


COMPOSITION
-
7 Commandments of Film Editing and composition
Read more: 7 Commandments of Film Editing and composition
1. Watch every frame of raw footage twice. On the second time, take notes. If you don’t do this and try to start developing a scene premature, then it’s a big disservice to yourself and to the director, actors and production crew.
2. Nurture the relationships with the director. You are the secondary person in the relationship. Be calm and continually offer solutions. Get the main intention of the film as soon as possible from the director.
3. Organize your media so that you can find any shot instantly.
4. Factor in extra time for renders, exports, errors and crashes.
5. Attempt edits and ideas that shouldn’t work. It just might work. Until you do it and watch it, you won’t know. Don’t rule out ideas just because they don’t make sense in your mind.
6. Spend more time on your audio. It’s the glue of your edit. AUDIO SAVES EVERYTHING. Create fluid and seamless audio under your video.
7. Make cuts for the scene, but always in context for the whole film. Have a macro and a micro view at all times.
-
Cinematographers Blueprint 300dpi poster
Read more: Cinematographers Blueprint 300dpi posterThe 300dpi digital poster is now available to all PixelSham.com subscribers.

If you have already subscribed and wish a copy, please send me a note through the contact page.














DESIGN
COLOR
-
What is a Gamut or Color Space and why do I need to know about CIE
Read more: What is a Gamut or Color Space and why do I need to know about CIE

