


COMPOSITION
-
HuggingFace ai-comic-factory – a FREE AI Comic Book Creator
Read more: HuggingFace ai-comic-factory – a FREE AI Comic Book Creatorhttps://huggingface.co/spaces/jbilcke-hf/ai-comic-factory

this is the epic story of a group of talented digital artists trying to overcame daily technical challenges to achieve incredibly photorealistic projects of monsters and aliens

-
Cinematographers Blueprint 300dpi poster
Read more: Cinematographers Blueprint 300dpi posterThe 300dpi digital poster is now available to all PixelSham.com subscribers.

If you have already subscribed and wish a copy, please send me a note through the contact page.
-
StudioBinder – Roger Deakins on How to Choose a Camera Lens — Cinematography Composition Techniques
Read more: StudioBinder – Roger Deakins on How to Choose a Camera Lens — Cinematography Composition Techniques
https://www.studiobinder.com/blog/camera-lens-buying-guide/
https://www.studiobinder.com/blog/e-books/camera-lenses-explained-volume-1-ebook













DESIGN














COLOR
-
Photography Basics : Spectral Sensitivity Estimation Without a Camera
Read more: Photography Basics : Spectral Sensitivity Estimation Without a Camerahttps://color-lab-eilat.github.io/Spectral-sensitivity-estimation-web/
A number of problems in computer vision and related fields would be mitigated if camera spectral sensitivities were known. As consumer cameras are not designed for high-precision visual tasks, manufacturers do not disclose spectral sensitivities. Their estimation requires a costly optical setup, which triggered researchers to come up with numerous indirect methods that aim to lower cost and complexity by using color targets. However, the use of color targets gives rise to new complications that make the estimation more difficult, and consequently, there currently exists no simple, low-cost, robust go-to method for spectral sensitivity estimation that non-specialized research labs can adopt. Furthermore, even if not limited by hardware or cost, researchers frequently work with imagery from multiple cameras that they do not have in their possession.
To provide a practical solution to this problem, we propose a framework for spectral sensitivity estimation that not only does not require any hardware (including a color target), but also does not require physical access to the camera itself. Similar to other work, we formulate an optimization problem that minimizes a two-term objective function: a camera-specific term from a system of equations, and a universal term that bounds the solution space.
Different than other work, we utilize publicly available high-quality calibration data to construct both terms. We use the colorimetric mapping matrices provided by the Adobe DNG Converter to formulate the camera-specific system of equations, and constrain the solutions using an autoencoder trained on a database of ground-truth curves. On average, we achieve reconstruction errors as low as those that can arise due to manufacturing imperfections between two copies of the same camera. We provide predicted sensitivities for more than 1,000 cameras that the Adobe DNG Converter currently supports, and discuss which tasks can become trivial when camera responses are available.



-
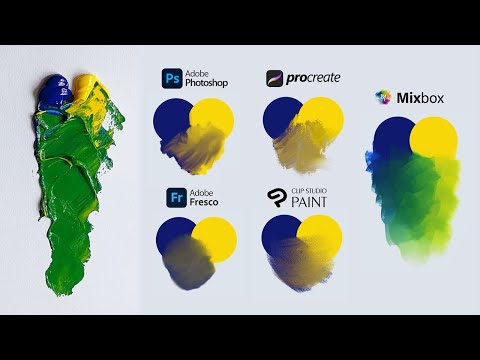
SecretWeapons MixBox – a practical library for paint-like digital color mixing
Read more: SecretWeapons MixBox – a practical library for paint-like digital color mixingInternally, Mixbox treats colors as real-life pigments using the Kubelka & Munk theory to predict realistic color behavior.
https://scrtwpns.com/mixbox/painter/
https://scrtwpns.com/mixbox.pdf
https://github.com/scrtwpns/mixbox
https://scrtwpns.com/mixbox/docs/














