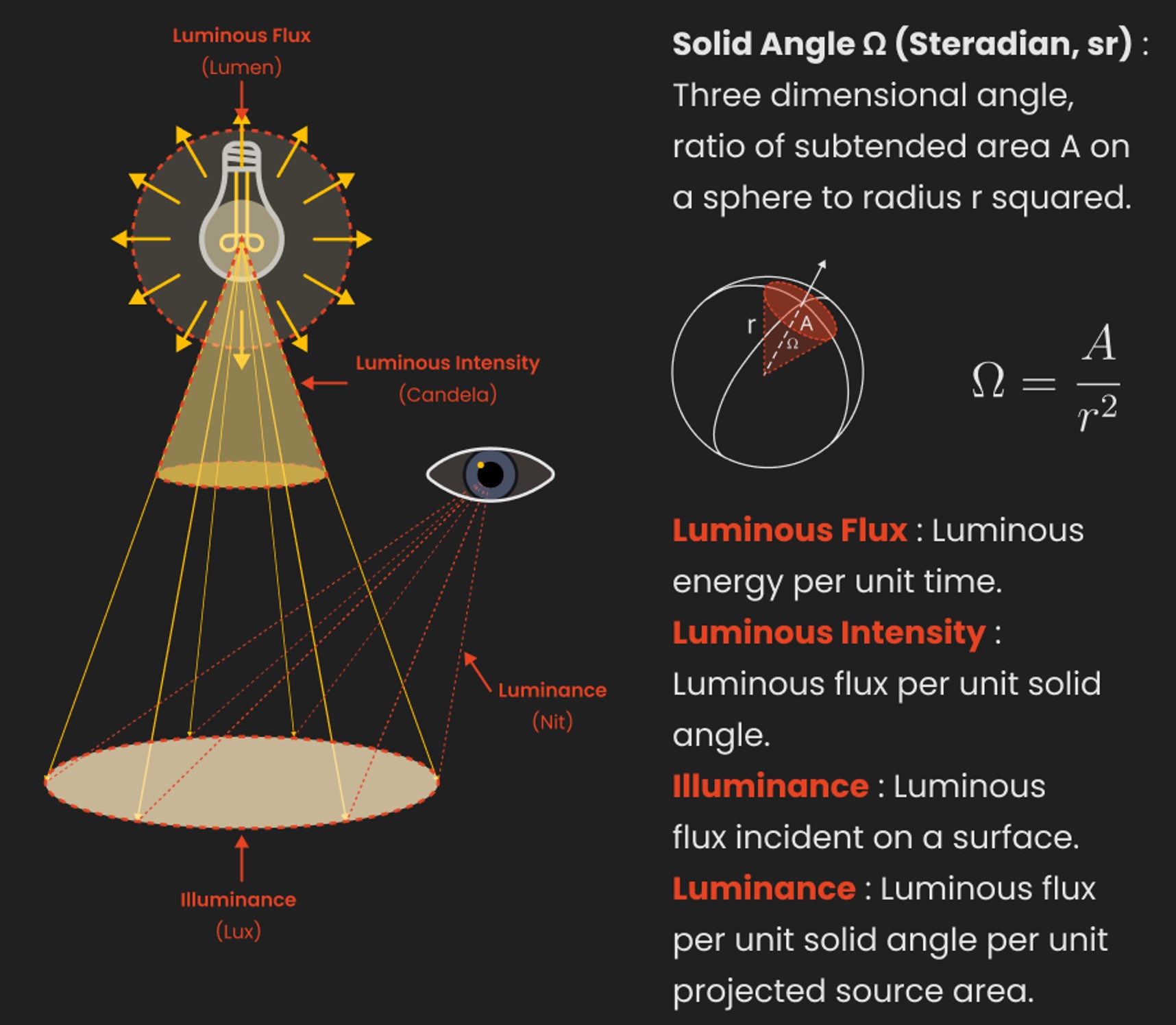


https://www.inhouseav.com.au/blog/beginners-guide-nits-lumens-brightness/

Candela
Candela is the basic unit of measure of the entire volume of light intensity from any point in a single direction from a light source. Note the detail: it measures the total volume of light within a certain beam angle and direction.
