


COMPOSITION
DESIGN
-
Creative duo Joseph Lattimer and Caitlin Derer Creates Absolutely Amazing The Beatles Collectable Toys
Read more: Creative duo Joseph Lattimer and Caitlin Derer Creates Absolutely Amazing The Beatles Collectable Toyshttps://designyoutrust.com/2024/11/artist-duo-creates-absolutely-amazing-the-beatles-collectable-toys



-
The illusion of sex 2009
Read more: The illusion of sex 2009
Richard Russell Harvard University, USA
In the Illusion of Sex, two faces are perceived as male and female.
However, both faces are actually versions of the same androgynous face.
One face was created by increasing the contrast of the androgynous face, while the other face was created by decreasing the contrast. The face with more contrast is perceived as female, while the face with less contrast is perceived as male. The Illusion of Sex demonstrates that contrast is an important cue for perceiving the sex of a face, with greater contrast appearing feminine, and lesser contrast appearing masculine.
Russell, R. (2009) A sex difference in facial pigmentation and its exaggeration by cosmetics. Perception, (38)1211-1219.





















COLOR
-
Stefan Ringelschwandtner – LUT Inspector tool
Read more: Stefan Ringelschwandtner – LUT Inspector toolIt lets you load any .cube LUT right in your browser, see the RGB curves, and use a split view on the Granger Test Image to compare the original vs. LUT-applied version in real time — perfect for spotting hue shifts, saturation changes, and contrast tweaks.
https://mononodes.com/lut-inspector/


-
Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental process
Read more: Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental processhttps://www.chrbutler.com/understanding-the-eye-mind-connection
The intricate relationship between the eyes and the brain, often termed the eye-mind connection, reveals that vision is predominantly a cognitive process. This understanding has profound implications for fields such as design, where capturing and maintaining attention is paramount. This essay delves into the nuances of visual perception, the brain’s role in interpreting visual data, and how this knowledge can be applied to effective design strategies.
This cognitive aspect of vision is evident in phenomena such as optical illusions, where the brain interprets visual information in a way that contradicts physical reality. These illusions underscore that what we “see” is not merely a direct recording of the external world but a constructed experience shaped by cognitive processes.
Understanding the cognitive nature of vision is crucial for effective design. Designers must consider how the brain processes visual information to create compelling and engaging visuals. This involves several key principles:
- Attention and Engagement
- Visual Hierarchy
- Cognitive Load Management
- Context and Meaning
-
The Maya civilization and the color blue
Read more: The Maya civilization and the color blueMaya blue is a highly unusual pigment because it is a mix of organic indigo and an inorganic clay mineral called palygorskite.
Echoing the color of an azure sky, the indelible pigment was used to accentuate everything from ceramics to human sacrifices in the Late Preclassic period (300 B.C. to A.D. 300).
A team of researchers led by Dean Arnold, an adjunct curator of anthropology at the Field Museum in Chicago, determined that the key to Maya blue was actually a sacred incense called copal.
By heating the mixture of indigo, copal and palygorskite over a fire, the Maya produced the unique pigment, he reported at the time.
-
StudioBinder.com – CRI color rendering index
Read more: StudioBinder.com – CRI color rendering indexwww.studiobinder.com/blog/what-is-color-rendering-index
“The Color Rendering Index is a measurement of how faithfully a light source reveals the colors of whatever it illuminates, it describes the ability of a light source to reveal the color of an object, as compared to the color a natural light source would provide. The highest possible CRI is 100. A CRI of 100 generally refers to a perfect black body, like a tungsten light source or the sun. ”


www.pixelsham.com/2021/04/28/types-of-film-lights-and-their-efficiency
-
Weta Digital – Manuka Raytracer and Gazebo GPU renderers – pipeline
Read more: Weta Digital – Manuka Raytracer and Gazebo GPU renderers – pipelinehttps://jo.dreggn.org/home/2018_manuka.pdf
http://www.fxguide.com/featured/manuka-weta-digitals-new-renderer/