http://www.xdcam-user.com/2014/05/what-is-a-gamut-or-color-space-and-why-do-i-need-to-know-about-it/
In video terms gamut is normally related to as the full range of colours and brightness that can be either captured or displayed.
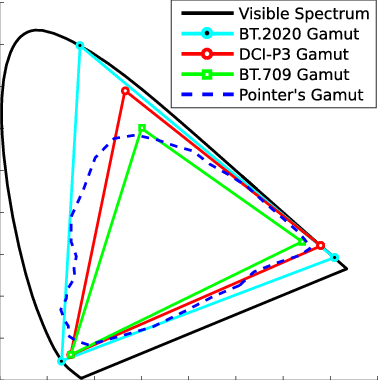
Generally speaking all color gamuts recommendations are trying to define a reasonable level of color representation based on available technology and hardware. REC-601 represents the old TVs. REC-709 is currently the most distributed solution. P3 is mainly available in movie theaters and is now being adopted in some of the best new 4K HDR TVs. Rec2020 (a wider space than P3 that improves on visibke color representation) and ACES (the full coverage of visible color) are other common standards which see major hardware development these days.
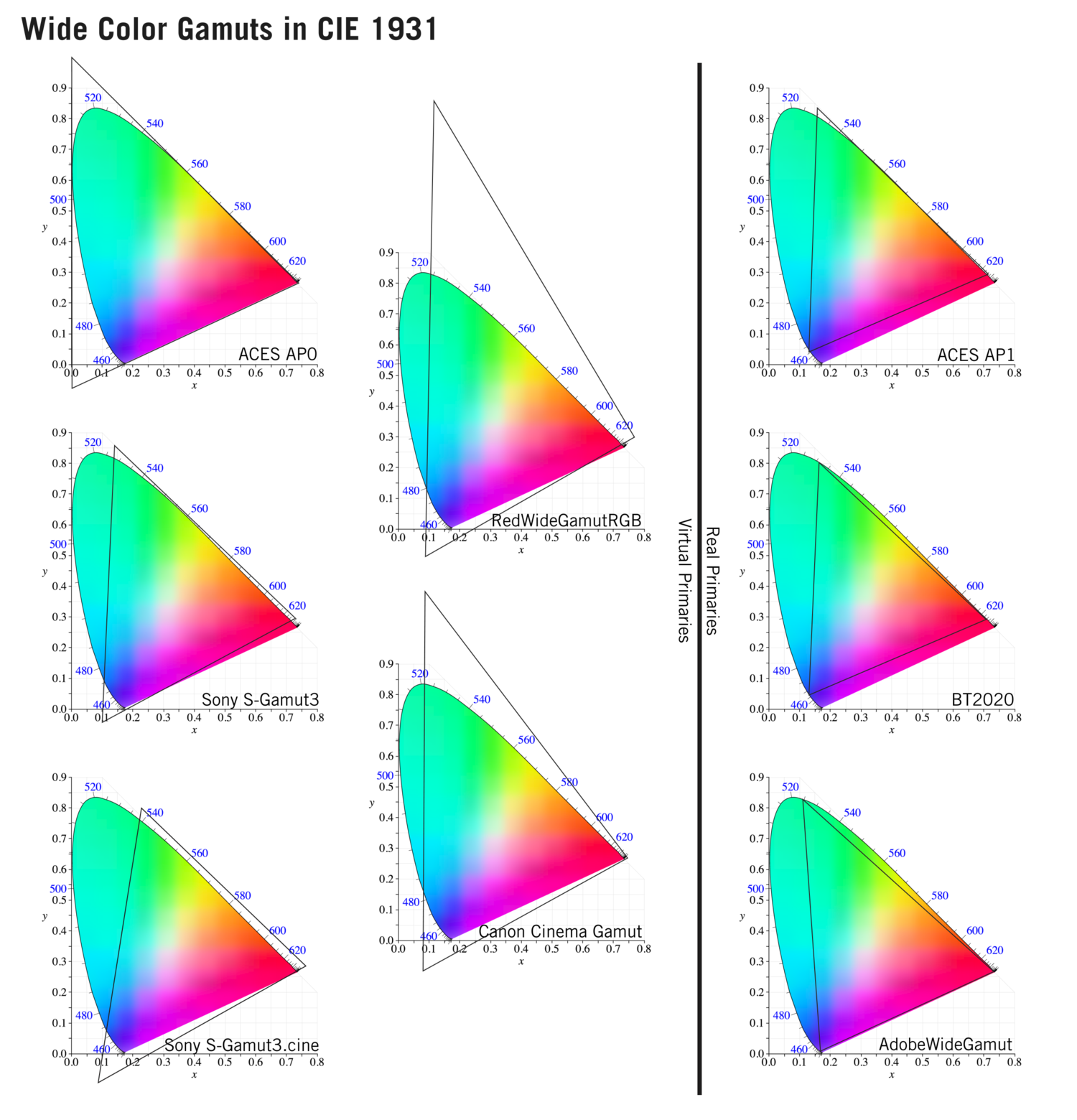
