


COMPOSITION
-
SlowMoVideo – How to make a slow motion shot with the open source program
Read more: SlowMoVideo – How to make a slow motion shot with the open source programhttp://slowmovideo.granjow.net/
slowmoVideo is an OpenSource program that creates slow-motion videos from your footage.
Slow motion cinematography is the result of playing back frames for a longer duration than they were exposed. For example, if you expose 240 frames of film in one second, then play them back at 24 fps, the resulting movie is 10 times longer (slower) than the original filmed event….
Film cameras are relatively simple mechanical devices that allow you to crank up the speed to whatever rate the shutter and pull-down mechanism allow. Some film cameras can operate at 2,500 fps or higher (although film shot in these cameras often needs some readjustment in postproduction). Video, on the other hand, is always captured, recorded, and played back at a fixed rate, with a current limit around 60fps. This makes extreme slow motion effects harder to achieve (and less elegant) on video, because slowing down the video results in each frame held still on the screen for a long time, whereas with high-frame-rate film there are plenty of frames to fill the longer durations of time. On video, the slow motion effect is more like a slide show than smooth, continuous motion.
One obvious solution is to shoot film at high speed, then transfer it to video (a case where film still has a clear advantage, sorry George). Another possibility is to cross dissolve or blur from one frame to the next. This adds a smooth transition from one still frame to the next. The blur reduces the sharpness of the image, and compared to slowing down images shot at a high frame rate, this is somewhat of a cheat. However, there isn’t much you can do about it until video can be recorded at much higher rates. Of course, many film cameras can’t shoot at high frame rates either, so the whole super-slow-motion endeavor is somewhat specialized no matter what medium you are using. (There are some high speed digital cameras available now that allow you to capture lots of digital frames directly to your computer, so technology is starting to catch up with film. However, this feature isn’t going to appear in consumer camcorders any time soon.)
-
Photography basics: Camera Aspect Ratio, Sensor Size and Depth of Field – resolutions
Read more: Photography basics: Camera Aspect Ratio, Sensor Size and Depth of Field – resolutionshttp://www.shutterangle.com/2012/cinematic-look-aspect-ratio-sensor-size-depth-of-field/
http://www.shutterangle.com/2012/film-video-aspect-ratio-artistic-choice/

















DESIGN
-
-
Kelly Boesch – Static and Toward The Light
Read more: Kelly Boesch – Static and Toward The Lighthttps://www.kellyboeschdesign.com
I was working an album cover last night and got these really cool images in midjourney so made a video out of it. Animated using Pika. Song made using Suno Full version on my bandcamp. It’s called Static.
https://www.linkedin.com/posts/kellyboesch_midjourney-keyframes-ai-activity-7359244714853736450-Wvcr(more…) -
Chongqing the world’s largest city in pictures
Read more: Chongqing the world’s largest city in pictureshttps://www.theguardian.com/world/gallery/2025/apr/27/chongqing-the-worlds-largest-city-in-pictures
The largest city in the world is as big as Austria, but few people have ever heard of it. The megacity of 34 million people in central of China is the emblem of the fastest urban revolution on the planet.

















