


COMPOSITION
-
Photography basics: Camera Aspect Ratio, Sensor Size and Depth of Field – resolutions
Read more: Photography basics: Camera Aspect Ratio, Sensor Size and Depth of Field – resolutionshttp://www.shutterangle.com/2012/cinematic-look-aspect-ratio-sensor-size-depth-of-field/
http://www.shutterangle.com/2012/film-video-aspect-ratio-artistic-choice/






















DESIGN
COLOR
-
Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental process
Read more: Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental processhttps://www.chrbutler.com/understanding-the-eye-mind-connection
The intricate relationship between the eyes and the brain, often termed the eye-mind connection, reveals that vision is predominantly a cognitive process. This understanding has profound implications for fields such as design, where capturing and maintaining attention is paramount. This essay delves into the nuances of visual perception, the brain’s role in interpreting visual data, and how this knowledge can be applied to effective design strategies.
This cognitive aspect of vision is evident in phenomena such as optical illusions, where the brain interprets visual information in a way that contradicts physical reality. These illusions underscore that what we “see” is not merely a direct recording of the external world but a constructed experience shaped by cognitive processes.
Understanding the cognitive nature of vision is crucial for effective design. Designers must consider how the brain processes visual information to create compelling and engaging visuals. This involves several key principles:
- Attention and Engagement
- Visual Hierarchy
- Cognitive Load Management
- Context and Meaning
-
Light and Matter : The 2018 theory of Physically-Based Rendering and Shading by Allegorithmic
Read more: Light and Matter : The 2018 theory of Physically-Based Rendering and Shading by Allegorithmicacademy.substance3d.com/courses/the-pbr-guide-part-1
academy.substance3d.com/courses/the-pbr-guide-part-2

 Local copy:
Local copy:
-
HDR and Color
Read more: HDR and Colorhttps://www.soundandvision.com/content/nits-and-bits-hdr-and-color
In HD we often refer to the range of available colors as a color gamut. Such a color gamut is typically plotted on a two-dimensional diagram, called a CIE chart, as shown in at the top of this blog. Each color is characterized by its x/y coordinates.

Good enough for government work, perhaps. But for HDR, with its higher luminance levels and wider color, the gamut becomes three-dimensional.

For HDR the color gamut therefore becomes a characteristic we now call the color volume. It isn’t easy to show color volume on a two-dimensional medium like the printed page or a computer screen, but one method is shown below. As the luminance becomes higher, the picture eventually turns to white. As it becomes darker, it fades to black. The traditional color gamut shown on the CIE chart is simply a slice through this color volume at a selected luminance level, such as 50%.
Three different color volumes—we still refer to them as color gamuts though their third dimension is important—are currently the most significant. The first is BT.709 (sometimes referred to as Rec.709), the color gamut used for pre-UHD/HDR formats, including standard HD.
The largest is known as BT.2020; it encompasses (roughly) the range of colors visible to the human eye (though ET might find it insufficient!).
Between these two is the color gamut used in digital cinema, known as DCI-P3.

