


COMPOSITION
















DESIGN
-
Kristina Kashtanova – “This is how GPT-4 sees and hears itself”
Read more: Kristina Kashtanova – “This is how GPT-4 sees and hears itself”“I used GPT-4 to describe itself. Then I used its description to generate an image, a video based on this image and a soundtrack.
Tools I used: GPT-4, Midjourney, Kaiber AI, Mubert, RunwayML
This is the description I used that GPT-4 had of itself as a prompt to text-to-image, image-to-video, and text-to-music. I put the video and sound together in RunwayML.
GPT-4 described itself as: “Imagine a sleek, metallic sphere with a smooth surface, representing the vast knowledge contained within the model. The sphere emits a soft, pulsating glow that shifts between various colors, symbolizing the dynamic nature of the AI as it processes information and generates responses. The sphere appears to float in a digital environment, surrounded by streams of data and code, reflecting the complex algorithms and computing power behind the AI”





















COLOR
-
FXGuide – ACES 2.0 with ILM’s Alex Fry
Read more: FXGuide – ACES 2.0 with ILM’s Alex Fry
https://draftdocs.acescentral.com/background/whats-new/
ACES 2.0 is the second major release of the components that make up the ACES system. The most significant change is a new suite of rendering transforms whose design was informed by collected feedback and requests from users of ACES 1. The changes aim to improve the appearance of perceived artifacts and to complete previously unfinished components of the system, resulting in a more complete, robust, and consistent product.
Highlights of the key changes in ACES 2.0 are as follows:
- New output transforms, including:
- A less aggressive tone scale
- More intuitive controls to create custom outputs to non-standard displays
- Robust gamut mapping to improve perceptual uniformity
- Improved performance of the inverse transforms
- Enhanced AMF specification
- An updated specification for ACES Transform IDs
- OpenEXR compression recommendations
- Enhanced tools for generating Input Transforms and recommended procedures for characterizing prosumer cameras
- Look Transform Library
- Expanded documentation
Rendering Transform
The most substantial change in ACES 2.0 is a complete redesign of the rendering transform.
ACES 2.0 was built as a unified system, rather than through piecemeal additions. Different deliverable outputs “match” better and making outputs to display setups other than the provided presets is intended to be user-driven. The rendering transforms are less likely to produce undesirable artifacts “out of the box”, which means less time can be spent fixing problematic images and more time making pictures look the way you want.
Key design goals
- Improve consistency of tone scale and provide an easy to use parameter to allow for outputs between preset dynamic ranges
- Minimize hue skews across exposure range in a region of same hue
- Unify for structural consistency across transform type
- Easy to use parameters to create outputs other than the presets
- Robust gamut mapping to improve harsh clipping artifacts
- Fill extents of output code value cube (where appropriate and expected)
- Invertible – not necessarily reversible, but Output > ACES > Output round-trip should be possible
- Accomplish all of the above while maintaining an acceptable “out-of-the box” rendering
- New output transforms, including:
-
“Reality” is constructed by your brain. Here’s what that means, and why it matters.
Read more: “Reality” is constructed by your brain. Here’s what that means, and why it matters.“Fix your gaze on the black dot on the left side of this image. But wait! Finish reading this paragraph first. As you gaze at the left dot, try to answer this question: In what direction is the object on the right moving? Is it drifting diagonally, or is it moving up and down?”

What color are these strawberries?

Are A and B the same gray?