While the luminance of starlight is around 0.001 cd/m2, that of a sunlit scene is around 100,000 cd/m2, which is a hundred millions times higher. The luminance of the sun itself is approximately 1,000,000,000 cd/m2.NIT
https://en.wikipedia.org/wiki/Candela_per_square_metre
The candela per square metre (symbol: cd/m2) is the unit of luminance in the International System of Units (SI). The unit is based on the candela, the SI unit of luminous intensity, and the square metre, the SI unit of area. The nit (symbol: nt) is a non-SI name also used for this unit (1 nt = 1 cd/m2).[1] The term nit is believed to come from the Latin word nitēre, “to shine”. As a measure of light emitted per unit area, this unit is frequently used to specify the brightness of a display device.
NIT and cd/m2 (candela power) represent the same thing and can be used interchangeably. One nit is equivalent to one candela per square meter, where the candela is the amount of light which has been emitted by a common tallow candle, but NIT is not part of the International System of Units (abbreviated SI, from Systeme International, in French).
It’s easiest to think of a TV as emitting light directly, in much the same way as the Sun does. Nits are simply the measurement of the level of light (luminance) in a given area which the emitting source sends to your eyes or a camera sensor.
The Nit can be considered a unit of visible-light intensity which is often used to specify the brightness level of an LCD.
1 Nit is approximately equal to 3.426 Lumens. To work out a comparable number of Nits to Lumens, you need to multiply the number of Nits by 3.426. If you know the number of Lumens, and wish to know the Nits, simply divide the number of Lumens by 3.426.
Most consumer desktop LCDs have Nits of 200 to 300, the average TV most likely has an output capability of between 100 and 200 Nits, and an HDR TV ranges from 400 to 1,500 Nits.
Virtual Production sets currently sport around 6000 NIT ceiling and 1000 NIT wall panels.The ambient brightness of a sunny day with clear blue skies is between 7000-10,000 nits (between 3000-7000 nits for overcast skies and indirect sunlight).
A bright sunny day can have specular highlights that reach over 100,000 nits. Direct sunlight is around 1,600,000,000 nits.