To compare and visualize different solution (across video and printing solutions), most developers use the CIE color model chart as a reference.
The CIE color model is a color space model created by the International Commission on Illumination known as the Commission Internationale de l’Elcairage (CIE) in 1931. It is also known as the CIE XYZ color space or the CIE 1931 XYZ color space.
This chart represents the first defined quantitative link between distributions of wavelengths in the electromagnetic visible spectrum, and physiologically perceived colors in human color vision. Or basically, the range of color a typical human eye can perceive through visible light.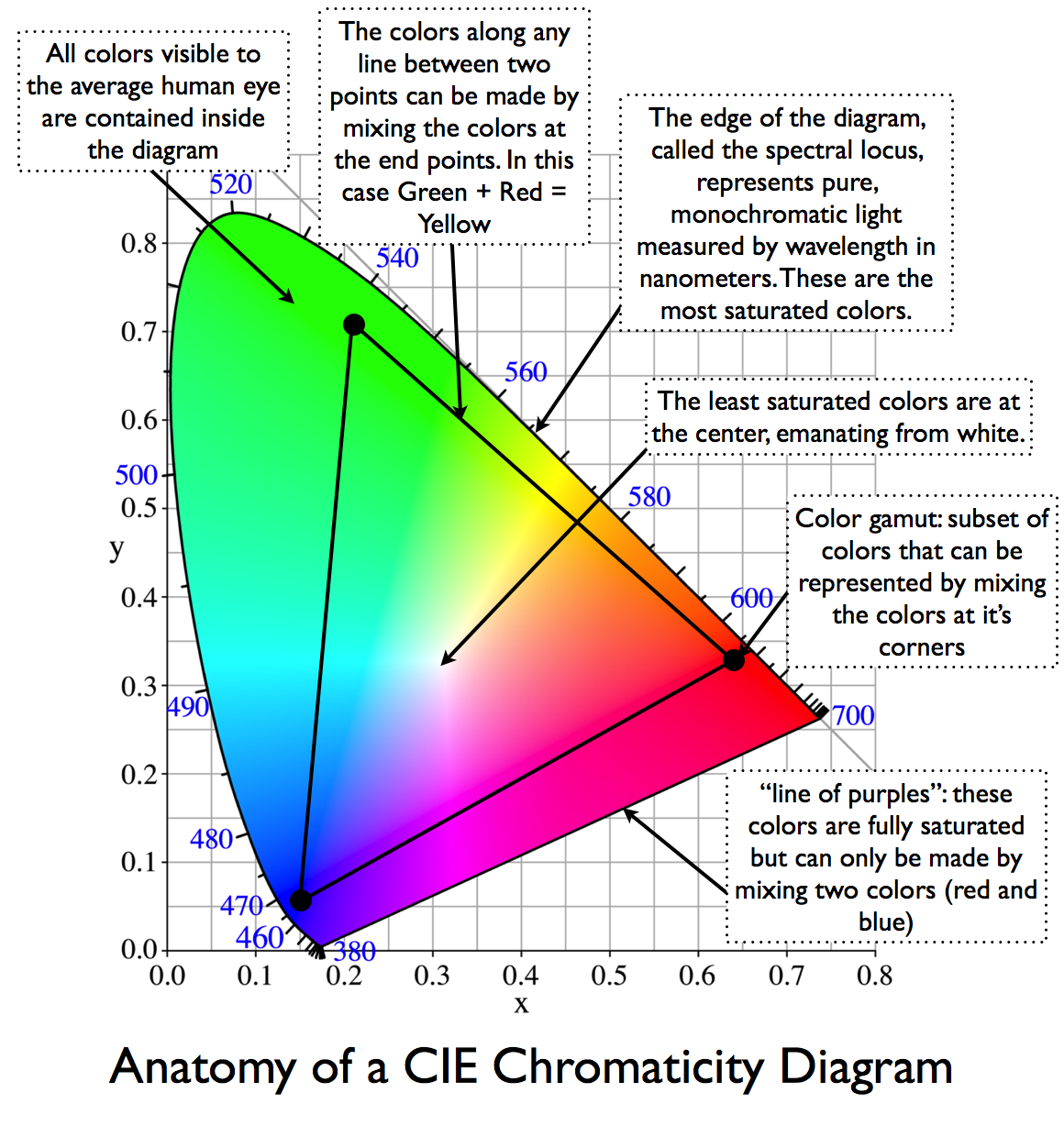
Note that while the human perception is quite wide, and generally speaking biased towards greens (we are apes after all), the amount of colors available through nature, generated through light reflection, tend to be a much smaller section. This is defined by the Pointer’s Chart.

