


COMPOSITION



















DESIGN
COLOR
-
What is OLED and what can it do for your TV
Read more: What is OLED and what can it do for your TVhttps://www.cnet.com/news/what-is-oled-and-what-can-it-do-for-your-tv/
OLED stands for Organic Light Emitting Diode. Each pixel in an OLED display is made of a material that glows when you jab it with electricity. Kind of like the heating elements in a toaster, but with less heat and better resolution. This effect is called electroluminescence, which is one of those delightful words that is big, but actually makes sense: “electro” for electricity, “lumin” for light and “escence” for, well, basically “essence.”
OLED TV marketing often claims “infinite” contrast ratios, and while that might sound like typical hyperbole, it’s one of the extremely rare instances where such claims are actually true. Since OLED can produce a perfect black, emitting no light whatsoever, its contrast ratio (expressed as the brightest white divided by the darkest black) is technically infinite.
OLED is the only technology capable of absolute blacks and extremely bright whites on a per-pixel basis. LCD definitely can’t do that, and even the vaunted, beloved, dearly departed plasma couldn’t do absolute blacks.

-
What is a Gamut or Color Space and why do I need to know about CIE
Read more: What is a Gamut or Color Space and why do I need to know about CIE

http://www.xdcam-user.com/2014/05/what-is-a-gamut-or-color-space-and-why-do-i-need-to-know-about-it/
In video terms gamut is normally related to as the full range of colours and brightness that can be either captured or displayed.