sRGB

D65

-
sRGB vs REC709 – An introduction and FFmpeg implementations
Read more: sRGB vs REC709 – An introduction and FFmpeg implementations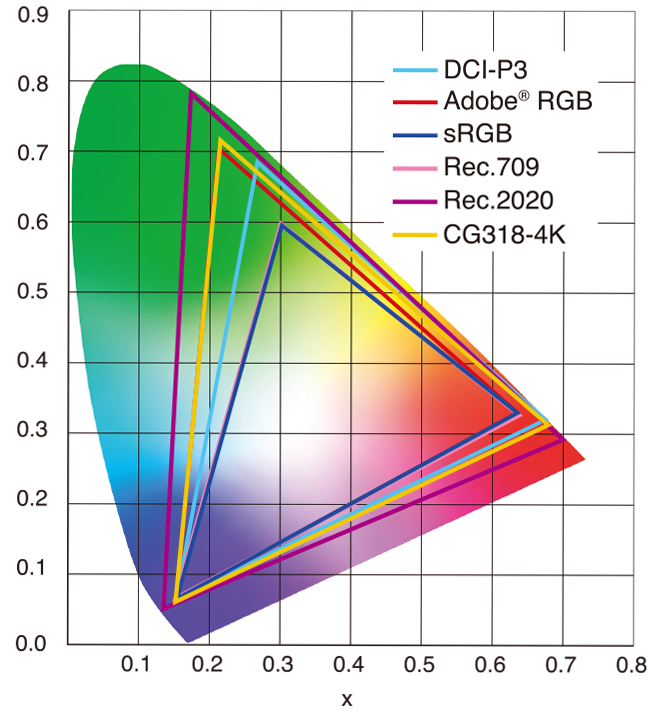
1. Basic Comparison
- What they are
- sRGB: A standard “web”/computer-display RGB color space defined by IEC 61966-2-1. It’s used for most monitors, cameras, printers, and the vast majority of images on the Internet.
- Rec. 709: An HD-video color space defined by ITU-R BT.709. It’s the go-to standard for HDTV broadcasts, Blu-ray discs, and professional video pipelines.
- Why they exist
- sRGB: Ensures consistent colors across different consumer devices (PCs, phones, webcams).
- Rec. 709: Ensures consistent colors across video production and playback chains (cameras → editing → broadcast → TV).
- What you’ll see
- On your desktop or phone, images tagged sRGB will look “right” without extra tweaking.
- On an HDTV or video-editing timeline, footage tagged Rec. 709 will display accurate contrast and hue on broadcast-grade monitors.
2. Digging Deeper
Feature sRGB Rec. 709 White point D65 (6504 K), same for both D65 (6504 K) Primaries (x,y) R: (0.640, 0.330) G: (0.300, 0.600) B: (0.150, 0.060) R: (0.640, 0.330) G: (0.300, 0.600) B: (0.150, 0.060) Gamut size Identical triangle on CIE 1931 chart Identical to sRGB Gamma / transfer Piecewise curve: approximate 2.2 with linear toe Pure power-law γ≈2.4 (often approximated as 2.2 in practice) Matrix coefficients N/A (pure RGB usage) Y = 0.2126 R + 0.7152 G + 0.0722 B (Rec. 709 matrix) Typical bit-depth 8-bit/channel (with 16-bit variants) 8-bit/channel (10-bit for professional video) Usage metadata Tagged as “sRGB” in image files (PNG, JPEG, etc.) Tagged as “bt709” in video containers (MP4, MOV) Color range Full-range RGB (0–255) Studio-range Y′CbCr (Y′ [16–235], Cb/Cr [16–240])
Why the Small Differences Matter
(more…) - What they are
-
VES Cinematic Color – Motion-Picture Color Management
Read more: VES Cinematic Color – Motion-Picture Color ManagementThis paper presents an introduction to the color pipelines behind modern feature-film visual-effects and animation.
Authored by Jeremy Selan, and reviewed by the members of the VES Technology Committee including Rob Bredow, Dan Candela, Nick Cannon, Paul Debevec, Ray Feeney, Andy Hendrickson, Gautham Krishnamurti, Sam Richards, Jordan Soles, and Sebastian Sylwan.
-
The Maya civilization and the color blue
Read more: The Maya civilization and the color blueMaya blue is a highly unusual pigment because it is a mix of organic indigo and an inorganic clay mineral called palygorskite.
Echoing the color of an azure sky, the indelible pigment was used to accentuate everything from ceramics to human sacrifices in the Late Preclassic period (300 B.C. to A.D. 300).
A team of researchers led by Dean Arnold, an adjunct curator of anthropology at the Field Museum in Chicago, determined that the key to Maya blue was actually a sacred incense called copal.
By heating the mixture of indigo, copal and palygorskite over a fire, the Maya produced the unique pigment, he reported at the time.
-
Scientists claim to have discovered ‘new colour’ no one has seen before: Olo
Read more: Scientists claim to have discovered ‘new colour’ no one has seen before: Olohttps://www.bbc.com/news/articles/clyq0n3em41o
By stimulating specific cells in the retina, the participants claim to have witnessed a blue-green colour that scientists have called “olo”, but some experts have said the existence of a new colour is “open to argument”.
The findings, published in the journal Science Advances on Friday, have been described by the study’s co-author, Prof Ren Ng from the University of California, as “remarkable”.