In short. Color gamut is a representation of color coverage, used to describe data stored in images against available hardware and viewer technologies.
Camera color encoding from
https://www.slideshare.net/hpduiker/acescg-a-common-color-encoding-for-visual-effects-applications
CIE 1976
http://bernardsmith.eu/computatrum/scan_and_restore_archive_and_print/scanning/
https://store.yujiintl.com/blogs/high-cri-led/understanding-cie1931-and-cie-1976
The CIE 1931 standard has been replaced by a CIE 1976 standard. Below we can see the significance of this.
People have observed that the biggest issue with CIE 1931 is the lack of uniformity with chromaticity, the three dimension color space in rectangular coordinates is not visually uniformed.
The CIE 1976 (also called CIELUV) was created by the CIE in 1976. It was put forward in an attempt to provide a more uniform color spacing than CIE 1931 for colors at approximately the same luminance
The CIE 1976 standard colour space is more linear and variations in perceived colour between different people has also been reduced. The disproportionately large green-turquoise area in CIE 1931, which cannot be generated with existing computer screens, has been reduced.
If we move from CIE 1931 to the CIE 1976 standard colour space we can see that the improvements made in the gamut for the “new” iPad screen (as compared to the “old” iPad 2) are more evident in the CIE 1976 colour space than in the CIE 1931 colour space, particularly in the blues from aqua to deep blue.
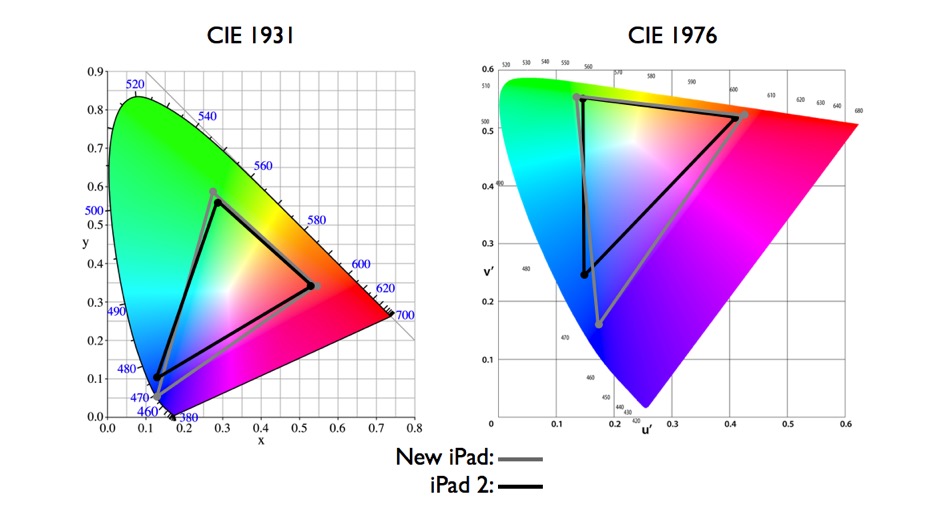
https://dot-color.com/2012/08/14/color-space-confusion/
Despite its age, CIE 1931, named for the year of its adoption, remains a well-worn and familiar shorthand throughout the display industry. CIE 1931 is the primary language of customers. When a customer says that their current display “can do 72% of NTSC,” they implicitly mean 72% of NTSC 1953 color gamut as mapped against CIE 1931.
-
Victor Perez – The Color Management Handbook for Visual Effects Artists
Read more: Victor Perez – The Color Management Handbook for Visual Effects ArtistsDigital Color Principles, Color Management Fundamentals & ACES Workflows