Generally speaking all color gamuts recommendations are trying to define a reasonable level of color representation based on available technology and hardware. REC-601 represents the old TVs. REC-709 is currently the most distributed solution. P3 is mainly available in movie theaters and is now being adopted in some of the best new 4K HDR TVs. Rec2020 (a wider space than P3 that improves on visibke color representation) and ACES (the full coverage of visible color) are other common standards which see major hardware development these days.
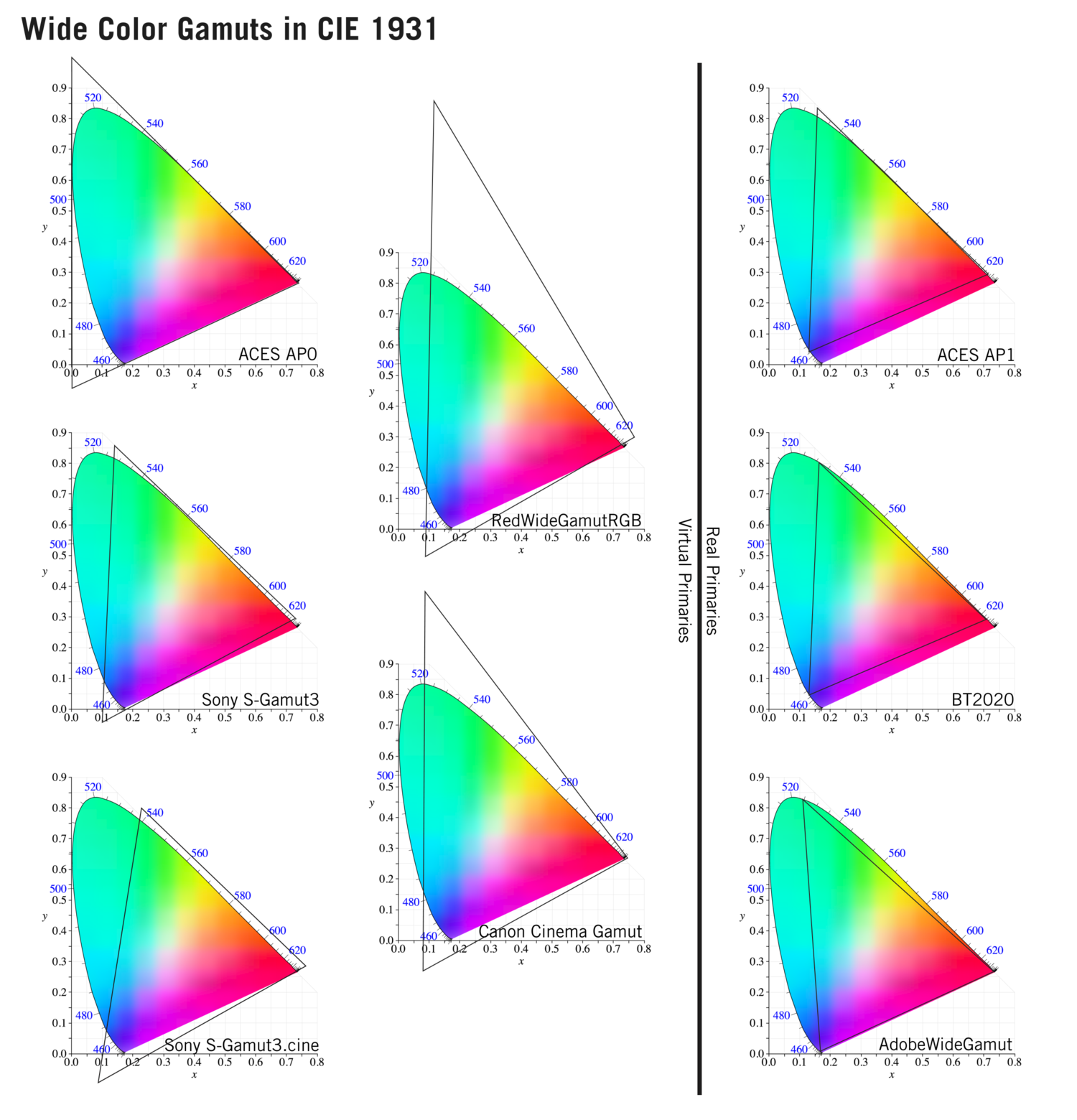
To compare and visualize different solution (across video and printing solutions), most developers use the CIE color model chart as a reference.
The CIE color model is a color space model created by the International Commission on Illumination known as the Commission Internationale de l’Elcairage (CIE) in 1931. It is also known as the CIE XYZ color space or the CIE 1931 XYZ color space.
This chart represents the first defined quantitative link between distributions of wavelengths in the electromagnetic visible spectrum, and physiologically perceived colors in human color vision. Or basically, the range of color a typical human eye can perceive through visible light.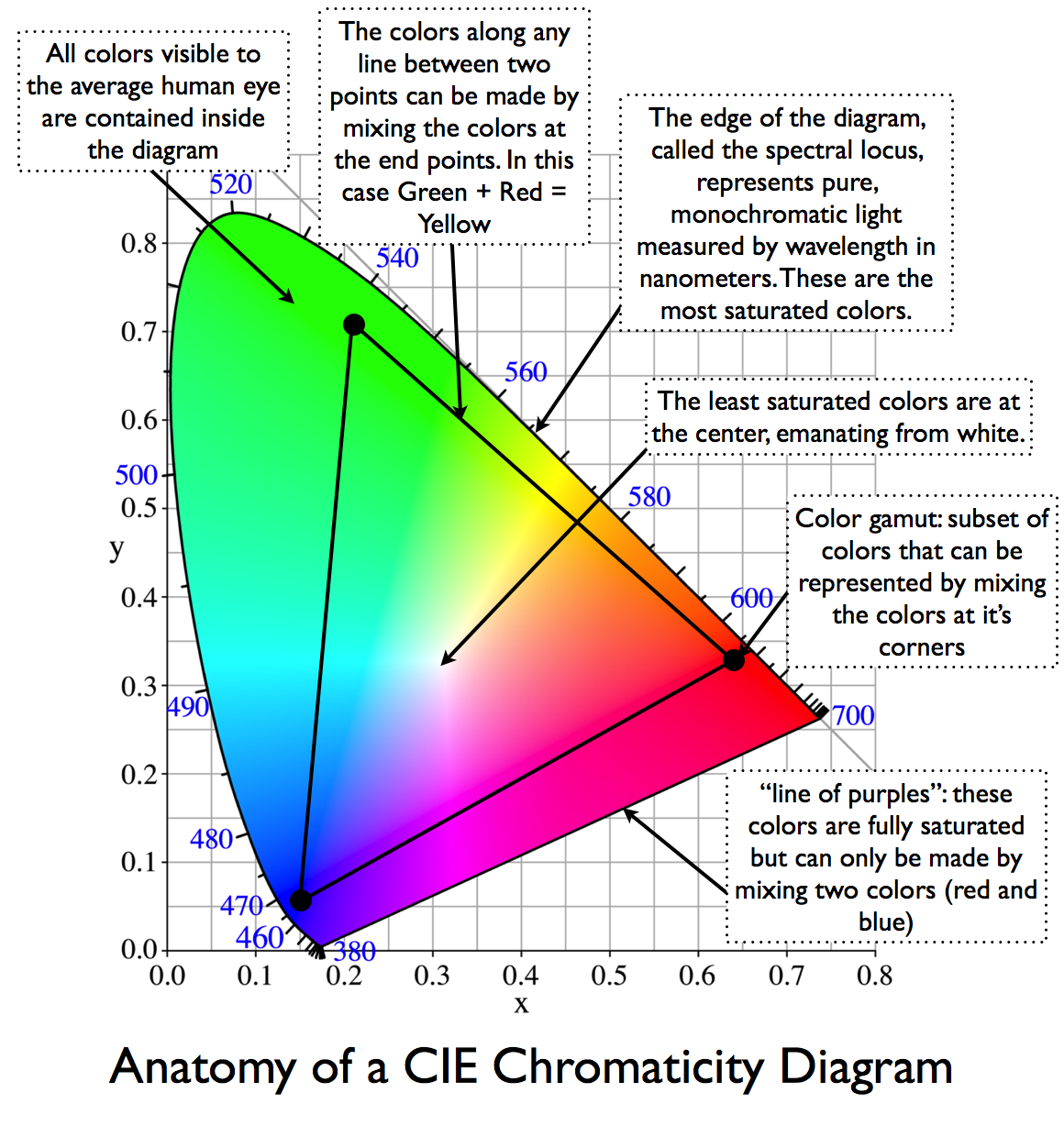
Note that while the human perception is quite wide, and generally speaking biased towards greens (we are apes after all), the amount of colors available through nature, generated through light reflection, tend to be a much smaller section. This is defined by the Pointer’s Chart.
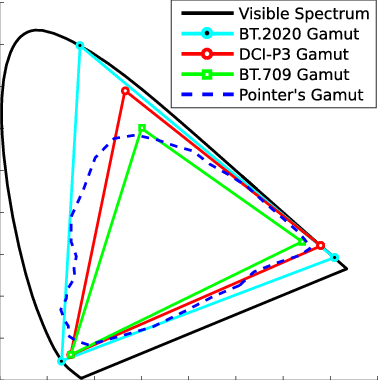

