


COMPOSITION
-
HuggingFace ai-comic-factory – a FREE AI Comic Book Creator
Read more: HuggingFace ai-comic-factory – a FREE AI Comic Book Creatorhttps://huggingface.co/spaces/jbilcke-hf/ai-comic-factory

this is the epic story of a group of talented digital artists trying to overcame daily technical challenges to achieve incredibly photorealistic projects of monsters and aliens





DESIGN
COLOR
-
Mysterious animation wins best illusion of 2011 – Motion silencing illusion
Read more: Mysterious animation wins best illusion of 2011 – Motion silencing illusionThe 2011 Best Illusion of the Year uses motion to render color changes invisible, and so reveals a quirk in our visual systems that is new to scientists.
https://en.wikipedia.org/wiki/Motion_silencing_illusion
“It is a really beautiful effect, revealing something about how our visual system works that we didn’t know before,” said Daniel Simons, a professor at the University of Illinois, Champaign-Urbana. Simons studies visual cognition, and did not work on this illusion. Before its creation, scientists didn’t know that motion had this effect on perception, Simons said.
A viewer stares at a speck at the center of a ring of colored dots, which continuously change color. When the ring begins to rotate around the speck, the color changes appear to stop. But this is an illusion. For some reason, the motion causes our visual system to ignore the color changes. (You can, however, see the color changes if you follow the rotating circles with your eyes.)

-
What is OLED and what can it do for your TV
Read more: What is OLED and what can it do for your TVhttps://www.cnet.com/news/what-is-oled-and-what-can-it-do-for-your-tv/
OLED stands for Organic Light Emitting Diode. Each pixel in an OLED display is made of a material that glows when you jab it with electricity. Kind of like the heating elements in a toaster, but with less heat and better resolution. This effect is called electroluminescence, which is one of those delightful words that is big, but actually makes sense: “electro” for electricity, “lumin” for light and “escence” for, well, basically “essence.”
OLED TV marketing often claims “infinite” contrast ratios, and while that might sound like typical hyperbole, it’s one of the extremely rare instances where such claims are actually true. Since OLED can produce a perfect black, emitting no light whatsoever, its contrast ratio (expressed as the brightest white divided by the darkest black) is technically infinite.
OLED is the only technology capable of absolute blacks and extremely bright whites on a per-pixel basis. LCD definitely can’t do that, and even the vaunted, beloved, dearly departed plasma couldn’t do absolute blacks.

-
Anders Langlands – Render Color Spaces
Read more: Anders Langlands – Render Color Spaceshttps://www.colour-science.org/anders-langlands/
This page compares images rendered in Arnold using spectral rendering and different sets of colourspace primaries: Rec.709, Rec.2020, ACES and DCI-P3. The SPD data for the GretagMacbeth Color Checker are the measurements of Noburu Ohta, taken from Mansencal, Mauderer and Parsons (2014) colour-science.org.

-
Photography Basics : Spectral Sensitivity Estimation Without a Camera
Read more: Photography Basics : Spectral Sensitivity Estimation Without a Camerahttps://color-lab-eilat.github.io/Spectral-sensitivity-estimation-web/
A number of problems in computer vision and related fields would be mitigated if camera spectral sensitivities were known. As consumer cameras are not designed for high-precision visual tasks, manufacturers do not disclose spectral sensitivities. Their estimation requires a costly optical setup, which triggered researchers to come up with numerous indirect methods that aim to lower cost and complexity by using color targets. However, the use of color targets gives rise to new complications that make the estimation more difficult, and consequently, there currently exists no simple, low-cost, robust go-to method for spectral sensitivity estimation that non-specialized research labs can adopt. Furthermore, even if not limited by hardware or cost, researchers frequently work with imagery from multiple cameras that they do not have in their possession.
To provide a practical solution to this problem, we propose a framework for spectral sensitivity estimation that not only does not require any hardware (including a color target), but also does not require physical access to the camera itself. Similar to other work, we formulate an optimization problem that minimizes a two-term objective function: a camera-specific term from a system of equations, and a universal term that bounds the solution space.
Different than other work, we utilize publicly available high-quality calibration data to construct both terms. We use the colorimetric mapping matrices provided by the Adobe DNG Converter to formulate the camera-specific system of equations, and constrain the solutions using an autoencoder trained on a database of ground-truth curves. On average, we achieve reconstruction errors as low as those that can arise due to manufacturing imperfections between two copies of the same camera. We provide predicted sensitivities for more than 1,000 cameras that the Adobe DNG Converter currently supports, and discuss which tasks can become trivial when camera responses are available.
