-
Pattern generators
Read more: Pattern generatorshttp://qrohlf.com/trianglify-generator/
https://halftonepro.com/app/polygons#
https://mattdesl.svbtle.com/generative-art-with-nodejs-and-canvas
https://www.patterncooler.com/
http://permadi.com/java/spaint/spaint.html
https://dribbble.com/shots/1847313-Kaleidoscope-Generator-PSD
http://eskimoblood.github.io/gerstnerizer/
http://www.stripegenerator.com/
http://btmills.github.io/geopattern/geopattern.html
http://fractalarchitect.net/FA4-Random-Generator.html
https://sciencevsmagic.net/fractal/#0605,0000,3,2,0,1,2
https://sites.google.com/site/mandelbulber/home
-
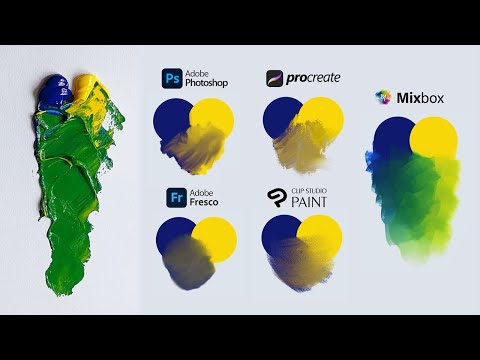
SecretWeapons MixBox – a practical library for paint-like digital color mixing
Read more: SecretWeapons MixBox – a practical library for paint-like digital color mixingInternally, Mixbox treats colors as real-life pigments using the Kubelka & Munk theory to predict realistic color behavior.
https://scrtwpns.com/mixbox/painter/
https://scrtwpns.com/mixbox.pdf
https://github.com/scrtwpns/mixbox
https://scrtwpns.com/mixbox/docs/













LIGHTING
-
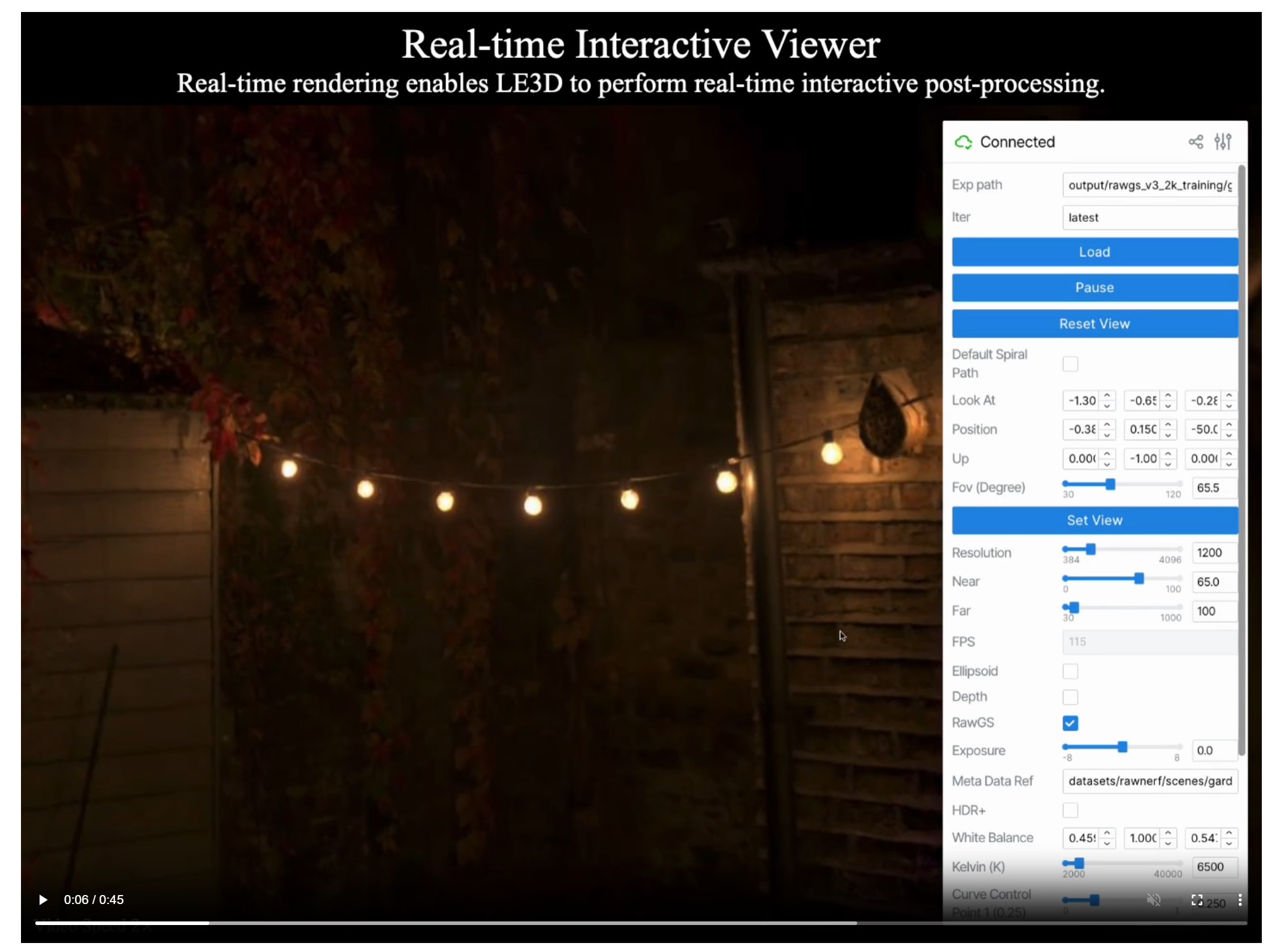
Lighting Every Darkness with 3DGS: Fast Training and Real-Time Rendering and Denoising for HDR View Synthesis
Read more: Lighting Every Darkness with 3DGS: Fast Training and Real-Time Rendering and Denoising for HDR View Synthesishttps://srameo.github.io/projects/le3d/
LE3D is a method for real-time HDR view synthesis from RAW images. It is particularly effective for nighttime scenes.
https://github.com/Srameo/LE3D