COLOR
-
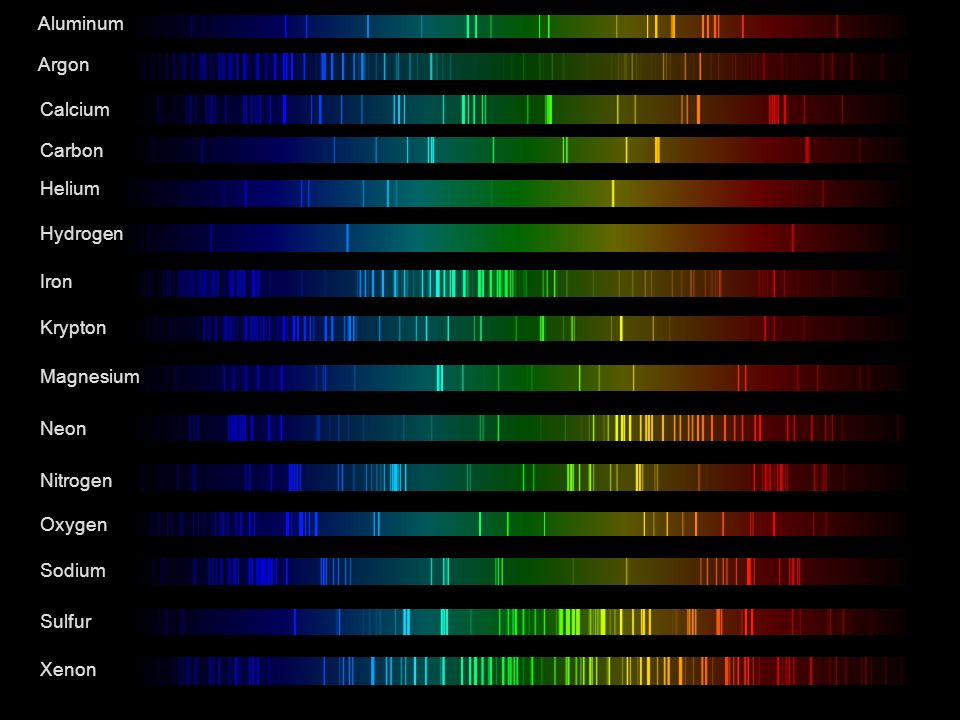
Space bodies’ components and light spectroscopy
Read more: Space bodies’ components and light spectroscopywww.plutorules.com/page-111-space-rocks.html
This help’s us understand the composition of components in/on solar system bodies.
Dips in the observed light spectrum, also known as, lines of absorption occur as gasses absorb energy from light at specific points along the light spectrum.
These dips or darkened zones (lines of absorption) leave a finger print which identify elements and compounds.
In this image the dark absorption bands appear as lines of emission which occur as the result of emitted not reflected (absorbed) light.
Lines of absorption
 Lines of emission
Lines of emission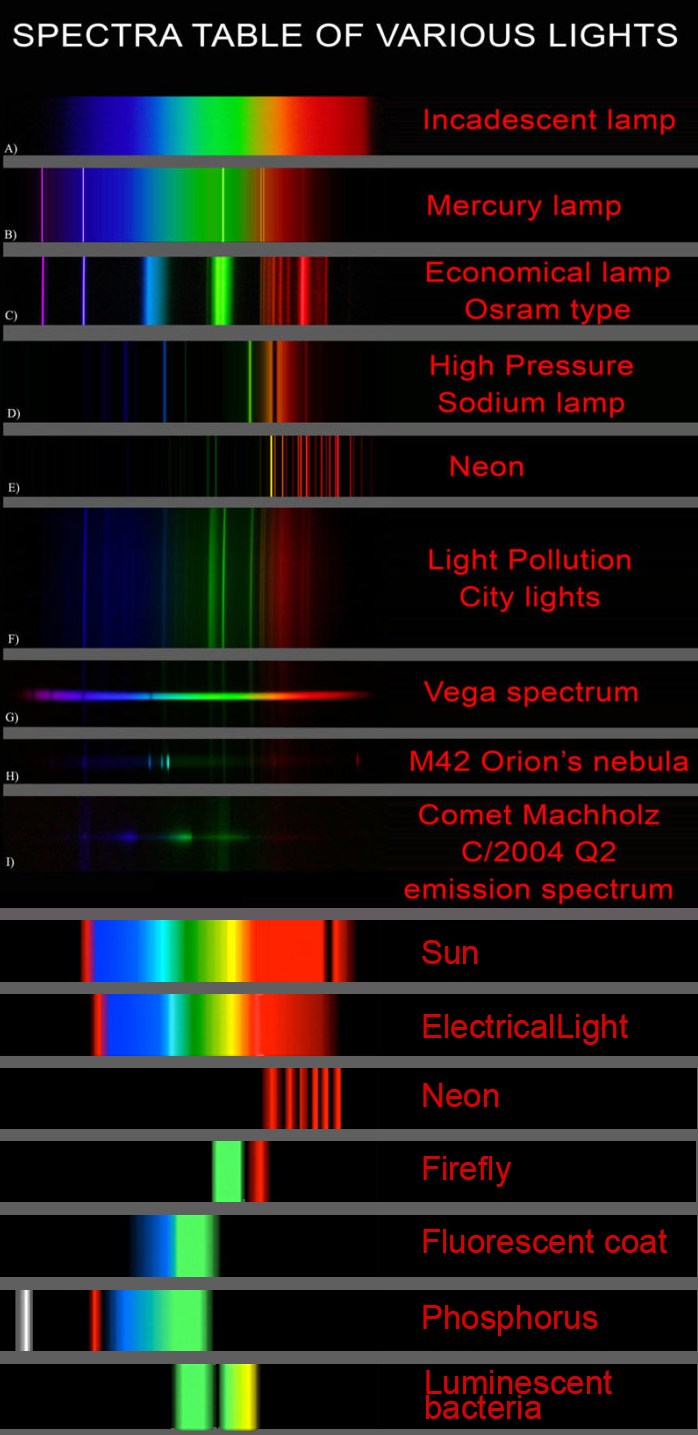
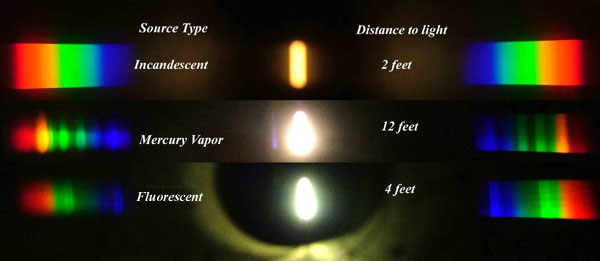


