


COMPOSITION
-
Composition – cinematography Cheat Sheet
Read more: Composition – cinematography Cheat Sheet
Where is our eye attracted first? Why?
Size. Focus. Lighting. Color.
Size. Mr. White (Harvey Keitel) on the right.
Focus. He’s one of the two objects in focus.
Lighting. Mr. White is large and in focus and Mr. Pink (Steve Buscemi) is highlighted by
a shaft of light.
Color. Both are black and white but the read on Mr. White’s shirt now really stands out.
(more…)
What type of lighting? -
9 Best Hacks to Make a Cinematic Video with Any Camera
Read more: 9 Best Hacks to Make a Cinematic Video with Any Camerahttps://www.flexclip.com/learn/cinematic-video.html
- Frame Your Shots to Create Depth
- Create Shallow Depth of Field
- Avoid Shaky Footage and Use Flexible Camera Movements
- Properly Use Slow Motion
- Use Cinematic Lighting Techniques
- Apply Color Grading
- Use Cinematic Music and SFX
- Add Cinematic Fonts and Text Effects
- Create the Cinematic Bar at the Top and the Bottom























DESIGN

















COLOR
-
PBR Color Reference List for Materials – by Grzegorz Baran
Read more: PBR Color Reference List for Materials – by Grzegorz Baran
“The list should be helpful for every material artist who work on PBR materials as it contains over 200 color values measured with PCE-RGB2 1002 Color Spectrometer device and presented in linear and sRGB (2.2) gamma space.
All color values, HUE and Saturation in this list come from measurements taken with PCE-RGB2 1002 Color Spectrometer device and are presented in linear and sRGB (2.2) gamma space (more info at the end of this video) I calculated Relative Luminance and Luminance values based on captured color using my own equation which takes color based luminance perception into consideration. Bare in mind that there is no ‘one’ color per substance as nothing in nature is even 100% uniform and any value in +/-10% range from these should be considered as correct one. Therefore this list should be always considered as a color reference for material’s albedos, not ulitimate and absolute truth.“
-
Scientists claim to have discovered ‘new colour’ no one has seen before: Olo
Read more: Scientists claim to have discovered ‘new colour’ no one has seen before: Olohttps://www.bbc.com/news/articles/clyq0n3em41o
By stimulating specific cells in the retina, the participants claim to have witnessed a blue-green colour that scientists have called “olo”, but some experts have said the existence of a new colour is “open to argument”.
The findings, published in the journal Science Advances on Friday, have been described by the study’s co-author, Prof Ren Ng from the University of California, as “remarkable”.

(A) System inputs. (i) Retina map of 103 cone cells preclassified by spectral type (7). (ii) Target visual percept (here, a video of a child, see movie S1 at 1:04). (iii) Infrared cellular-scale imaging of the retina with 60-frames-per-second rolling shutter. Fixational eye movement is visible over the three frames shown.
(B) System outputs. (iv) Real-time per-cone target activation levels to reproduce the target percept, computed by: extracting eye motion from the input video relative to the retina map; identifying the spectral type of every cone in the field of view; computing the per-cone activation the target percept would have produced. (v) Intensities of visible-wavelength 488-nm laser microdoses at each cone required to achieve its target activation level.
(C) Infrared imaging and visible-wavelength stimulation are physically accomplished in a raster scan across the retinal region using AOSLO. By modulating the visible-wavelength beam’s intensity, the laser microdoses shown in (v) are delivered. Drawing adapted with permission [Harmening and Sincich (54)].
(D) Examples of target percepts with corresponding cone activations and laser microdoses, ranging from colored squares to complex imagery. Teal-striped regions represent the color “olo” of stimulating only M cones.
-
StudioBinder.com – CRI color rendering index
Read more: StudioBinder.com – CRI color rendering indexwww.studiobinder.com/blog/what-is-color-rendering-index
“The Color Rendering Index is a measurement of how faithfully a light source reveals the colors of whatever it illuminates, it describes the ability of a light source to reveal the color of an object, as compared to the color a natural light source would provide. The highest possible CRI is 100. A CRI of 100 generally refers to a perfect black body, like a tungsten light source or the sun. ”


www.pixelsham.com/2021/04/28/types-of-film-lights-and-their-efficiency











![[gamma correction test]](http://www.madore.org/~david/misc/color/gammatest.png "sRGB gamma correction test")