-
Debayer – A free command line tool to convert camera raw images into scene-linear exr
Read more: Debayer – A free command line tool to convert camera raw images into scene-linear exr
https://github.com/jedypod/debayer
The only required dependency is oiiotool. However other “debayer engines” are also supported.
- OpenImageIO – oiiotool is used for converting debayered tif images to exr.
- Debayer Engines
- RawTherapee – Powerful raw development software used to decode raw images. High quality, good selection of debayer algorithms, and more advanced raw processing like chromatic aberration removal.
- LibRaw – dcraw_emu commandline utility included with LibRaw. Optional alternative for debayer. Simple, fast and effective.
- Darktable – Uses darktable-cli plus an xmp config to process.
- vkdt – uses vkdt-cli to debayer. Pretty experimental still. Uses Vulkan for image processing. Stupidly fast. Pretty limited.
-
Black Body color aka the Planckian Locus curve for white point eye perception
Read more: Black Body color aka the Planckian Locus curve for white point eye perceptionhttp://en.wikipedia.org/wiki/Black-body_radiation

Black-body radiation is the type of electromagnetic radiation within or surrounding a body in thermodynamic equilibrium with its environment, or emitted by a black body (an opaque and non-reflective body) held at constant, uniform temperature. The radiation has a specific spectrum and intensity that depends only on the temperature of the body.
A black-body at room temperature appears black, as most of the energy it radiates is infra-red and cannot be perceived by the human eye. At higher temperatures, black bodies glow with increasing intensity and colors that range from dull red to blindingly brilliant blue-white as the temperature increases.
(more…) -
Magnific.ai Relight – change the entire lighting of a scene
Read more: Magnific.ai Relight – change the entire lighting of a scene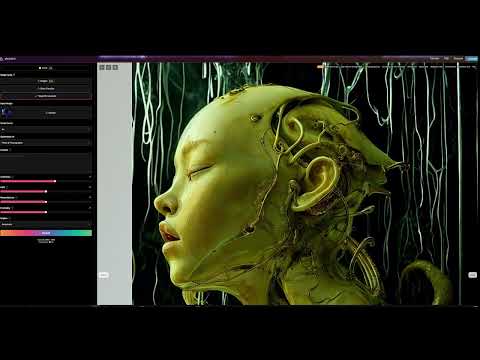
It’s a new Magnific spell that allows you to change the entire lighting of a scene and, optionally, the background with just:
1/ A prompt OR
2/ A reference image OR
3/ A light map (drawing your own lights)https://x.com/javilopen/status/1805274155065176489














COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
AnimationXpress.com interviews Daniele Tosti for TheCgCareer.com channel
-
Film Production walk-through – pipeline – I want to make a … movie
-
How does Stable Diffusion work?
-
JavaScript how-to free resources
-
Zibra.AI – Real-Time Volumetric Effects in Virtual Production. Now free for Indies!
-
sRGB vs REC709 – An introduction and FFmpeg implementations
-
59 AI Filmmaking Tools For Your Workflow
-
Methods for creating motion blur in Stop motion
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