-
Capturing textures albedo
Read more: Capturing textures albedoBuilding a Portable PBR Texture Scanner by Stephane Lb
http://rtgfx.com/pbr-texture-scanner/

How To Split Specular And Diffuse In Real Images, by John Hable
http://filmicworlds.com/blog/how-to-split-specular-and-diffuse-in-real-images/Capturing albedo using a Spectralon
https://www.activision.com/cdn/research/Real_World_Measurements_for_Call_of_Duty_Advanced_Warfare.pdfReal_World_Measurements_for_Call_of_Duty_Advanced_Warfare.pdf
Spectralon is a teflon-based pressed powderthat comes closest to being a pure Lambertian diffuse material that reflects 100% of all light. If we take an HDR photograph of the Spectralon alongside the material to be measured, we can derive thediffuse albedo of that material.

The process to capture diffuse reflectance is very similar to the one outlined by Hable.
1. We put a linear polarizing filter in front of the camera lens and a second linear polarizing filterin front of a modeling light or a flash such that the two filters are oriented perpendicular to eachother, i.e. cross polarized.
2. We place Spectralon close to and parallel with the material we are capturing and take brack-eted shots of the setup7. Typically, we’ll take nine photographs, from -4EV to +4EV in 1EVincrements.
3. We convert the bracketed shots to a linear HDR image. We found that many HDR packagesdo not produce an HDR image in which the pixel values are linear. PTGui is an example of apackage which does generate a linear HDR image. At this point, because of the cross polarization,the image is one of surface diffuse response.
4. We open the file in Photoshop and normalize the image by color picking the Spectralon, filling anew layer with that color and setting that layer to “Divide”. This sets the Spectralon to 1 in theimage. All other color values are relative to this so we can consider them as diffuse albedo.
-
sRGB vs REC709 – An introduction and FFmpeg implementations
Read more: sRGB vs REC709 – An introduction and FFmpeg implementations
1. Basic Comparison
- What they are
- sRGB: A standard “web”/computer-display RGB color space defined by IEC 61966-2-1. It’s used for most monitors, cameras, printers, and the vast majority of images on the Internet.
- Rec. 709: An HD-video color space defined by ITU-R BT.709. It’s the go-to standard for HDTV broadcasts, Blu-ray discs, and professional video pipelines.
- Why they exist
- sRGB: Ensures consistent colors across different consumer devices (PCs, phones, webcams).
- Rec. 709: Ensures consistent colors across video production and playback chains (cameras → editing → broadcast → TV).
- What you’ll see
- On your desktop or phone, images tagged sRGB will look “right” without extra tweaking.
- On an HDTV or video-editing timeline, footage tagged Rec. 709 will display accurate contrast and hue on broadcast-grade monitors.
2. Digging Deeper
Feature sRGB Rec. 709 White point D65 (6504 K), same for both D65 (6504 K) Primaries (x,y) R: (0.640, 0.330) G: (0.300, 0.600) B: (0.150, 0.060) R: (0.640, 0.330) G: (0.300, 0.600) B: (0.150, 0.060) Gamut size Identical triangle on CIE 1931 chart Identical to sRGB Gamma / transfer Piecewise curve: approximate 2.2 with linear toe Pure power-law γ≈2.4 (often approximated as 2.2 in practice) Matrix coefficients N/A (pure RGB usage) Y = 0.2126 R + 0.7152 G + 0.0722 B (Rec. 709 matrix) Typical bit-depth 8-bit/channel (with 16-bit variants) 8-bit/channel (10-bit for professional video) Usage metadata Tagged as “sRGB” in image files (PNG, JPEG, etc.) Tagged as “bt709” in video containers (MP4, MOV) Color range Full-range RGB (0–255) Studio-range Y′CbCr (Y′ [16–235], Cb/Cr [16–240])
Why the Small Differences Matter
(more…) - What they are
-
Composition – cinematography Cheat Sheet
Read more: Composition – cinematography Cheat Sheet
Where is our eye attracted first? Why?
Size. Focus. Lighting. Color.
Size. Mr. White (Harvey Keitel) on the right.
Focus. He’s one of the two objects in focus.
Lighting. Mr. White is large and in focus and Mr. Pink (Steve Buscemi) is highlighted by
a shaft of light.
Color. Both are black and white but the read on Mr. White’s shirt now really stands out.
(more…)
What type of lighting? -
Is a MacBeth Colour Rendition Chart the Safest Way to Calibrate a Camera?
Read more: Is a MacBeth Colour Rendition Chart the Safest Way to Calibrate a Camera?www.colour-science.org/posts/the-colorchecker-considered-mostly-harmless/
“Unless you have all the relevant spectral measurements, a colour rendition chart should not be used to perform colour-correction of camera imagery but only for white balancing and relative exposure adjustments.”
“Using a colour rendition chart for colour-correction might dramatically increase error if the scene light source spectrum is different from the illuminant used to compute the colour rendition chart’s reference values.”
“other factors make using a colour rendition chart unsuitable for camera calibration:
– Uncontrolled geometry of the colour rendition chart with the incident illumination and the camera.
– Unknown sample reflectances and ageing as the colour of the samples vary with time.
– Low samples count.
– Camera noise and flare.
– Etc…“Those issues are well understood in the VFX industry, and when receiving plates, we almost exclusively use colour rendition charts to white balance and perform relative exposure adjustments, i.e. plate neutralisation.”