LIGHTING
-
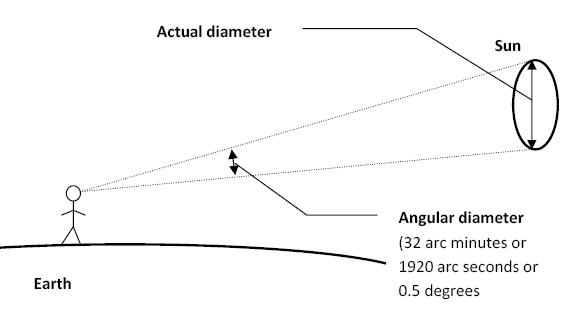
Sun cone angle (angular diameter) as perceived by earth viewers
Read more: Sun cone angle (angular diameter) as perceived by earth viewersAlso see:
https://www.pixelsham.com/2020/08/01/solid-angle-measures/
The cone angle of the sun refers to the angular diameter of the sun as observed from Earth, which is related to the apparent size of the sun in the sky.
The angular diameter of the sun, or the cone angle of the sunlight as perceived from Earth, is approximately 0.53 degrees on average. This value can vary slightly due to the elliptical nature of Earth’s orbit around the sun, but it generally stays within a narrow range.
Here’s a more precise breakdown:
-
- Average Angular Diameter: About 0.53 degrees (31 arcminutes)
- Minimum Angular Diameter: Approximately 0.52 degrees (when Earth is at aphelion, the farthest point from the sun)
- Maximum Angular Diameter: Approximately 0.54 degrees (when Earth is at perihelion, the closest point to the sun)
This angular diameter remains relatively constant throughout the day because the sun’s distance from Earth does not change significantly over a single day.
To summarize, the cone angle of the sun’s light, or its angular diameter, is typically around 0.53 degrees, regardless of the time of day.
https://en.wikipedia.org/wiki/Angular_diameter
-
-
Magnific.ai Relight – change the entire lighting of a scene
Read more: Magnific.ai Relight – change the entire lighting of a scene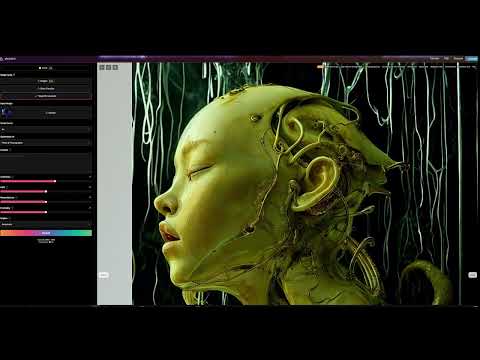
It’s a new Magnific spell that allows you to change the entire lighting of a scene and, optionally, the background with just:
1/ A prompt OR
2/ A reference image OR
3/ A light map (drawing your own lights)https://x.com/javilopen/status/1805274155065176489



-
Custom bokeh in a raytraced DOF render
Read more: Custom bokeh in a raytraced DOF render

To achieve a custom pinhole camera effect with a custom bokeh in Arnold Raytracer, you can follow these steps:
- Set the render camera with a focal length around 50 (or as needed)
- Set the F-Stop to a high value (e.g., 22).
- Set the focus distance as you require
- Turn on DOF
- Place a plane a few cm in front of the camera.
- Texture the plane with a transparent shape at the center of it. (Transmission with no specular roughness)
-
PTGui 13 beta adds control through a Patch Editor
Read more: PTGui 13 beta adds control through a Patch EditorAdditions:
- Patch Editor (PTGui Pro)
- DNG output
- Improved RAW / DNG handling
- JPEG 2000 support
- Performance improvements

-
HDRI Resources
Read more: HDRI ResourcesText2Light
- https://www.cgtrader.com/free-3d-models/exterior/other/10-free-hdr-panoramas-created-with-text2light-zero-shot
- https://frozenburning.github.io/projects/text2light/
- https://github.com/FrozenBurning/Text2Light
Royalty free links
- https://locationtextures.com/panoramas/
- http://www.noahwitchell.com/freebies
- https://polyhaven.com/hdris
- https://hdrmaps.com/
- https://www.ihdri.com/
- https://hdrihaven.com/
- https://www.domeble.com/
- http://www.hdrlabs.com/sibl/archive.html
- https://www.hdri-hub.com/hdrishop/hdri
- http://noemotionhdrs.net/hdrevening.html
- https://www.openfootage.net/hdri-panorama/
- https://www.zwischendrin.com/en/browse/hdri
Nvidia GauGAN360
-
Capturing the world in HDR for real time projects – Call of Duty: Advanced Warfare
Read more: Capturing the world in HDR for real time projects – Call of Duty: Advanced WarfareReal-World Measurements for Call of Duty: Advanced Warfare
www.activision.com/cdn/research/Real_World_Measurements_for_Call_of_Duty_Advanced_Warfare.pdf
Local version
Real_World_Measurements_for_Call_of_Duty_Advanced_Warfare.pdf

-
How to Direct and Edit a Fight Scene for Rhythm and Pacing
Read more: How to Direct and Edit a Fight Scene for Rhythm and Pacingwww.premiumbeat.com/blog/directing-fight-scene-cinematography/

1- Frame the action
2- Stage the action
3- Use camera movements
4- Set a rhythm
5- Control the speed of the action









COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Gamma correction
-
WhatDreamsCost Spline-Path-Control – Create motion controls for ComfyUI
-
RawTherapee – a free, open source, cross-platform raw image and HDRi processing program
-
AI Data Laundering: How Academic and Nonprofit Researchers Shield Tech Companies from Accountability
-
How does Stable Diffusion work?
-
3D Gaussian Splatting step by step beginner course
-
59 AI Filmmaking Tools For Your Workflow
-
Key/Fill ratios and scene composition using false colors and Nuke node
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