In short. Color gamut is a representation of color coverage, used to describe data stored in images against available hardware and viewer technologies.
Camera color encoding from
https://www.slideshare.net/hpduiker/acescg-a-common-color-encoding-for-visual-effects-applications
CIE 1976
http://bernardsmith.eu/computatrum/scan_and_restore_archive_and_print/scanning/
https://store.yujiintl.com/blogs/high-cri-led/understanding-cie1931-and-cie-1976
The CIE 1931 standard has been replaced by a CIE 1976 standard. Below we can see the significance of this.
People have observed that the biggest issue with CIE 1931 is the lack of uniformity with chromaticity, the three dimension color space in rectangular coordinates is not visually uniformed.
The CIE 1976 (also called CIELUV) was created by the CIE in 1976. It was put forward in an attempt to provide a more uniform color spacing than CIE 1931 for colors at approximately the same luminance
The CIE 1976 standard colour space is more linear and variations in perceived colour between different people has also been reduced. The disproportionately large green-turquoise area in CIE 1931, which cannot be generated with existing computer screens, has been reduced.
If we move from CIE 1931 to the CIE 1976 standard colour space we can see that the improvements made in the gamut for the “new” iPad screen (as compared to the “old” iPad 2) are more evident in the CIE 1976 colour space than in the CIE 1931 colour space, particularly in the blues from aqua to deep blue.
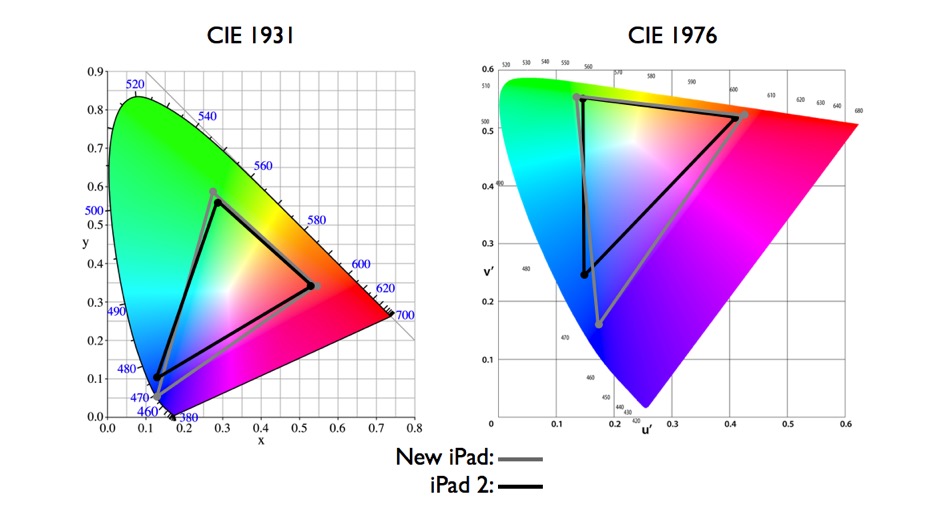
https://dot-color.com/2012/08/14/color-space-confusion/
Despite its age, CIE 1931, named for the year of its adoption, remains a well-worn and familiar shorthand throughout the display industry. CIE 1931 is the primary language of customers. When a customer says that their current display “can do 72% of NTSC,” they implicitly mean 72% of NTSC 1953 color gamut as mapped against CIE 1931.
-
Practical Aspects of Spectral Data and LEDs in Digital Content Production and Virtual Production – SIGGRAPH 2022
Read more: Practical Aspects of Spectral Data and LEDs in Digital Content Production and Virtual Production – SIGGRAPH 2022
Comparison to the commercial side