LIGHTING
-
Practical Aspects of Spectral Data and LEDs in Digital Content Production and Virtual Production – SIGGRAPH 2022
Read more: Practical Aspects of Spectral Data and LEDs in Digital Content Production and Virtual Production – SIGGRAPH 2022
Comparison to the commercial side

https://www.ecolorled.com/blog/detail/what-is-rgb-rgbw-rgbic-strip-lights
RGBW (RGB + White) LED strip uses a 4-in-1 LED chip made up of red, green, blue, and white.
RGBWW (RGB + White + Warm White) LED strip uses either a 5-in-1 LED chip with red, green, blue, white, and warm white for color mixing. The only difference between RGBW and RGBWW is the intensity of the white color. The term RGBCCT consists of RGB and CCT. CCT (Correlated Color Temperature) means that the color temperature of the led strip light can be adjusted to change between warm white and white. Thus, RGBWW strip light is another name of RGBCCT strip.
RGBCW is the acronym for Red, Green, Blue, Cold, and Warm. These 5-in-1 chips are used in supper bright smart LED lighting products
-
Bella – Fast Spectral Rendering
Read more: Bella – Fast Spectral Rendering
Bella works in spectral space, allowing effects such as BSDF wavelength dependency, diffraction, or atmosphere to be modeled far more accurately than in color space.

https://superrendersfarm.com/blog/uncategorized/bella-a-new-spectral-physically-based-renderer/
-
Light and Matter : The 2018 theory of Physically-Based Rendering and Shading by Allegorithmic
Read more: Light and Matter : The 2018 theory of Physically-Based Rendering and Shading by Allegorithmicacademy.substance3d.com/courses/the-pbr-guide-part-1
academy.substance3d.com/courses/the-pbr-guide-part-2

 Local copy:
Local copy:
-
Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacy
Read more: Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacynofilmschool.com/types-of-film-lights
“Not every light performs the same way. Lights and lighting are tricky to handle. You have to plan for every circumstance. But the good news is, lighting can be adjusted. Let’s look at different factors that affect lighting in every scene you shoot. “
Use CRI, Luminous Efficacy and color temperature controls to match your needs.
Color Temperature
Color temperature describes the “color” of white light by a light source radiated by a perfect black body at a given temperature measured in degrees Kelvinhttps://www.pixelsham.com/2019/10/18/color-temperature/
CRI
“The Color Rendering Index is a measurement of how faithfully a light source reveals the colors of whatever it illuminates, it describes the ability of a light source to reveal the color of an object, as compared to the color a natural light source would provide. The highest possible CRI is 100. A CRI of 100 generally refers to a perfect black body, like a tungsten light source or the sun. “https://www.studiobinder.com/blog/what-is-color-rendering-index
(more…)








COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
NVidia – High-Fidelity 3D Mesh Generation at Scale with Meshtron
-
59 AI Filmmaking Tools For Your Workflow
-
Top 3D Printing Website Resources
-
Daniele Tosti Interview for the magazine InCG, Taiwan, Issue 28, 201609
-
Types of AI Explained in a few Minutes – AI Glossary
-
Film Production walk-through – pipeline – I want to make a … movie
-
Most common ways to smooth 3D prints
-
4dv.ai – Remote Interactive 3D Holographic Presentation Technology and System running on the PlayCanvas engine
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