LIGHTING
-
Unity 3D resources
Read more: Unity 3D resources
http://answers.unity3d.com/questions/12321/how-can-i-start-learning-unity-fast-list-of-tutori.html
If you have no previous experience with Unity, start with these six video tutorials which give a quick overview of the Unity interface and some important features http://unity3d.com/support/documentation/video/
-
Photography basics: Exposure Value vs Photographic Exposure vs Il/Luminance vs Pixel luminance measurements
Read more: Photography basics: Exposure Value vs Photographic Exposure vs Il/Luminance vs Pixel luminance measurementsAlso see: https://www.pixelsham.com/2015/05/16/how-aperture-shutter-speed-and-iso-affect-your-photos/
In photography, exposure value (EV) is a number that represents a combination of a camera’s shutter speed and f-number, such that all combinations that yield the same exposure have the same EV (for any fixed scene luminance).
The EV concept was developed in an attempt to simplify choosing among combinations of equivalent camera settings. Although all camera settings with the same EV nominally give the same exposure, they do not necessarily give the same picture. EV is also used to indicate an interval on the photographic exposure scale. 1 EV corresponding to a standard power-of-2 exposure step, commonly referred to as a stop
EV 0 corresponds to an exposure time of 1 sec and a relative aperture of f/1.0. If the EV is known, it can be used to select combinations of exposure time and f-number.Note EV does not equal to photographic exposure. Photographic Exposure is defined as how much light hits the camera’s sensor. It depends on the camera settings mainly aperture and shutter speed. Exposure value (known as EV) is a number that represents the exposure setting of the camera.
Thus, strictly, EV is not a measure of luminance (indirect or reflected exposure) or illuminance (incidentl exposure); rather, an EV corresponds to a luminance (or illuminance) for which a camera with a given ISO speed would use the indicated EV to obtain the nominally correct exposure. Nonetheless, it is common practice among photographic equipment manufacturers to express luminance in EV for ISO 100 speed, as when specifying metering range or autofocus sensitivity.
The exposure depends on two things: how much light gets through the lenses to the camera’s sensor and for how long the sensor is exposed. The former is a function of the aperture value while the latter is a function of the shutter speed. Exposure value is a number that represents this potential amount of light that could hit the sensor. It is important to understand that exposure value is a measure of how exposed the sensor is to light and not a measure of how much light actually hits the sensor. The exposure value is independent of how lit the scene is. For example a pair of aperture value and shutter speed represents the same exposure value both if the camera is used during a very bright day or during a dark night.
Each exposure value number represents all the possible shutter and aperture settings that result in the same exposure. Although the exposure value is the same for different combinations of aperture values and shutter speeds the resulting photo can be very different (the aperture controls the depth of field while shutter speed controls how much motion is captured).
EV 0.0 is defined as the exposure when setting the aperture to f-number 1.0 and the shutter speed to 1 second. All other exposure values are relative to that number. Exposure values are on a base two logarithmic scale. This means that every single step of EV – plus or minus 1 – represents the exposure (actual light that hits the sensor) being halved or doubled.Formulas
(more…) -
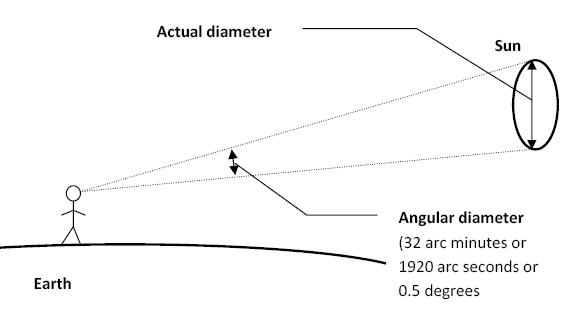
Sun cone angle (angular diameter) as perceived by earth viewers
Read more: Sun cone angle (angular diameter) as perceived by earth viewersAlso see:
https://www.pixelsham.com/2020/08/01/solid-angle-measures/
The cone angle of the sun refers to the angular diameter of the sun as observed from Earth, which is related to the apparent size of the sun in the sky.
The angular diameter of the sun, or the cone angle of the sunlight as perceived from Earth, is approximately 0.53 degrees on average. This value can vary slightly due to the elliptical nature of Earth’s orbit around the sun, but it generally stays within a narrow range.
Here’s a more precise breakdown:
-
- Average Angular Diameter: About 0.53 degrees (31 arcminutes)
- Minimum Angular Diameter: Approximately 0.52 degrees (when Earth is at aphelion, the farthest point from the sun)
- Maximum Angular Diameter: Approximately 0.54 degrees (when Earth is at perihelion, the closest point to the sun)
This angular diameter remains relatively constant throughout the day because the sun’s distance from Earth does not change significantly over a single day.
To summarize, the cone angle of the sun’s light, or its angular diameter, is typically around 0.53 degrees, regardless of the time of day.
https://en.wikipedia.org/wiki/Angular_diameter
-
-
Rec-2020 – TVs new color gamut standard used by Dolby Vision?
Read more: Rec-2020 – TVs new color gamut standard used by Dolby Vision?https://www.hdrsoft.com/resources/dri.html#bit-depth

The dynamic range is a ratio between the maximum and minimum values of a physical measurement. Its definition depends on what the dynamic range refers to.
For a scene: Dynamic range is the ratio between the brightest and darkest parts of the scene.
For a camera: Dynamic range is the ratio of saturation to noise. More specifically, the ratio of the intensity that just saturates the camera to the intensity that just lifts the camera response one standard deviation above camera noise.
For a display: Dynamic range is the ratio between the maximum and minimum intensities emitted from the screen.
The Dynamic Range of real-world scenes can be quite high — ratios of 100,000:1 are common in the natural world. An HDR (High Dynamic Range) image stores pixel values that span the whole tonal range of real-world scenes. Therefore, an HDR image is encoded in a format that allows the largest range of values, e.g. floating-point values stored with 32 bits per color channel. Another characteristics of an HDR image is that it stores linear values. This means that the value of a pixel from an HDR image is proportional to the amount of light measured by the camera.
For TVs HDR is great, but it’s not the only new TV feature worth discussing.
(more…)










COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
AI Data Laundering: How Academic and Nonprofit Researchers Shield Tech Companies from Accountability
-
Alejandro Villabón and Rafał Kaniewski – Recover Highlights With 8-Bit to High Dynamic Range Half Float Copycat – Nuke
-
AI Search – Find The Best AI Tools & Apps
-
UV maps
-
Key/Fill ratios and scene composition using false colors and Nuke node
-
59 AI Filmmaking Tools For Your Workflow
-
VFX pipeline – Render Wall management topics
-
QR code logos
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