-
What is OLED and what can it do for your TV
Read more: What is OLED and what can it do for your TVhttps://www.cnet.com/news/what-is-oled-and-what-can-it-do-for-your-tv/
OLED stands for Organic Light Emitting Diode. Each pixel in an OLED display is made of a material that glows when you jab it with electricity. Kind of like the heating elements in a toaster, but with less heat and better resolution. This effect is called electroluminescence, which is one of those delightful words that is big, but actually makes sense: “electro” for electricity, “lumin” for light and “escence” for, well, basically “essence.”
OLED TV marketing often claims “infinite” contrast ratios, and while that might sound like typical hyperbole, it’s one of the extremely rare instances where such claims are actually true. Since OLED can produce a perfect black, emitting no light whatsoever, its contrast ratio (expressed as the brightest white divided by the darkest black) is technically infinite.
OLED is the only technology capable of absolute blacks and extremely bright whites on a per-pixel basis. LCD definitely can’t do that, and even the vaunted, beloved, dearly departed plasma couldn’t do absolute blacks.

-
Stefan Ringelschwandtner – LUT Inspector tool
Read more: Stefan Ringelschwandtner – LUT Inspector toolIt lets you load any .cube LUT right in your browser, see the RGB curves, and use a split view on the Granger Test Image to compare the original vs. LUT-applied version in real time — perfect for spotting hue shifts, saturation changes, and contrast tweaks.
https://mononodes.com/lut-inspector/


-
About green screens
Read more: About green screenshackaday.com/2015/02/07/how-green-screen-worked-before-computers/
www.newtek.com/blog/tips/best-green-screen-materials/
www.chromawall.com/blog//chroma-key-green

Chroma Key Green, the color of green screens is also known as Chroma Green and is valued at approximately 354C in the Pantone color matching system (PMS).
Chroma Green can be broken down in many different ways. Here is green screen green as other values useful for both physical and digital production:
Green Screen as RGB Color Value: 0, 177, 64
Green Screen as CMYK Color Value: 81, 0, 92, 0
Green Screen as Hex Color Value: #00b140
Green Screen as Websafe Color Value: #009933Chroma Key Green is reasonably close to an 18% gray reflectance.
Illuminate your green screen with an uniform source with less than 2/3 EV variation.
The level of brightness at any given f-stop should be equivalent to a 90% white card under the same lighting. -
Photography Basics : Spectral Sensitivity Estimation Without a Camera
Read more: Photography Basics : Spectral Sensitivity Estimation Without a Camerahttps://color-lab-eilat.github.io/Spectral-sensitivity-estimation-web/
A number of problems in computer vision and related fields would be mitigated if camera spectral sensitivities were known. As consumer cameras are not designed for high-precision visual tasks, manufacturers do not disclose spectral sensitivities. Their estimation requires a costly optical setup, which triggered researchers to come up with numerous indirect methods that aim to lower cost and complexity by using color targets. However, the use of color targets gives rise to new complications that make the estimation more difficult, and consequently, there currently exists no simple, low-cost, robust go-to method for spectral sensitivity estimation that non-specialized research labs can adopt. Furthermore, even if not limited by hardware or cost, researchers frequently work with imagery from multiple cameras that they do not have in their possession.
To provide a practical solution to this problem, we propose a framework for spectral sensitivity estimation that not only does not require any hardware (including a color target), but also does not require physical access to the camera itself. Similar to other work, we formulate an optimization problem that minimizes a two-term objective function: a camera-specific term from a system of equations, and a universal term that bounds the solution space.
Different than other work, we utilize publicly available high-quality calibration data to construct both terms. We use the colorimetric mapping matrices provided by the Adobe DNG Converter to formulate the camera-specific system of equations, and constrain the solutions using an autoencoder trained on a database of ground-truth curves. On average, we achieve reconstruction errors as low as those that can arise due to manufacturing imperfections between two copies of the same camera. We provide predicted sensitivities for more than 1,000 cameras that the Adobe DNG Converter currently supports, and discuss which tasks can become trivial when camera responses are available.










LIGHTING
-
3D Lighting Tutorial by Amaan Kram
Read more: 3D Lighting Tutorial by Amaan Kramhttp://www.amaanakram.com/lightingT/part1.htm
The goals of lighting in 3D computer graphics are more or less the same as those of real world lighting.
Lighting serves a basic function of bringing out, or pushing back the shapes of objects visible from the camera’s view.
It gives a two-dimensional image on the monitor an illusion of the third dimension-depth.But it does not just stop there. It gives an image its personality, its character. A scene lit in different ways can give a feeling of happiness, of sorrow, of fear etc., and it can do so in dramatic or subtle ways. Along with personality and character, lighting fills a scene with emotion that is directly transmitted to the viewer.
Trying to simulate a real environment in an artificial one can be a daunting task. But even if you make your 3D rendering look absolutely photo-realistic, it doesn’t guarantee that the image carries enough emotion to elicit a “wow” from the people viewing it.
Making 3D renderings photo-realistic can be hard. Putting deep emotions in them can be even harder. However, if you plan out your lighting strategy for the mood and emotion that you want your rendering to express, you make the process easier for yourself.
Each light source can be broken down in to 4 distinct components and analyzed accordingly.
· Intensity
· Direction
· Color
· SizeThe overall thrust of this writing is to produce photo-realistic images by applying good lighting techniques.