LIGHTING
-
Polarised vs unpolarized filtering
Read more: Polarised vs unpolarized filteringA light wave that is vibrating in more than one plane is referred to as unpolarized light. …
Polarized light waves are light waves in which the vibrations occur in a single plane. The process of transforming unpolarized light into polarized light is known as polarization.

en.wikipedia.org/wiki/Polarizing_filter_(photography)
The most common use of polarized technology is to reduce lighting complexity on the subject.
(more…)
Details such as glare and hard edges are not removed, but greatly reduced. -
Custom bokeh in a raytraced DOF render
Read more: Custom bokeh in a raytraced DOF render

To achieve a custom pinhole camera effect with a custom bokeh in Arnold Raytracer, you can follow these steps:
- Set the render camera with a focal length around 50 (or as needed)
- Set the F-Stop to a high value (e.g., 22).
- Set the focus distance as you require
- Turn on DOF
- Place a plane a few cm in front of the camera.
- Texture the plane with a transparent shape at the center of it. (Transmission with no specular roughness)
-
Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacy
Read more: Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacynofilmschool.com/types-of-film-lights
“Not every light performs the same way. Lights and lighting are tricky to handle. You have to plan for every circumstance. But the good news is, lighting can be adjusted. Let’s look at different factors that affect lighting in every scene you shoot. “
Use CRI, Luminous Efficacy and color temperature controls to match your needs.
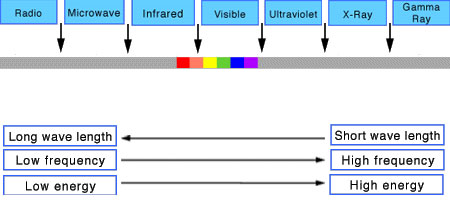
Color Temperature
Color temperature describes the “color” of white light by a light source radiated by a perfect black body at a given temperature measured in degrees Kelvinhttps://www.pixelsham.com/2019/10/18/color-temperature/
CRI
“The Color Rendering Index is a measurement of how faithfully a light source reveals the colors of whatever it illuminates, it describes the ability of a light source to reveal the color of an object, as compared to the color a natural light source would provide. The highest possible CRI is 100. A CRI of 100 generally refers to a perfect black body, like a tungsten light source or the sun. “https://www.studiobinder.com/blog/what-is-color-rendering-index
(more…) -
Insta360-Research-Team DiT360 – High-Fidelity Panoramic Image Generation via Hybrid Training
Read more: Insta360-Research-Team DiT360 – High-Fidelity Panoramic Image Generation via Hybrid Traininghttps://github.com/Insta360-Research-Team/DiT360
DiT360 is a framework for high-quality panoramic image generation, leveraging both perspective and panoramic data in a hybrid training scheme. It adopts a two-level strategy—image-level cross-domain guidance and token-level hybrid supervision—to enhance perceptual realism and geometric fidelity.










{kind=link}
COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Web vs Printing or digital RGB vs CMYK
-
Photography basics: Production Rendering Resolution Charts
-
Eddie Yoon – There’s a big misconception about AI creative
-
Types of AI Explained in a few Minutes – AI Glossary
-
VFX pipeline – Render Wall Farm management topics
-
Black Body color aka the Planckian Locus curve for white point eye perception
-
How do LLMs like ChatGPT (Generative Pre-Trained Transformer) work? Explained by Deep-Fake Ryan Gosling
-
JavaScript how-to free resources
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