The Manuka rendering architecture has been designed in the spirit of the classic reyes rendering architecture. In its core, reyes is based on stochastic rasterisation of micropolygons, facilitating depth of field, motion blur, high geometric complexity,and programmable shading.
This is commonly achieved with Monte Carlo path tracing, using a paradigm often called shade-on-hit, in which the renderer alternates tracing rays with running shaders on the various ray hits. The shaders take the role of generating the inputs of the local material structure which is then used bypath sampling logic to evaluate contributions and to inform what further rays to cast through the scene.
Over the years, however, the expectations have risen substantially when it comes to image quality. Computing pictures which are indistinguishable from real footage requires accurate simulation of light transport, which is most often performed using some variant of Monte Carlo path tracing. Unfortunately this paradigm requires random memory accesses to the whole scene and does not lend itself well to a rasterisation approach at all.
Manuka is both a uni-directional and bidirectional path tracer and encompasses multiple importance sampling (MIS). Interestingly, and importantly for production character skin work, it is the first major production renderer to incorporate spectral MIS in the form of a new ‘Hero Spectral Sampling’ technique, which was recently published at Eurographics Symposium on Rendering 2014.
Manuka propose a shade-before-hit paradigm in-stead and minimise I/O strain (and some memory costs) on the system, leveraging locality of reference by running pattern generation shaders before we execute light transport simulation by path sampling, “compressing” any bvh structure as needed, and as such also limiting duplication of source data.
The difference with reyes is that instead of baking colors into the geometry like in Reyes, manuka bakes surface closures. This means that light transport is still calculated with path tracing, but all texture lookups etc. are done up-front and baked into the geometry.The main drawback with this method is that geometry has to be tessellated to its highest, stable topology before shading can be evaluated properly. As such, the high cost to first pixel. Even a basic 4 vertices square becomes a much more complex model with this approach.

Manuka use the RenderMan Shading Language (rsl) for programmable shading [Pixar Animation Studios 2015], but we do not invoke rsl shaders when intersecting a ray with a surface (often called shade-on-hit). Instead, we pre-tessellate and pre-shade all the input geometry in the front end of the renderer.
This way, we can efficiently order shading computations to sup-port near-optimal texture locality, vectorisation, and parallelism. This system avoids repeated evaluation of shaders at the same surface point, and presents a minimal amount of memory to be accessed during light transport time. An added benefit is that the acceleration structure for ray tracing (abounding volume hierarchy, bvh) is built once on the final tessellated geometry, which allows us to ray trace more efficiently than multi-level bvhs and avoids costly caching of on-demand tessellated micropolygons and the associated scheduling issues.For the shading reasons above, in terms of AOVs, the studio approach is to succeed at combining complex shading with ray paths in the render rather than pass a multi-pass render to compositing.
For the Spectral Rendering component. The light transport stage is fully spectral, using a continuously sampled wavelength which is traced with each path and used to apply the spectral camera sensitivity of the sensor. This allows for faithfully support any degree of observer metamerism as the camera footage they are intended to match as well as complex materials which require wavelength dependent phenomena such as diffraction, dispersion, interference, iridescence, or chromatic extinction and Rayleigh scattering in participating media.
As opposed to the original reyes paper, we use bilinear interpolation of these bsdf inputs later when evaluating bsdfs per pathv ertex during light transport4. This improves temporal stability of geometry which moves very slowly with respect to the pixel raster
In terms of the pipeline, everything rendered at Weta was already completely interwoven with their deep data pipeline. Manuka very much was written with deep data in mind. Here, Manuka not so much extends the deep capabilities, rather it fully matches the already extremely complex and powerful setup Weta Digital already enjoy with RenderMan. For example, an ape in a scene can be selected, its ID is available and a NUKE artist can then paint in 3D say a hand and part of the way up the neutral posed ape.
We called our system Manuka, as a respectful nod to reyes: we had heard a story froma former ILM employee about how reyes got its name from how fond the early Pixar people were of their lunches at Point Reyes, and decided to name our system after our surrounding natural environment, too. Manuka is a kind of tea tree very common in New Zealand which has very many very small leaves, in analogy to micropolygons ina tree structure for ray tracing. It also happens to be the case that Weta Digital’s main site is on Manuka Street.