10,000 nits is also the typical brightness of a fluorescent tube – bright, but not painful to look at.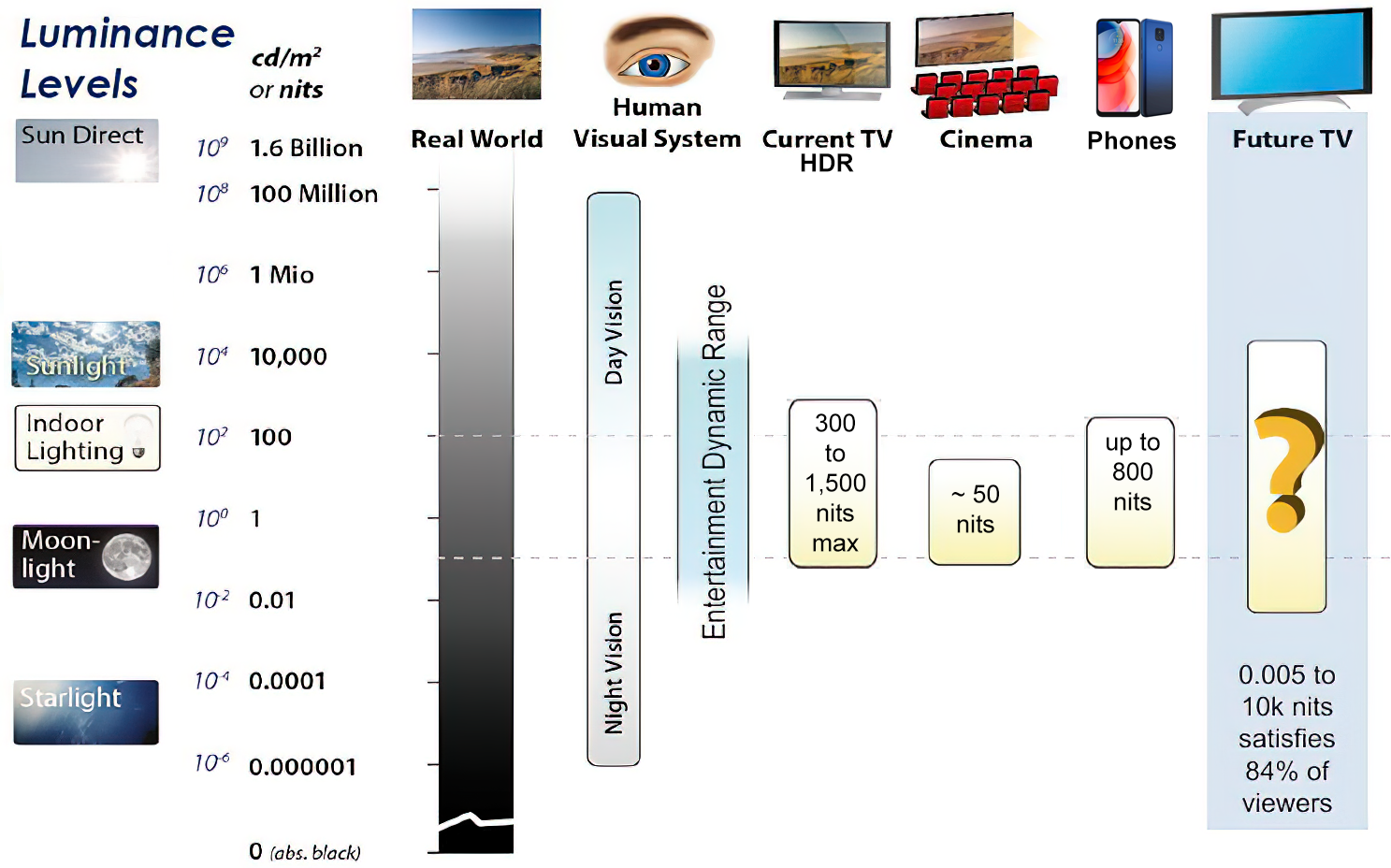
https://www.displaydaily.com/article/display-daily/dolby-vision-vs-hdr10-clarified
Tests showed that a “black level” of 0.005 nits (cd/m²) satisfied the vast majority of viewers. While 0.005 nits is very close to true black, Griffis says Dolby can go down to a black of 0.0001 nits, even though there is no need or ability for displays to get that dark today.
How bright is white? Dolby says the range of 0.005 nits – 10,000 nits satisfied 84% of the viewers in their viewing tests.
The brightest consumer HDR displays today are about 1,500 nits. Professional displays where HDR content is color-graded can achieve up to 4,000 nits peak brightness.High brightness that would be in danger of damaging the eye would be in the neighborhood of 250,000 nits.
Lumens
Lumen is a measure of how much light is emitted (luminance, luminous flux) by an object. It indicates the total potential amount of light from a light source that is visible to the human eye.
Lumen is commonly used in the context of light bulbs or video-projectors as a metric for their brightness power.Lumen is used to describe light output, and about video projectors, it is commonly referred to as ANSI Lumens. Simply put, lumens is how to find out how bright a LED display is. The higher the lumens, the brighter to display!
Technically speaking, a Lumen is the SI unit of luminous flux, which is equal to the amount of light which is emitted per second in a unit solid angle of one steradian from a uniform source of one-candela intensity radiating in all directions.
LUX
Lux (lx) or often Illuminance, is a photometric unit along a given area, which takes in account the sensitivity of human eye to different wavelenghts. It is the measure of light at a specific distance within a specific area at that distance. Often used to measure the incidental sun’s intensity.
-
Light and Matter : The 2018 theory of Physically-Based Rendering and Shading by Allegorithmic
Read more: Light and Matter : The 2018 theory of Physically-Based Rendering and Shading by Allegorithmicacademy.substance3d.com/courses/the-pbr-guide-part-1
academy.substance3d.com/courses/the-pbr-guide-part-2

 Local copy:
Local copy:


















COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