(A) System inputs. (i) Retina map of 103 cone cells preclassified by spectral type (7). (ii) Target visual percept (here, a video of a child, see movie S1 at 1:04). (iii) Infrared cellular-scale imaging of the retina with 60-frames-per-second rolling shutter. Fixational eye movement is visible over the three frames shown.
(B) System outputs. (iv) Real-time per-cone target activation levels to reproduce the target percept, computed by: extracting eye motion from the input video relative to the retina map; identifying the spectral type of every cone in the field of view; computing the per-cone activation the target percept would have produced. (v) Intensities of visible-wavelength 488-nm laser microdoses at each cone required to achieve its target activation level.
(C) Infrared imaging and visible-wavelength stimulation are physically accomplished in a raster scan across the retinal region using AOSLO. By modulating the visible-wavelength beam’s intensity, the laser microdoses shown in (v) are delivered. Drawing adapted with permission [Harmening and Sincich (54)].
(D) Examples of target percepts with corresponding cone activations and laser microdoses, ranging from colored squares to complex imagery. Teal-striped regions represent the color “olo” of stimulating only M cones.









LIGHTING
-
HDRI Median Cut plugin
Read more: HDRI Median Cut pluginwww.hdrlabs.com/picturenaut/plugins.html

Note. The Median Cut algorithm is typically used for color quantization, which involves reducing the number of colors in an image while preserving its visual quality. It doesn’t directly provide a way to identify the brightest areas in an image. However, if you’re interested in identifying the brightest areas, you might want to look into other methods like thresholding, histogram analysis, or edge detection, through openCV for example.
Here is an openCV example:
(more…) -
Custom bokeh in a raytraced DOF render
Read more: Custom bokeh in a raytraced DOF render

To achieve a custom pinhole camera effect with a custom bokeh in Arnold Raytracer, you can follow these steps:
- Set the render camera with a focal length around 50 (or as needed)
- Set the F-Stop to a high value (e.g., 22).
- Set the focus distance as you require
- Turn on DOF
- Place a plane a few cm in front of the camera.
- Texture the plane with a transparent shape at the center of it. (Transmission with no specular roughness)
-
Bella – Fast Spectral Rendering
Read more: Bella – Fast Spectral Rendering
Bella works in spectral space, allowing effects such as BSDF wavelength dependency, diffraction, or atmosphere to be modeled far more accurately than in color space.

https://superrendersfarm.com/blog/uncategorized/bella-a-new-spectral-physically-based-renderer/
-
Outpost VFX lighting tips
Read more: Outpost VFX lighting tipswww.outpost-vfx.com/en/news/18-pro-tips-and-tricks-for-lighting
Get as much information regarding your plate lighting as possible
- Always use a reference
- Replicate what is happening in real life
- Invest into a solid HDRI
- Start Simple
- Observe real world lighting, photography and cinematography
- Don’t neglect the theory
- Learn the difference between realism and photo-realism.
- Keep your scenes organised


















COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Methods for creating motion blur in Stop motion
-
AnimationXpress.com interviews Daniele Tosti for TheCgCareer.com channel
-
WhatDreamsCost Spline-Path-Control – Create motion controls for ComfyUI
-
VFX pipeline – Render Wall management topics
-
What Is The Resolution and view coverage Of The human Eye. And what distance is TV at best?
-
Tencent Hunyuan3D 2.1 goes Open Source and adds MV (Multi-view) and MV Mini
-
ComfyUI FLOAT – A container for FLOAT Generative Motion Latent Flow Matching for Audio-driven Talking Portrait – lip sync
-
Advanced Computer Vision with Python OpenCV and Mediapipe
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