![[gamma correction test]](http://www.madore.org/~david/misc/color/gammatest.png "sRGB gamma correction test")




LIGHTING
-
Rec-2020 – TVs new color gamut standard used by Dolby Vision?
Read more: Rec-2020 – TVs new color gamut standard used by Dolby Vision?https://www.hdrsoft.com/resources/dri.html#bit-depth

The dynamic range is a ratio between the maximum and minimum values of a physical measurement. Its definition depends on what the dynamic range refers to.
For a scene: Dynamic range is the ratio between the brightest and darkest parts of the scene.
For a camera: Dynamic range is the ratio of saturation to noise. More specifically, the ratio of the intensity that just saturates the camera to the intensity that just lifts the camera response one standard deviation above camera noise.
For a display: Dynamic range is the ratio between the maximum and minimum intensities emitted from the screen.
The Dynamic Range of real-world scenes can be quite high — ratios of 100,000:1 are common in the natural world. An HDR (High Dynamic Range) image stores pixel values that span the whole tonal range of real-world scenes. Therefore, an HDR image is encoded in a format that allows the largest range of values, e.g. floating-point values stored with 32 bits per color channel. Another characteristics of an HDR image is that it stores linear values. This means that the value of a pixel from an HDR image is proportional to the amount of light measured by the camera.
For TVs HDR is great, but it’s not the only new TV feature worth discussing.
(more…) -
Magnific.ai Relight – change the entire lighting of a scene
Read more: Magnific.ai Relight – change the entire lighting of a scene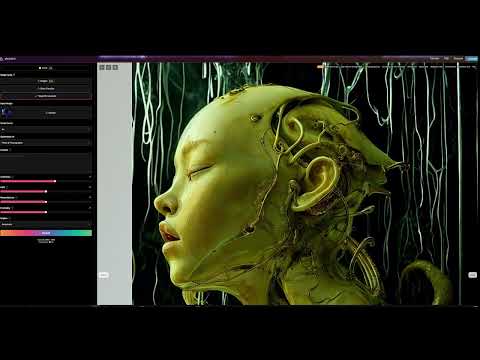
It’s a new Magnific spell that allows you to change the entire lighting of a scene and, optionally, the background with just:
1/ A prompt OR
2/ A reference image OR
3/ A light map (drawing your own lights)https://x.com/javilopen/status/1805274155065176489



-
Unity 3D resources
Read more: Unity 3D resources
http://answers.unity3d.com/questions/12321/how-can-i-start-learning-unity-fast-list-of-tutori.html
If you have no previous experience with Unity, start with these six video tutorials which give a quick overview of the Unity interface and some important features http://unity3d.com/support/documentation/video/
-
GretagMacbeth Color Checker Numeric Values and Middle Gray
Read more: GretagMacbeth Color Checker Numeric Values and Middle GrayThe human eye perceives half scene brightness not as the linear 50% of the present energy (linear nature values) but as 18% of the overall brightness. We are biased to perceive more information in the dark and contrast areas. A Macbeth chart helps with calibrating back into a photographic capture into this “human perspective” of the world.
https://en.wikipedia.org/wiki/Middle_gray
In photography, painting, and other visual arts, middle gray or middle grey is a tone that is perceptually about halfway between black and white on a lightness scale in photography and printing, it is typically defined as 18% reflectance in visible light

Light meters, cameras, and pictures are often calibrated using an 18% gray card[4][5][6] or a color reference card such as a ColorChecker. On the assumption that 18% is similar to the average reflectance of a scene, a grey card can be used to estimate the required exposure of the film.
https://en.wikipedia.org/wiki/ColorChecker
(more…) -
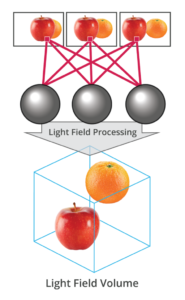
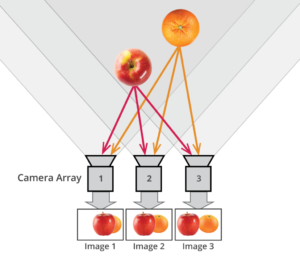
What is the Light Field?
Read more: What is the Light Field?http://lightfield-forum.com/what-is-the-lightfield/
The light field consists of the total of all light rays in 3D space, flowing through every point and in every direction.
How to Record a Light Field
- a single, robotically controlled camera
- a rotating arc of cameras
- an array of cameras or camera modules
- a single camera or camera lens fitted with a microlens array















{kind=link}
COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