-
Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminance
Read more: Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminancehttps://www.translatorscafe.com/unit-converter/en-US/illumination/1-11/

The power output of a light source is measured using the unit of watts W. This is a direct measure to calculate how much power the light is going to drain from your socket and it is not relatable to the light brightness itself.
The amount of energy emitted from it per second. That energy comes out in a form of photons which we can crudely represent with rays of light coming out of the source. The higher the power the more rays emitted from the source in a unit of time.
Not all energy emitted is visible to the human eye, so we often rely on photometric measurements, which takes in account the sensitivity of human eye to different wavelenghts


Details in the post
(more…) -
Fast, optimized ‘for’ pixel loops with OpenCV and Python to create tone mapped HDR images
Read more: Fast, optimized ‘for’ pixel loops with OpenCV and Python to create tone mapped HDR imageshttps://pyimagesearch.com/2017/08/28/fast-optimized-for-pixel-loops-with-opencv-and-python/
https://learnopencv.com/exposure-fusion-using-opencv-cpp-python/
Exposure Fusion is a method for combining images taken with different exposure settings into one image that looks like a tone mapped High Dynamic Range (HDR) image.

-
DiffusionLight: HDRI Light Probes for Free by Painting a Chrome Ball
Read more: DiffusionLight: HDRI Light Probes for Free by Painting a Chrome Ballhttps://diffusionlight.github.io/
https://github.com/DiffusionLight/DiffusionLight
https://github.com/DiffusionLight/DiffusionLight?tab=MIT-1-ov-file#readme
https://colab.research.google.com/drive/15pC4qb9mEtRYsW3utXkk-jnaeVxUy-0S
“a simple yet effective technique to estimate lighting in a single input image. Current techniques rely heavily on HDR panorama datasets to train neural networks to regress an input with limited field-of-view to a full environment map. However, these approaches often struggle with real-world, uncontrolled settings due to the limited diversity and size of their datasets. To address this problem, we leverage diffusion models trained on billions of standard images to render a chrome ball into the input image. Despite its simplicity, this task remains challenging: the diffusion models often insert incorrect or inconsistent objects and cannot readily generate images in HDR format. Our research uncovers a surprising relationship between the appearance of chrome balls and the initial diffusion noise map, which we utilize to consistently generate high-quality chrome balls. We further fine-tune an LDR difusion model (Stable Diffusion XL) with LoRA, enabling it to perform exposure bracketing for HDR light estimation. Our method produces convincing light estimates across diverse settings and demonstrates superior generalization to in-the-wild scenarios.”

-
Open Source Nvidia Omniverse
Read more: Open Source Nvidia Omniverseblogs.nvidia.com/blog/2019/03/18/omniverse-collaboration-platform/

developer.nvidia.com/nvidia-omniverse
An open, Interactive 3D Design Collaboration Platform for Multi-Tool Workflows to simplify studio workflows for real-time graphics.
It supports Pixar’s Universal Scene Description technology for exchanging information about modeling, shading, animation, lighting, visual effects and rendering across multiple applications.
It also supports NVIDIA’s Material Definition Language, which allows artists to exchange information about surface materials across multiple tools.
With Omniverse, artists can see live updates made by other artists working in different applications. They can also see changes reflected in multiple tools at the same time.
For example an artist using Maya with a portal to Omniverse can collaborate with another artist using UE4 and both will see live updates of each others’ changes in their application.











COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
SourceTree vs Github Desktop – Which one to use
-
Kling 1.6 and competitors – advanced tests and comparisons
-
N8N.io – From Zero to Your First AI Agent in 25 Minutes
-
copypastecharacter.com – alphabets, special characters, alt codes and symbols library
-
Generative AI Glossary / AI Dictionary / AI Terminology
-
Film Production walk-through – pipeline – I want to make a … movie
-
Advanced Computer Vision with Python OpenCV and Mediapipe
-
Decart AI Mirage – The first ever World Transformation Model – turning any video, game, or camera feed into a new digital world, in real time
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