https://www.ecolorled.com/blog/detail/what-is-rgb-rgbw-rgbic-strip-lights
RGBW (RGB + White) LED strip uses a 4-in-1 LED chip made up of red, green, blue, and white.
RGBWW (RGB + White + Warm White) LED strip uses either a 5-in-1 LED chip with red, green, blue, white, and warm white for color mixing. The only difference between RGBW and RGBWW is the intensity of the white color. The term RGBCCT consists of RGB and CCT. CCT (Correlated Color Temperature) means that the color temperature of the led strip light can be adjusted to change between warm white and white. Thus, RGBWW strip light is another name of RGBCCT strip.
RGBCW is the acronym for Red, Green, Blue, Cold, and Warm. These 5-in-1 chips are used in supper bright smart LED lighting products
-
Mysterious animation wins best illusion of 2011 – Motion silencing illusion
Read more: Mysterious animation wins best illusion of 2011 – Motion silencing illusionThe 2011 Best Illusion of the Year uses motion to render color changes invisible, and so reveals a quirk in our visual systems that is new to scientists.
https://en.wikipedia.org/wiki/Motion_silencing_illusion
“It is a really beautiful effect, revealing something about how our visual system works that we didn’t know before,” said Daniel Simons, a professor at the University of Illinois, Champaign-Urbana. Simons studies visual cognition, and did not work on this illusion. Before its creation, scientists didn’t know that motion had this effect on perception, Simons said.
A viewer stares at a speck at the center of a ring of colored dots, which continuously change color. When the ring begins to rotate around the speck, the color changes appear to stop. But this is an illusion. For some reason, the motion causes our visual system to ignore the color changes. (You can, however, see the color changes if you follow the rotating circles with your eyes.)












![[gamma correction test]](http://www.madore.org/~david/misc/color/gammatest.png "sRGB gamma correction test")


LIGHTING
-
Terminators and Iron Men: HDRI, Image-based lighting and physical shading at ILM – Siggraph 2010
Read more: Terminators and Iron Men: HDRI, Image-based lighting and physical shading at ILM – Siggraph 2010 -
Composition and The Expressive Nature Of Light
Read more: Composition and The Expressive Nature Of Lighthttp://www.huffingtonpost.com/bill-danskin/post_12457_b_10777222.html
George Sand once said “ The artist vocation is to send light into the human heart.”














COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminance
-
Types of AI Explained in a few Minutes – AI Glossary
-
59 AI Filmmaking Tools For Your Workflow
-
Web vs Printing or digital RGB vs CMYK
-
GretagMacbeth Color Checker Numeric Values and Middle Gray
-
Ross Pettit on The Agile Manager – How tech firms went for prioritizing cash flow instead of talent (and artists)
-
4dv.ai – Remote Interactive 3D Holographic Presentation Technology and System running on the PlayCanvas engine
-
Methods for creating motion blur in Stop motion
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
